Chapter 4. Classes#
Objects and Classes#
An object is a data structure that contains state and behaviour.
Before we can create objects, we (usually) need to define a class which will be our template for creating objects. The objects which we create from that template are called instances of the class.
Consider the following example:
We have a ball which has a position and a speed. The position and the speed describe the state of the ball. The ball can also move, i.e. update its position based on the speed. This is the behaviour of the ball.
We can define a class Ball (which will be the template for creating ball objects in the future) like this:
class Ball:
def __init__(self, pos, speed):
self.pos = pos
self.speed = speed
Here the state consists of the variables pos and speed. Generally speaking, variables that are associated with objects (and represent its state) are called attributes.
PEP8 note: Class names should normally use the CapWords convention, e.g.
BallorMyAwesomeClass.
The __init__ function (commonly referred to as constructor) is a special function which initializes an object with some initial state.
For example if we want to create a ball with the position 10 and the speed 8, we write:
my_ball = Ball(10, 8)
Just like with functions, we can pass positional arguments and/or keyword arguments to the constructor:
my_ball = Ball(pos=10, speed=8)
Let us inspect the attributes of the ball object:
f"pos = {my_ball.pos}, speed = {my_ball.speed}"
'pos = 10, speed = 8'
We can also get the class of the object using the type function:
type(my_ball)
__main__.Ball
We can also confirm that the my_ball object is an instance of the Ball class using the isinstance function. This will come in handy later:
isinstance(my_ball, Ball)
True
We could now change the state of the ball directly. For example this is how we could move the ball:
t = 2
my_ball.pos += my_ball.speed * t
f"pos = {my_ball.pos}, speed = {my_ball.speed}"
'pos = 26, speed = 8'
But this isn’t really the way to go. What if we wanted to change the speed calculation later (for example taking friction into account)? Then we would need to adjust the calculation in every single place we use it, which is a lot of work and could introduce bugs if we forget the calculation adjustment somewhere.
If you paid attention in the previous chapter, you will quickly realize that we have the exact same problem that motivated the introduction of functions.
After we introduced functions, we stored the repetitive calculations in the function body and then simply called the function when we needed those calculations. Luckily, classes and objects provide a similar mechanism.
We can define functions on classes - these functions are called methods and define the behaviour of the objects of that class. The first parameter of every method is an instance of the current object. By convention this parameter is called self.
For example, here is how we could implement a move method on the Ball class:
class Ball:
def __init__(self, pos, speed):
self.pos = pos
self.speed = speed
def move(self, t):
self.pos += self.speed * t
Here, self will be the ball object the method is invoked on. For example if we call move on the object my_ball then self will be my_ball. If we call move on the object my_other_ball then self will be my_other_ball.
If you are working in the REPL, after creating the new class you need to recreate the my_ball object, otherwise you will still be using the old class!
my_ball = Ball(10, 8)
my_ball.move(2)
f"pos = {my_ball.pos}, speed = {my_ball.speed}"
'pos = 26, speed = 8'
If you see the error message AttributeError: 'Ball' object has no attribute 'move' this means that you are still using the old ball class and you need to recreate my_ball.
Note how executing the methods that defined the behaviour changed the object state. This is what objects are all about. They are initialized with some state and then we can use their behaviour to update the state.
We should also point out that apart from having to write classes yourself, you will use them all the time. In fact, we will introduce many extremely important classes in the very next chapter.
The __str__ and __repr__ Methods#
Quite often, we want to obtain a string representation of an object (e.g. using the print function) that shows its current state. Unfortunately, at the moment, if we try to print or get the representation of an object, we will receive a string that’s pretty useless.
my_ball
<__main__.Ball at 0x7fb37c76e6d0>
print(my_ball)
<__main__.Ball object at 0x7fb37c76e6d0>
The weird string at the end of the output (yours will probably be different) is the memory address of the object represented as a hexadecimal number (because we use the CPython runtime).
Luckily, Python allows us to change this behaviour. Classes may implement two special methods called __str__ and __repr__.
The __str__ method produces a human-readable string for consumption by the end user. The __repr__ method produces an unambiguous representation of the object. Basically __str__ is intended to produce an “informal” representation of an object, while __repr__ is intended to produce a formal representation of an object.
This is reflected in the circumstances under which these methods are called. For example if you just output an object in the REPL, you will see the output of a call to the __repr__ method of that object. If you print an object, you will see the result of a call to the __str__ method of that object.
This makes sense - in the REPL we generally want to see an unambiguous representation of our objects. On the other hand, when we call print we usually want a human-readable string that displays the information we primarily care about.
These two methods often have the same implementation (since the end user often wants to see the unambiguous representation), but this doesn’t have to be the case. For example, we could argue, that the end user doesn’t care about the speed of the ball and only cares about its current position. Then the __str__ method would return a string that doesn’t contain the speed attribute. However the __repr__ method should still return all attributes:
class Ball:
def __init__(self, pos, speed):
self.pos = pos
self.speed = speed
def move(self, t):
self.pos += self.speed * t
def __str__(self):
return f"Ball(pos={self.pos})"
def __repr__(self):
return f"Ball(pos={self.pos}, speed={self.speed})"
ball = Ball(pos=10, speed=8)
# Note how printing the ball gives us
# the output of __str__
print(ball)
Ball(pos=10)
# However just outputting the ball in a REPL
# gives us the output of __repr__
ball
Ball(pos=10, speed=8)
We can also call __str__ and __repr__ manually by calling the str and repr functions:
str(ball)
'Ball(pos=10)'
repr(ball)
'Ball(pos=10, speed=8)'
If __str__ and __repr__ should return the same string, it’s enough to just define __repr__. If no __str__ is defined and you try to call it, Python will fallback to calling __repr__:
class Ball:
def __init__(self, pos, speed):
self.pos = pos
self.speed = speed
def move(self, t):
self.pos += self.speed * t
def __repr__(self):
return f"Ball(pos={self.pos}, speed={self.speed})"
ball = Ball(pos=10, speed=8)
ball
Ball(pos=10, speed=8)
print(ball)
Ball(pos=10, speed=8)
Writing __repr__ for practically all your classes should be second nature for you from now on. Being able to see the state of an object when outputting it is absolutely vital when trying to spot bugs and attempting to understand what’s going on in your application.
Therefore whenever you define a class, add a __repr__ method which outputs a string that unambiguously represents the object it was called on. The best way to go about this is to return a string whose value represents the instantiation of a new object.
For instance, in the above example __repr__ returned a string with the value Ball(pos=10, speed=8). If we copy that value into our codebase, we would create a new Ball object with the exact same state as the object that produced this string:
Ball(pos=10, speed=8)
Ball(pos=10, speed=8)
Object Identity#
Let’s create two instances of the class Ball whose attributes have the same values:
ball1 = Ball(10, 8)
ball2 = Ball(10, 8)
ball1
Ball(pos=10, speed=8)
ball2
Ball(pos=10, speed=8)
Note that all the attributes of these two objects have the same values, but they are totally different objects:
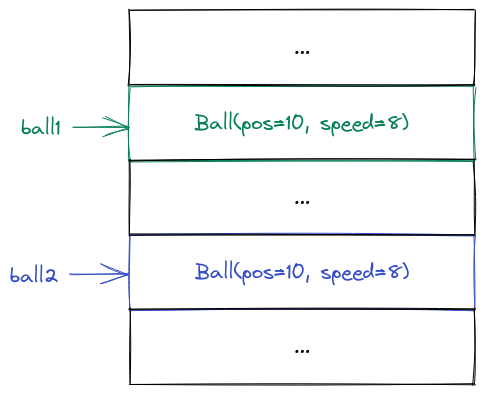
This means that if we change the values of ball1, then ball2 will be completely unaffected:
ball1.pos += ball1.speed * 2
The value of ball1.pos has now changed:
ball1
Ball(pos=26, speed=8)
However the value of ball2.pos is exactly the same as before:
ball2
Ball(pos=10, speed=8)
But what happens if we write this?
ball1 = Ball(10, 8)
ball2 = ball1
Now we have a completely different situation. The symbolic names ball1 and ball2 are still two different names, but they refer to the exact same object:
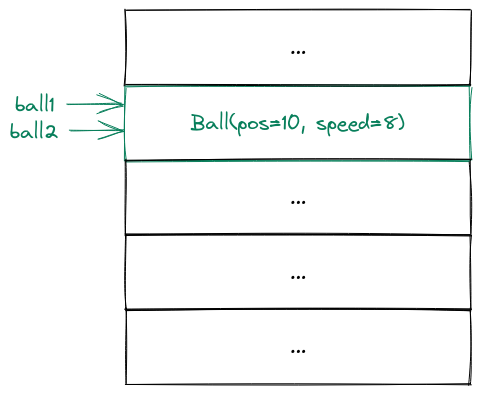
This means that whenever we make a change to that object using the name ball1, that change will be visible when we access the object using the name ball2. Consider this statement:
ball1.pos += ball1.speed
Outputting ball1 obviously shows the new value of pos:
ball1
Ball(pos=18, speed=8)
However, outputting ball2 also shows the new value of pos!
ball2
Ball(pos=18, speed=8)
We say that ball1 is ball2. These two names refer to the exact same object. Put differently, ball1 and ball2 have the same identity.
The is operator can be used to check if two names represent the same object:
ball1 is ball2
True
We can also see that ball1 and ball2 are the same object using the id function. Generally speaking, this function hands us a number that is unique for each object (for the lifetime of that object). In the Python interpreter we downloaded in chapter 1 (which is the CPython interpreter) this is achieved by returning the memory address of the object.
In this case ball1 and ball2 point to the same object, so their memory addresses are the same:
id(ball1)
140408864040944
id(ball2)
140408864040944
id(ball1) == id(ball2)
True
However, if we have two names that refer to different objects, then their memory addresses will not be the same and the is operator will return False even if the object attributes are all equal:
ball1 = Ball(10, 8)
ball2 = Ball(10, 8)
id(ball1)
140408864041232
id(ball2)
140408864040320
id(ball1) == id(ball2)
False
ball1 is ball2
False
Object Equality#
An interesting question is what happens if we use the equality operator == on objects. By default, the equality operator does the same thing as the is operator:
ball1 = Ball(10, 8)
ball2 = Ball(10, 8)
ball1 == ball2
False
ball1 = Ball(10, 8)
ball2 = ball1
ball1 == ball2
True
This is not particularly useful. After all, if two balls have the exact same position and the exact same speed, we would probably want them to be equal (even though the is operator returns False).
Luckily, Python gives us a way to achieve this by overriding (i.e. providing a custom implementation) for the equality operator. In order to do this, we need to write a custom __eq__ method which takes self and the other object we want to compare this object to:
class Ball:
def __init__(self, pos, speed):
self.pos = pos
self.speed = speed
# some methods
def __eq__(self, other):
return isinstance(other, Ball) and self.pos == other.pos and self.speed == other.speed
def __repr__(self):
return f"Ball(pos={self.pos}, speed={self.speed})"
Our __eq__ method checks that the other object is an instance of Ball and whether all attributes of self and other are equal. If they are, we return True, otherwise we return False.
Now the == operator works the way we would like it to:
ball1 = Ball(10, 8)
ball2 = Ball(10, 8)
ball1 == ball2
True
Note that how and if you want to override == depends on your needs. For example it might actually be the case, that two balls shouldn’t compare equal, even if their attributes have the same values.
But generally speaking, if you override the equality operator, you should override it by checking that the two objects it compares are instances of the same class and their attributes have the same values.