Getting Things Done In Next.js
by Mikhail Berkov
Introduction
— Sun Tzu
Long gone are the times when JavaScript was just a scripting language to add simple interactive behaviour to websites. The ECMAScript 2015 standard significantly improved the usability of the language. Excellent UI libraries like React allow you to write straightforward declarative code which massively simplifies building user interfaces. Thanks to Node.js you can write JavaScript on the server. Next.js empowers you to write complex APIs very quickly and PostgreSQL provides a relational database that fits right in with the other tools. The Next.js stack therefore allows you to quickly develop complex applications using just one language—JavaScript (with optional type hints via TypeScript).
This book serves as an introduction to the Next.js stack. However you don't learn software development by just reading books, you learn it by creating projects. We will therefore not bombard you with useless language trivia for hundreds of pages. If you care about that, go read the standard—it's pretty comprehensive. Instead we will create a real software project—an application for managing tasks called easy-opus (get it?). We will begin with nothing more than an empty project directory and the will to learn. We will end with a useful piece of software that allows us to create tasks, assign tasks to different users, update their statuses and much more.
This book is therefore inherently practical—unlike some other literature we will not dwell much on theoretical considerations. On the other hand, purely practical concerns are first-class citizens here (for example there is an entire chapter devoted to hosting your application). This doesn't mean that theory bad, practice good. It simply means that the approach for this particular book is heavily geared towards completing a real software project.
This book is therefore also not about becoming yet another JavaScript guru™ (there are already too many of them). It's about writing a useful product. It is fundamentally about getting things done. The Next.js stack is really just a tool we use to get things done.
This book is suitable for both beginners who want to pick up their first tech stack as well as for seasoned software developers looking to expand their knowledge.
This book is intended to be a standalone resource. While there are resources for further reading in each section, these are merely pointers if you want to dive deeper into a certain topic. You don't have to read them and you should be able to understand everything without reading them. In fact, if you are hard stuck in a certain place, this probably represents a failure on our part. Maybe we didn't explain an important concept well enough (or at all!). Don't hesitate to write an email to uhasker@protonmail.com or to create an issue at https://github.com/uhasker/getting-things-done-in-next-js explaining your problem.
Happy hacking
Mikhail Berkov
Chapter 1: A Brief Introduction to JavaScript
— Confucius
First we will need to go through the basics of the JavaScript language that we will use pretty much everywhere throughout this book. After all the Next.js stack is built on top of it.
You will set up your runtime, learn about variables, data types, operators and control flow. You will also learn how to write functions and how to think functionally. Thinking functionally will make you a better software developer and a better person. Isn't that great?
Let's dive right in!
Hello World
— Ancient Chinese proverb
Runtime Environments
Contrary to popular belief, code sadly doesn't run on pixie dust, magic spells, and unicorn tears. Instead, it runs on something called a runtime environment (also referred to as runtime system or just runtime). Put simply, a runtime is a program capable of executing code written in some programming language. It provides the environment in which programs can run. In order to execute all the awesome JavaScript code we're about to write, we therefore need a runtime first.
There are two runtimes capable of executing JavaScript code, which are relevant to this book—the browser and Node.js.
The browser, as well as the Node.js console, have REPL (read-eval-print-loop) capabilities. This allows you to type code directly into the console and execute it. REPLs are very nice because they allow you to quickly test new concepts.
Additionally, both runtimes can execute files containing JavaScript code. This is how we will usually utilize the runtimes—we write a script (a file containing JavaScript code) and tell our runtime to execute it.
As projects grow larger, we will often be dealing with multiple files at the same time. We will talk about this in the "Modules" section of this chapter.
Every runtime environment comes with a console. This isn't a retro gaming console; rather, it's a special part of the runtime where you can input commands and see the results of your code in real-time. Think of it as a conversation between you and the program—you tell it what to do (input commands) and it responds by executing those commands and showing you what happened (output).
In this section, we will set up the browser and Node.js runtimes. Then we will output (alternatively, "log" or "print") "Hello, World!" both to the browser console and the Node.js console to test that our setup functions as intended.
The Browser Environment
Open a browser, and open its console. How you do this will depend on the browser.
If you're using Firefox, the shortcut for opening the console is Ctrl + Shift + K on Ubuntu/Debian and Cmd + Option + K on macOS.
If you're using Chrome or Microsoft Edge, the shortcut is Ctrl + Shift + J on Ubuntu/Debian and Cmd + Option + J on macOS.
If you're using Safari on macOS, you will need to enable the develop menu first by going to Settings > Advanced and ticking the box Show Develop menu in menu bar.
Then you can open the console using Cmd + Option + K.
If you're using Internet Explorer, please navigate to
google.comand search for "Firefox" or "Chrome" to install a real browser. This line was originally intended to be a funny joke, but on June 15, 2022 Microsoft officially ended support for Internet Explorer, so it's not even a joke anymore.
This is approximately how the browser console will look like in Firefox:

Note that if you see a bunch of scary error or warning messages upon opening the console, don't panic (this is also good life advice in general). Most of these will probably come from various extensions you might have installed or the web page you are currently viewing. You can simply delete these messages, as we don't care about them.
Let's print something using the console.log method.
Type the following into the browser console:
console.log('Hello, World!');
Now hit Return (you may also know this as Enter or simply ⏎).
You will see the output Hello, World! in the console:

Ignore the
undefinedfor now.
Hooray, you've logged something to the browser console! This is the point at which you can go tell everyone that you are now a programmer™.
Executing JavaScript in the Browser
As we already mentioned, instead of executing JavaScript in the browser console directly, we can (and often will) execute it from a JavaScript file. Since we're on the browser, we will need to create two files—an HTML file and a JavaScript file.
HTML is short for HyperText Markup Language and is the standard markup language for documents that should be displayed in a browser. We will cover HTML in detail in a later chapter. For now we just want to create a very simple HTML document.
Here is how we can do this: Create a new file. We will call it hello.html. However, you can name it whatever you want. The filename should have an html extension though.
Open the HTML file in any text editor (see below for text editors that are good choices for coding) and add the following text to the file:
<!DOCTYPE html>
<html>
<head></head>
<body>
<script src="hello.js"></script>
</body>
</html>
Don't forget to save the file!
Now create another file called hello.js in the same directory as hello.html with the following content:
console.log('Hello, World!');
Note the semicolon after the
console.log—it terminates theconsole.logstatement. The semicolon is technically not required here and there are many JavaScript programmers who don't use semicolons. However, to avoid a bunch of pitfalls, we will use semicolons throughout this book and therefore we want you to get accustomed to them as soon as possible.
Now open this file in your browser by simply double-clicking the file.
After opening this file in your browser, open the console.
You should see the output Hello, World!.
Congratulations, you wrote your first script!
Working With a Command Line
Now that we know how to use the browser runtime, we will move on to Node.js. Before we can do that, we will need to learn how to interact with the command-line interface (also called command line, command prompt or CLI) on your computer. A command line allows you to execute various tasks called commands.
If you're on Ubuntu, you can open the command line by pressing Ctrl + Alt + T.
If you're on macOS, you can open the command line by pressing Cmd + Space to open search, typing terminal and then hitting Return.
Now that you've opened a CLI, you can type a command and hit Return to execute it. Try executing this command for starters:
echo 'Hello, World!'
Generally, whenever we tell you to execute a command you need to type it in the CLI and hit Return. Therefore, we will omit saying that you need to hit Return from now on.
The Node.js Runtime
For a long time, JavaScript was mostly used inside the browser runtime environment by programmers. However, in 2009, Node.js came along and changed that by allowing programmers to easily run JavaScript outside the browser.
Node.js will probably not be installed on your machine, so let's fix that. First, we have to install the Node Version Manager (nvm for short) which will allow us to manage Node.js versions in a simple and straightforward manner.
If you're on Ubuntu/Debian, you will need to run the following:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bash
source ~/.bashrc
If you're on macOS, you will need to run the following:
curl -fsSL https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | zsh
source ~/.zshrc
Check that nvm was successfully installed:
nvm --version
Finally, we will install Node.js (version 18):
nvm install 18
Verify that Node.js was successfully installed:
node --version
The installation script also automatically installed the node package manager (npm for short) which is a tool for managing dependencies in our projects.
Verify that npm was installed as well:
npm --version
Throughout this book we will use another package manager called pnpm, so let's install that too:
npm install -g pnpm
The
-gflag tellsnpmto install the package globally and not just for a particular project.
Verify that pnpm was installed:
pnpm --version
Now that Node.js is installed, you can open a Node.js console by typing node in the command line.
We can now output Hello, World! to the Node.js console using the console.log method.
Type the following into the console and hit Return:
console.log('Hello, World!');
You should see the output Hello, World!.
To exit the Node.js console, simply type .exit.
Executing a JavaScript File
We can also use Node.js to execute a JavaScript file.
Let's execute the hello.js we created earlier.
As a reminder, this file has the following content:
console.log('Hello, World!');
Open a command line again and change the current directory location to the directory containing the JavaScript file.
You can do so using the cd command.
For example, if hello.js is located at /home/users/user you would execute the following:
cd /home/users/user
Now execute the JavaScript file by running:
node hello.js
This should again print Hello, World!.
Note that for the remainder of this chapter you should follow along using the Node.js console. Nevertheless, as we dive further into the Next.js stack, we will have to write JavaScript for the browser runtime environment on a regular basis.
The Browser vs Node.js
We managed to execute some JavaScript on the browser and some JavaScript in Node.js. Right now, these two runtime environments don't look too different because we've only logged something to the console. However, in later sections you will learn that it's in fact extremely important which runtime you're on.
For example, in Node.js you can't access your browser window (which makes sense since there is no browser window). On the other hand, if you're in the browser you can't write files to the computer (to protect users from malicious websites). Often, people say that JavaScript code can be executed on the client (in the browser) or on the server (usually using Node.js).
Remember this point, since it will become extremely important later.
Editors
In the previous paragraphs you had to create a few files containing code. It should not come as a surprise that you will have to do this quite often throughout your programming journey. You should therefore select a good editor that has features such as syntax highlighting, autocompletion etc.
Coding in Notepad is in fact not a good idea.
If you're a complete beginner, the Visual Studio Code editor is often an excellent first choice.
Statements and Expressions
Before we dive into JavaScript, you should know that programs are made of statements and expressions.
A statement is a syntactic unit responsible for executing some action.
A program is then essentially a sequence of statements which should be executed when running the program.
For example, console.log('Hello, World!') is a statement which executes the action of logging Hello, World! to the console.
An expression is a syntactic unit that may be evaluated to get its value.
For example, 2 + 2 would be an expression which would evaluate to 4.
You could put it this way: Statements are executed to make something happen, while expressions are evaluated to produce a value.
Note that other authors might define statements and expressions in a slightly different manner (which is totally fine). However, we will stick to these definitions throughout this book.
Comments
Everything that comes after a double slash on a line is a comment in JavaScript. Comments are ignored by the runtime and therefore have no effect on the execution of your program:
// This is just a comment
// Comments have no effect
console.log('Hello, World!');
// Therefore this program is equivalent to the
// program from the previous chapter
We will heavily utilize comments throughout this book inside our code blocks to highlight important ideas.
There is a lot of discussion in the programming community on how much you should comment your programs. We will return to this when discussing functions. However, one rule is that if your code is so terrible that it requires extensive commentary to explain its behavior or purpose, you should fix the code. Just like a work of art, your code should stand on its own merits. Imagine commenting a work of art (oh, wait)... However, it's better to have terrible code and comments than have terrible code and no comments. And, of course, if your code does something particularly complicated, throwing in a comment might be a good idea.
We will also adopt the convention that if a comment is next to a line with a console.log statement, that comment shows the output that would be logged to the console if the code was executed.
For example:
console.log('Hello, World!'); // Hello, World!
This is the point where we tell you that while you're reading this book you should absolutely follow along in some runtime (probably Node.js, but a browser is fine too). This is very important. Go ahead and open a Node.js console now.
Come on, we will wait...
Waiting...
Waiting...
Waiting...
Finally.
Additionally, you should absolutely type the code yourself and not copy and paste it. If you just copy and paste the code, you will learn absolutely nothing and may as well not read this book at all.
Primitive Data Types
=== is the one and true equality operator
==== is the equality operator which transcends time and space
===== is the equality operator which transcends all other equality operators
====== is the equality operator which summons the UNSPEAKABLE DOOM (all is lost)
— from "The Book of the Equality Operators and their Virtue" by Laozi
Variables
Whenever we write programs, we need to manipulate data. This data needs to be stored somewhere and we need to be able to access it somehow.
We also need to deal with the fact that when we execute a program, the values we deal with are not predictable in advance.
For example, we don't know which tasks a user might create (that's kind of the point of writing our application after all).
Nevertheless, we must be able to access created tasks through a predictable name like tasks or createdTasks.
Therefore, we need a way to put an unpredictable value somewhere and refer to it using a predictable name. In programming, that "somewhere" is referred to as storage and the predictable name as a symbolic name.
A variable is just that—a storage location containing a value which is referred to by a symbolic name. This sounds really fancy, but it just means that there is a value somewhere in your storage and you can refer to that value using a symbolic name that doesn't change (even if the value itself changes).
For example, you could have a variable age which has the value 20 (we say that age is equal to 20):
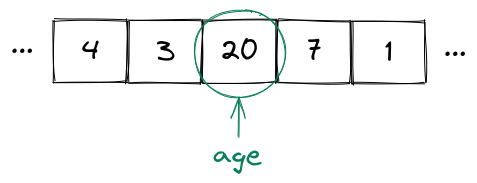
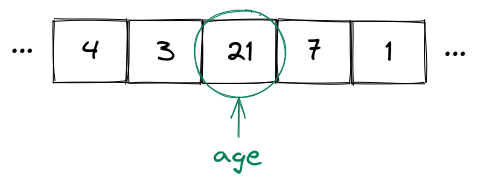
Now even if the value of age changes (e.g. to 21 because a birthday happened), the variable name doesn't change, only the value does.
The variable name will still be age.
However, age will now have the value 21 (i.e. age will be equal to 21):
JavaScript lets you declare variables using the let keyword.
You can assign values to variables with the assignment operator (=):
// Declare a variable
let x;
// Assign a value to a variable
x = 10;
You can print the value of the variable using the console.log method:
console.log(x); // 10
If you follow along in the Node.js (or browser) console, you don't actually need to use the
console.logmethod to print the value of a variable. Instead, you can simply type the variable (or any expression for that matter) and the console will display its value. For example, you can simply typexinstead ofconsole.log(x)and you will see the value ofx.
You can also have a declaration and an assignment on a single line. In fact, this is usually the way to go:
let y = 10;
The value of a variable may change over the course of a program:
let y = 10;
console.log(y); // 10
// Assign a new value to the variable
y = 20;
console.log(y); // 20
This will output 10, followed by a 20.
Remember that, according to our book conventions, a comment after a
console.logindicates the value that will be logged.
If you want to declare a predictable name for a value that never changes, you can declare a constant.
This is done using the const keyword:
const ten = 10;
If you try to reassign a value to a constant, you will get an error. For example, let's declare a constant and try to assign a new value to it:
const ten = 10;
ten = 20;
You will get the following error:
Uncaught TypeError: Assignment to constant variable.
You will almost exclusively see us using const instead of let from now on.
Reassignment is not nearly as necessary as you might think right now.
You can also declare variables using the
varkeyword. We will not cover it here and you essentially only need to know one thing aboutvar—you should basically never use it. That's becausevarhas really weird behaviour around scopes (we will talk about scopes later). For all practical purposes, you can treatvaras a historical artifact of JavaScript.
Any variable has a data type which denotes the range of values it can take and which operations can be performed on the variable.
You can use the typeof operator to obtain the data type of a variable.
We begin with a few particularly important primitive data types.
These are numbers, booleans, strings and undefined.
Numbers
You've already encountered the number data type:
const age = 20;
console.log(typeof age); // number
Any integer or real number is a number:
console.log(typeof 42); // number
console.log(typeof -20); // number
console.log(typeof 3.4); // number
console.log(typeof -1.7); // number
You can perform arithmetic on numbers using the usual arithmetic operators +, -, * and /.
There is also the % (modulo) operator which returns the remainder of a division.
Finally, there is the ** operator which does exponentiation:
const a = 3;
const b = 4;
console.log(a + b); // 7
console.log(a - b); // -1
console.log(a * b); // 12
console.log(a / b); // 0.75
console.log(a % b); // 3
console.log(a ** b); // 81
You can also use the shorthand assignment operators to combine assignment and arithmetic operators:
let a = 3;
a += 4;
console.log(a); // 7
a -= 2;
console.log(a); // 5
a *= 3;
console.log(a); // 15
a /= 3;
console.log(a); // 5
a %= 3;
console.log(a); // 2
a **= 5;
console.log(a); // 32
You also use the postfix increment and the postfix decrement operators to increment or decrement a value by 1:
let a = 4;
a++;
console.log(a); // 5
a--;
console.log(a); // 4
So far, so obvious.
However, there are also some other things which have the number type.
One of them is Infinity.
Infinity is a special value that represents—well—mathematical infinity:
console.log(typeof Infinity); // number
One way to arrive at Infinity in JavaScript is to divide something positive by 0:
console.log(1 / 0); // Infinity
Additionally, there is a special value called NaN (short for "not a number").
For example, the result of 0 / 0 is NaN:
console.log(0 / 0); // NaN
Hilariously, NaN itself is a number (despite its name explicitly stating that it's not a number):
console.log(typeof NaN); // number
Don't let that confuse you.
We will not debate whether decisions like
1/0being equal toInfinity,0/0being equal toNaNorNaNhaving typenumberare good decisions. We simply note that this is the way JavaScript works and move on. Don't worry, there is in fact a lot of hot debate around some of JavaScripts more—shall we say—controversial features. If you wish to do so, you can go on any programming forum of your choice and start a local holy war by making fun of the way JavaScript's primitive data types work. Deciding whether that's a good use of time is up to you.
Another important thing about numbers is that you need to be careful when you are trying to perform operations with real numbers.
For example, if you add 0.1 and 0.2 you get a weird result:
console.log(0.1 + 0.2); // 0.30000000000000004
This is not the fault of JavaScript, but instead has to do with the limitations of trying to represent numbers with a potentially infinite amount of digits on a finite hardware.
We will not go into great detail in this book about this problem. If you're interested in more details we encourage you to have a look at the IEEE754 standard.
Booleans
Another primitive type is the boolean type.
This allows you to represent values which are either true or false:
const thisBookIsAwesome = true;
const thisBookSucks = false;
console.log(typeof thisBookIsAwesome); // boolean
console.log(typeof thisBookSucks); // boolean
You can do simple logic using the logical operators && (which denotes and), || (which denotes or) and ! (which denotes not).
The && (and) operator takes two values and evaluates to true only if both values are true.
Otherwise, it evaluates to false:
console.log(true && true); // true
console.log(false && true); // false
console.log(true && false); // false
console.log(false && false); // false
The || (or) operator takes two values and evaluates to true if at least one of the values is true.
Otherwise, it evaluates to false:
console.log(true || true); // true
console.log(false || true); // true
console.log(true || false); // true
console.log(false || false); // false
The ! (not) operator takes a single value and simply negates it, i.e. "switches" a value to its opposite:
console.log(!true); // false
console.log(!false); // true
Here is an example with all the operators together:
const b1 = true;
const b2 = false;
console.log(b1 && b2); // false
console.log(b1 || b2); // true
console.log(!b1); // false
Note that, technically, the logical operators can work with any values (not just boolean values). The result of the logical operator application is then dependent on whether the values are truthy or falsy. We will discuss this later.
A boolean variable usually occurs as the result of an expression.
Often it's the result of an expression containing the strict equality operator (===) which allows us to compare the values of variables:
const x1 = 5;
const x2 = 10;
const x3 = 5;
console.log(x1 === x1); // true
console.log(x1 === x2); // false
console.log(x1 === x3); // true
There is also another equality operator (
==) which performs various type coercions before doing the equality comparison (for example,0 == "0"will betrue). This operator can be best described as an April Fools' joke that somehow made it into the language. Never use it.
If you want to write not equals, you can use !==:
console.log(5 !== 10); // true
console.log(5 !== 5); // false
Additionally, you can check if one value is less than or greater than another value using <, <=, > and >=.
These operators are most commonly used with numbers:
console.log(2 < 3); // true
console.log(2 <= 3); // true
console.log(2 > 3); // false
console.log(2 >= 3); // false
Strings
Another primitive data type is the string type.
A string is simply a sequence of characters and is used to represent text.
Strings are usually written using single quotes in JavaScript:
const s = 'Some text';
console.log(typeof s); // string
Note that it's also possible to write strings using double quotes, however in most projects strings are written using single quotes and we will stick to this convention. Nevertheless, we want to stress that there is absolutely nothing wrong to use double quotes. However, you should be consistent throughout your project—pick one style and stick to it.
The + operator works on strings and does concatenation:
const s1 = 'Next.js ';
const s2 = 'book';
console.log(s1 + s2); // Next.js book
Note that instead of doing concatenation all the time you can also use template strings (also called template literals). This allows writing JavaScript expressions directly inside strings. Consider the following example:
const s = 'World';
const greeting = `Hello, ${s}!`;
console.log(greeting); // Hello, World!
Template strings are written using backticks (not single quotes).
They may contain so-called placeholders which are expressions embedded inside ${...}:
console.log(`2 + 2 = ${2 + 2}`); // 2 + 2 = 4
Technically, expressions inside template literals have to be "implicitly convertible to a string" because JavaScript has to convert any placeholder value to a string first. However, you will find that expressions not "implicitly convertible to a string" are rare indeed.
You can get the length (i.e. the number of characters) of a string like this:
const s = 'MERN book';
console.log(s.length); // 9
Note that JavaScript does not have a special "character" data type (unlike Java for example). Instead, characters are simply strings of length 1:
const c = 'm';
console.log(typeof c); // string
There is much more to strings and we will return to them later.
In fact, strings are a really complicated data type. We will omit most of these complications since they are not relevant to simple web applications. Nevertheless, you should keep in mind that you will not have a perfectly accurate understanding of strings by the end of this book.
Undefined
Finally, there is one more primitive type that's of interest to us, namely undefined.
There is only one value of this type: undefined.
If a variable has the value undefined, this (quite logically) means that it hasn't been defined.
For example, whenever you have a variable that has been initialized, but not assigned to, it will automatically have the value and therefore the type undefined.
let someVariable;
console.log(someVariable); // undefined
console.log(typeof someVariable); // undefined
You can also manually assign the undefined value to a variable:
let someVariable = undefined;
console.log(someVariable); // undefined
console.log(typeof someVariable); // undefined
An important operator to know if you plan to work with undefined is the nullish coalescing operator ??.
This operator takes two values and checks if the left-hand side is undefined (or null—a value that we will not pay much attention to).
If the left value is undefined (or null), the nullish coalescing operator evaluates the expression to the right-hand side, otherwise it returns the left-hand side:
console.log(undefined ?? 1); // 1
console.log(0 ?? 1); // 0
The ?? operator is commonly used to provide useful default values.
Note that
string,number,booleanandundefinedare not the only primitive data types. However, the other primitive data types will not be relevant for this book.
Arrays and Objects
— Confucius
Arrays
Let's say you're writing a task application and you need to store a bunch of tasks. You could declare a separate variable for every task like this:
const task1 = 'First task';
const task2 = 'Second task';
const task3 = 'Third task';
However, this would quickly become very tedious. Additionally, you probably want to be able to add or delete tasks in your application. Adding and deleting variables will become even more tedious. It would become almost as tedious as repeating the word tedious over and over. Did we mention that this is really tedious?
As you can see, we need a way to store multiple values in a single variable. We can do this with arrays.
A JavaScript array is an ordered collection of multiple values. You can declare an array using an array literal (also called an array initializer in this context):
const tasks = ['First task', 'Second task', 'Third task'];
Note that an array is no longer a primitive type.
Instead, arrays have the type object:
console.log(typeof tasks); // object
You can access individual elements of an array using the index notation.
This works by writing the name of the array, followed by the position of the element you want to retrieve inside square brackets [].
Note that when we count the indices (positions), we start at 0, not at 1:
console.log(tasks[0]); // First task
console.log(tasks[1]); // Second task
If the array index is too big, trying to access the element at that index will return undefined:
console.log(tasks[3]); // undefined
You can get the length of an array using .length:
console.log(tasks.length); // 3
JavaScript has elegant syntax for working with arrays. For example, if you want to assign variables based on values of an array, you would normally have to do something like this:
const firstTask = tasks[0];
const secondTask = tasks[1];
const thirdTask = tasks[2];
This is (you guessed it) tedious.
Instead, you can use the array destructuring assignment:
const [firstTask, secondTask, thirdTask] = tasks;
console.log(secondTask); // Second task
If you only care about some of the elements, you can use the spread (...) syntax:
const [firstTask, ...otherTasks] = tasks;
Something that commonly trips up beginners is trying to copy an array.
Let's say you have an array of numbers called arr and you want to create a copy called arr2.
You would probably try something like this:
const arr = [1, 2, 3, 4];
const arr2 = arr;
This is wrong.
We can see that this is wrong if we try to change the first element of arr and then have a look at arr[0] and arr2[0]:
arr[0] = 5;
console.log(arr[0]); // 5
console.log(arr2[0]); // 5
Uh-oh!
That's probably not what we want.
The reason for this behaviour is that arr and arr2 both point to the same array.
Remember how we were careful to introduce a variable as a storage location together with a symbolic name?
Well, it turns out that different symbolic names may refer to the exact same storage location.
You can visualize it like this:
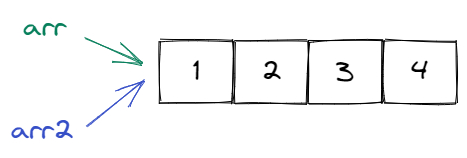
Here we have a storage location containing the values 1, 2, 3 and 4 somewhere.
We also have two symbolic names arr and arr2.
While the symbolic names are different, they point to the same storage location.
Therefore, if we change the storage location, we will observe a change via both symbolic names.
In order to actually copy the values, we can use the spread syntax again:
const copied = [...arr];
Let's check that this is indeed an actual copy:
arr[0] = 5;
console.log(arr[0]); // 5
console.log(copied[0]); // 1
This looks good. Here is the mental picture you should have in your head for copying an array:
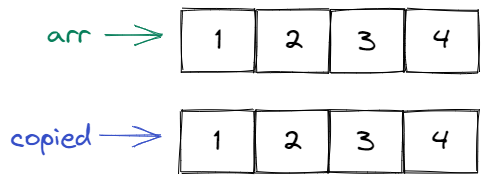
If you only briefly skimmed the section on array destructuring and the spread syntax, go back again and read it carefully. These two concepts will come up a lot in the following chapters (much more often than you think right now).
Objects
Let's return to our imaginary (as of now) task application. A task will probably be something more than just a string. For example, it might contain an ID, a title and a description. We could, again, try to store these values in separate constants:
const taskId = 1;
const taskTitle = 'Read the Next.js book';
const taskDescription = 'Read and understand the Next.js book.';
As you can probably guess, this will quickly become tedious (oh no, not this again).
Objects to the rescue!
These allow us to store name-value pairs inside a single variable.
Here is how we might create a task object that contains all the information we want to know about a task:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
Every such name-value pair is called a property.
We can access properties using the dot notation . or the square bracket notation [].
For example, we can access the title property of the task object by writing task.title or task['title'].
Try it out:
console.log(task.id); // 1
console.log(task.title); // Read the Next.js book
console.log(task.description); // Read and understand the Next.js book.
console.log(task['id']); // 1
console.log(task['title']); // Read the Next.js book
console.log(task['description']); // Read and understand the Next.js book.
Note that we will practically always use the dot notation.
Remember how you accessed the length of an array using arr.length?
You can do that because every array has a property called length that indicates the length of that array.
Properties don't have to be primitive values. They can also be other objects.
Generally speaking, you can arbitrarily nest objects and arrays. For example, here is how you can nest an object inside an object:
const user = {
name: 'John Doe',
task: {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
},
};
You can access the title property of the user.task object like this:
console.log(user.task.title); // Read the Next.js book
If you try to access a property that doesn't exist, the result will be undefined:
console.log(task.date); // undefined
Sometimes you want to explicitly indicate that a property may be absent. For example, a person may not have a task assigned to them. You can write something like this:
const person = {
name: 'John Doe',
task: undefined,
};
Instead of undefined you can also null which represents the absence of an object value.
Note that there is no separate null data type.
Instead, null is just a special object:
console.log(typeof null); // object
Here is how you can use null to represent the absence of a property:
const person = {
name: 'John Doe',
task: null,
};
Whether to use undefined or null in this situation is largely convention.
Throughout this book we will always use undefined.
Nevertheless, we want to emphasize that it's totally fine to use null instead of undefined in this situation.
Just pick a style and be consistent.
You can use the destructuring assignment when working with objects. This is similar to arrays:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
const { id, title, description } = task;
And just as with arrays, you can use the spread syntax with objects:
const taskWithAssignee = {
assignee: 'John Doe',
...task,
};
console.log(taskWithAssignee);
This will output:
{
assignee: 'John Doe',
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.'
}
Note that objects are more than just containers for values. We will return to this later.
Using const with Arrays and Objects
There is often some confusion regarding the use of const with arrays and objects.
For example, it seems strange that you can change the elements of a const array:
const arr = [1];
arr[0] = 2; // Totally valid
arr.push(3); // Totally valid
It seems equally strange that you can change the properties of a const object:
const obj = { prop: 1 };
obj.prop = 2; // Totally valid
Such assignments are possible because const only applies to the constant itself, not to the contents of the constant.
This means that the only thing you can't do is to change what the constant is pointing to altogether.
For instance, this is not possible:
const arr = [1];
arr = [2, 3]; // Not valid
Similarly, this is also not possible:
const obj = { prop: 1 };
obj = { prop: 2 }; // Not valid
This means that const is a pretty weak guarantee when working with arrays and objects.
After all, you often change elements of arrays and objects, but rarely change what the array and/or object is pointing to in its entirety.
Nevertheless, you should use const even when working with arrays and objects.
A weak guarantee is better than no guarantee at all.
Control Flow
— Ancient Chinese proverb
If Statements
Quite often, we need to make decisions in our programs.
Let's say we want to display a fancy message when a bunch of tasks are completed.
This is a decision: If all the tasks are completed, then we want to display a message.
More generally: If a condition holds (is true), then we want to do something.
Conveniently, the language keyword that allows us to accomplish this is called if:
const completed = true;
if (completed) {
console.log('Hooray, you completed all your tasks!');
}
This would print:
Hooray, you completed all your tasks!
The general form of an if statement looks like this:
if (condition) {
statements;
}
If condition is true, then the statements inside the curly braces will be executed.
If condition is false, nothing will happen.
Note that technically it suffices if the condition is truthy or falsy. We will ignore this detail for now and return to it later.
The simplest condition is a boolean variable.
However, nothing prevents us from writing more complex conditions.
For example, let's say we have a list of uncompleted tasks (conveniently) named tasks.
Then we could check that all tasks have been completed by checking whether tasks is empty (i.e. the length of tasks is zero):
if (tasks.length === 0) {
console.log('Hooray, you completed all your tasks!');
}
Sometimes you need to do something in one case and something else in another case.
The (also conveniently named) else keyword allows you to accomplish exactly that:
if (tasks.length === 0) {
console.log('Hooray, you completed all your tasks!');
} else {
console.log('You still have some tasks to complete.');
}
The general form of an if...else statement looks like this:
if (condition) {
statements1;
} else {
statements2;
}
If condition is true, the statements corresponding to statements1 will be executed (i.e. the statements inside the curly braces after the if).
If condition is false, the statements corresponding to statements2 will be executed (i.e. the statements inside the curly braces after the else).
Note that there may be multiple statements between the curly braces. For example, this is totally valid:
if (tasks.length === 0) {
console.log('Hooray, you completed all your tasks!');
console.log('Congratulations!');
console.log('No really, you are amazing!');
} else {
console.log('You still have some tasks to complete.');
console.log("Don't despair!");
}
Assuming tasks has a length of 0 this will print:
Hooray, you completed all your tasks!
Congratulations!
No really, you are amazing!
Sometimes you need to handle more than two cases.
Since JavaScript was fresh out of keywords at this point, they allowed you to do so using else if:
if (tasks.length === 0) {
console.log('Hooray, you completed all your tasks!');
} else if (tasks.length === 1) {
console.log('Only one task left! Go! Go! Go!');
} else {
console.log('You still have some tasks to complete.');
}
The general form of an if...else if...else statement looks like this:
if (condition1) {
statements1;
} else if (condition2) {
statements2;
} /*possibly more else ifs*/ else if (conditionN) {
statementsN;
} else {
statementsElse;
}
Here all the conditions will be checked one after another.
As soon as a condition is true, the corresponding statements will be executed.
If no condition matches, the statements corresponding to statementsElse will be executed.
You can have any number of else if statements.
For example, this is valid:
if (tasks.length === 0) {
console.log('Hooray, you completed all your tasks!');
} else if (tasks.length === 1) {
console.log('Only one task left! Go! Go! Go!');
} else if (tasks.length === 2) {
console.log('You have two tasks to do.');
} else if (tasks.length === 3) {
console.log('There are three tasks left.');
} else {
console.log('You still have some tasks to complete.');
}
Note that the else block is not required.
If it's missing and none of the conditions are true, nothing will happen.
Truthiness and Falsiness
The condition doesn't necessarily have to be a boolean as JavaScript will automatically evaluate non-boolean values as "truthy" or "falsy" in boolean contexts. For example, you could write something like this:
if (1) {
console.log('1 is truthy');
} else {
console.log('1 is falsy');
}
This will print 1 is truthy because JavaScript will consider 1 to be true in this context since 1 is a truthy value.
Generally speaking, a truthy value is considered to be true when encountered in a boolean context (like a condition). A falsy value is considered to be false when encountered in a boolean context.
The most important falsy values are false, 0, '' (empty string), null and undefined.
Most other values (like 1, [] (empty array), [3], { example: 'hello' } etc) are truthy.
Try to avoid using non-boolean values in boolean contexts as it can lead to surprising behaviour. Nevertheless it's still useful to know about truthiness and falsiness, as it will otherwise trip you up in certain cases.
Ternary operator
The ternary operator takes a condition, an expression to execute if the condition is truthy and an expression to execute if the condition is falsy. It looks like this:
const done = false;
const doneMsg = 'All tasks are done';
const notDoneMsg = 'There are tasks left';
const msg = done ? doneMsg : notDoneMsg;
The general form is:
condition ? expression1 : expression2;
You can think of the ternary operator as a short, compact way to write a conditional expression.
The ternary operator evaluates a condition, and if that condition is true (truthy), the result will have the value of the first expression.
If the condition is false (falsy), the result will have the value of the second expression.
There is a very common thing beginning programmers do with ternary operators which looks like this:
const finished = tasks.length === 0 ? true : false;
You should stop for a second and think about why this is unnecessary.
That's right—the expression tasks.length === 0 already evaluates to a boolean value.
You can just write this instead:
const finished = tasks.length === 0;
Optional chaining
Consider the following task object:
const nextTask = {
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book',
date: {
day: 8,
month: 6,
year: 2022,
},
};
Let's say we want to access the day of the task.
We can do this by writing nextTask.date.day.
But what if the day does not have to be present, i.e. is optional?
This could happen, for example, because the user didn't enter a date.
This means that the object could look like this:
const nextTask = {
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book',
};
Then nextTask.date.day will fail with
Uncaught TypeError: Cannot read properties of undefined (reading 'day')
This makes sense since nextTask.date will result in undefined and you can't access a property on undefined.
But let's say we would like to access the day and set it to undefined if the date property is not present.
Then we would need to do something like the following:
const day = nextTask.date !== undefined ? nextTask.date.day : undefined;
Here is what this line does:
If nextTask.date is defined, then nextTask.date.day is assigned to day.
If nextTask.date isn't defined, then undefined is assigned to day.
Alternatively we could make use of && and write:
const day = nextTask.date && nextTask.date.day;
This is correct because of the way the
&&operator works. If the first expression isfalse(or falsy) then&&doesn't look at the second expression and immediately returns the value of the first expression. If the first expression istrue(or truthy) then&&returns the second expression.
We can generally consider an object that has a bunch of values that may be absent (i.e. null or undefined).
Working with such values will be annoying and only grow more cumbersome with deeper nesting.
To avoid all this JavaScript allows you to do optional chaining.
This works by writing ?. instead of . when trying to work on something that may be absent.
The above line would then become:
const day = nextTask.date?.day;
Now the result will be undefined instead of a TypeError.
The switch Statement
The switch statement evaluates an expression and then attempts to match the result against a number of case clauses.
As soon as a case clause is matched all following statements are executed until a break statement is encountered.
If no case matches and a default statement is present, execution will jump to the code after the default statement.
Here is an example:
switch (tasks.length) {
case 0:
console.log('Hooray, you completed all your tasks!');
break;
case 1:
console.log('Only one task left! Go! Go! Go!');
break;
case 2:
console.log('You have two tasks to do.');
break;
case 3:
console.log('There are three tasks left.');
break;
default:
console.log('You still have some tasks to complete.');
}
Don't forget the break statements, otherwise all the code after the matched case will be executed, which is rarely what you want.
While Loops
You can use loops to repeat an action multiple times (usually depending on some condition).
The while loop allows you to execute a statement as long as a certain condition is true:
let counter = 0;
while (counter < 3) {
console.log(counter);
counter += 1;
}
This will log the following lines to the console:
0
1
2
The general form of the while loop looks like this:
while (condition) {
statements;
}
The statements inside the curly braces will be executed as long as condition is true (or, rather, truthy).
The do...while loop is similar to the while loop with one subtle difference.
The while loop evaluates the condition before executing the statement.
The do...while loop on the other hand evaluates the condition after executing the statement.
Consider this example:
let counter = 0;
do {
console.log(counter);
counter++;
} while (counter < 3);
This will log the following lines to the console:
0
1
2
3
The general form of the do...while loop looks like this:
do {
statements;
} while (condition);
Because of the way the do...while loop works the statement(s) inside the loop body will always be executed at least once.
The following example will log Hello to the console once despite the condition being false:
do {
console.log('Hello');
} while (false);
We recommend that you avoid using do...while loops whenever possible.
Regular while loops are easier to understand in most cases.
For Loops
The regular for loop consists of three expressions.
The first expression is the initialization expression and typically initializes some kind of counter. The second expression is the condition expression and typically checks for some condition. If the condition is true, the statement(s) in the loop body execute, otherwise the loop terminates. Finally, the third expression (sometimes called afterthought expression) is evaluated at the end of each loop iteration and typically advances the counter.
As usual, a code example says more than a thousand words:
for (let i = 0; i < 3; i++) {
console.log(i);
}
This will log the following lines to the console:
0
1
2
You can, among other things, use regular for loops to iterate over arrays:
const tasks = ['Task 1', 'Task 2', 'Task 3'];
for (let i = 0; i < tasks.length; i++) {
console.log(tasks[i]);
}
This will log the following lines to the console:
Task 1
Task 2
Task 3
However, we will soon learn better ways to perform array iteration.
The break and continue Statements
The break statement gives you a tool to prematurely terminate a loop:
let counter = 0;
while (counter < 4) {
console.log(counter);
counter += 1;
if (counter === 2) {
break;
}
}
Here we will immediately exit the loop as soon as counter === 2.
Therefore, the following lines will be logged to the console:
0
1
The continue statement terminates the rest of the current iteration and continues with the next iteration of a loop:
let counter = 0;
while (counter < 4) {
counter += 1;
if (counter === 2) {
continue;
}
console.log(counter);
}
This will log the following lines to the console:
1
3
4
Note that the loop still continues even after counter becomes 2.
However, the rest of the iteration is skipped when counter === 2.
Therefore, you won't see the 2 logged to the console.
Functions
— Ancient Chinese proverb
Declaring and Calling Functions
In our programs we often need to execute groups of actions over and over again. For example, we might want to get the list of all tasks assigned to a user at various parts of our task application. Instead of writing code that (essentially) does the same thing again and again we could use a function.
Within the function definition we would specify what statements should be executed. Then we can write a function call (also called function invocation). This would then actually execute the statements specified in the definition.
We can use this mechanism to group common actions into a function and then just call the function whenever we need to execute those actions.
Here is a very simple function definition:
function printGreeting() {
console.log('Hello, World!');
}
Function definitions begin with the function keyword followed by the function name (in this case printGreeting).
We will cover the meaning of the parentheses () in a second, but the curly braces {} contain the body of the function.
These are all the statements that will be executed when the function is called.
In this case we have one statement, which will simply output Hello, World! to the console.
You can call / invoke the printGreeting function like this:
printGreeting(); // Hello, World!
You can have as many statements as you want inside the function body:
function printGreetings() {
console.log('Hello, World!');
console.log('Hello, again!');
}
If you call printGreetings() both statements will be executed and the console output will look as follows:
Hello, World!
Hello, again!
These functions are not particularly interesting since they do the exact same thing for every function call. In this case, we print the exact same greeting(s) every time.
But what if we wanted to (for example) output a different greeting depending on the user?
We can do this by defining function parameters. These allow us to pass values into the function. That way the function can adjust its behaviour depending on those values.
The function parameters go between the parentheses:
function printGreeting(user) {
console.log(`Hello, ${user}!`);
}
printGreeting('Jane'); // Hello, Jane!
In this example we have a single parameter called user.
The function prints the greeting with the appropriate user inserted.
Within the function call we then pass the user (Jane in this case) as an argument to the function.
We can also return values from functions using the return keyword.
This keyword is used to specify the result that the function should produce, which can then be used in other parts of your code.
Here is a function that takes a number and returns the square of that number:
function square(num) {
return num * num;
}
We can now use the function as follows:
const squaredNum = square(3);
console.log(squaredNum); // 9
Default Parameters
You can use default parameters to initialize parameters with default values if either no values or undefined are passed as arguments:
function add(x, y = 1) {
return x + y;
}
console.log(add(1)); // 2
console.log(add(1, undefined)); // 2
console.log(add(1, 4)); // 5
Here, if no argument or undefined is passed to y, the value of y will automatically become 1.
Rest Parameters
Sometimes it can be useful to pass an arbitrary number of arguments to a function.
This can be done via rest parameters which uses the ...args syntax:
function sum(...args) {
let result = 0;
for (let i = 0; i < args.length; i++) {
result += args[i];
}
return result;
}
console.log(sum()); // 0
console.log(sum(1)); // 1
console.log(sum(1, 2)); // 3
console.log(sum(1, 2, 3)); // 6
The args object is simply an array.
All arguments that can't be matched to any parameter will be inside the args array:
function f(x, y, ...args) {
console.log(`x=${x}, y=${y}, args=${args}`);
}
f(1, 2, 3, 4); // x=1, y=2, args=3,4
Functions are Objects
Despite the fact that using typeof on a function will result in function, JavaScript functions are really just objects.
This is not a general feature of all programming languages. In many other languages, functions and objects are fully separate concepts.
This means that we can assign functions as variables, pass them to other functions as arguments and do all the other neat things we can do with objects.
For example, we could assign the square function to a variable:
const square = function square(num) {
return num * num;
};
We could then call this like a regular function by writing e.g. square(3).
This is called a function expression. Note that the function may be anonymous (i.e. nameless):
const square = function (num) {
return num * num;
};
The syntax for calling such a function is still the same, e.g. we would still write square(3) to call the function.
Arrow Functions
There is a shorthand notation available in JavaScript called the arrow function notation.
This notation allows you to omit certain keywords in certain situations.
For example, here is how you could rewrite the square function using the arrow function notation:
const square = (num) => num * num;
This is much shorter and less tedious (remember that?) indeed.
For an arrow function you only have to specify the parameter(s), followed by an arrow =>, followed by the returned value.
If you have multiple parameters, you need to put them inside parentheses:
const add = (x, y) => x + y;
You can also have multiple statements in the function body, but then you have to specify the return keyword and surround the statements with curly braces:
const printAndGreet = (user) => {
const greeting = `Hello ${user}`;
console.log(greeting);
return greeting;
};
As you can see this is not too different from a regular function declaration or expression (unlike the square function, where the arrow notation was much shorter).
It's therefore common practice to only use arrow functions for really short functions like square.
However, this is again just a convention that we will use in this book.
As usual, it's totally fine to use arrow functions everywhere (or never use arrow functions)—just be consistent.
One thing you may have noticed is that we only showed you arrow function expressions. This is not an oversight, but stems from the fact that there is no way to write a function declaration with the arrow function notation.
Scope
The scope of a variable is the part of the program in which it can be referenced. There are three scopes that are important right now—the global scope, the function scope and the block scope.
Later we will also learn about the module scope.
Consider the following script:
let inGlobalScope = 0;
function f() {
let inFunctionScope = 1;
if (true) {
let inBlockScope = 2;
}
}
The variable inGlobalScope is in global scope and can be accessed by the entire script.
For example, all of these console.log calls will correctly print the value of the variable:
let inGlobalScope = 0;
function f() {
let inFunctionScope = 1;
if (true) {
let inBlockScope = 2;
console.log(inGlobalScope);
}
console.log(inGlobalScope);
}
f();
console.log(inGlobalScope);
This will log:
0
0
0
The variable inFunctionScope is accessible only from within the function f:
let inGlobalScope = 0;
function f() {
let inFunctionScope = 1;
if (true) {
let inBlockScope = 2;
console.log(inFunctionScope);
}
console.log(inFunctionScope);
}
f();
console.log(inFunctionScope); // This will result in an error!
This will print:
1
1
file.js:16
console.log(inFunctionScope);
^
ReferenceError: inFunctionScope is not defined
Finally, the variable inBlockScope is in block scope and is available only in the block of the if statement:
let inGlobalScope = 0;
function f() {
let inFunctionScope = 1;
if (true) {
let inBlockScope = 2;
console.log(inBlockScope);
}
console.log(inBlockScope); // This will result in an error!
}
f();
This will log:
2
file.js:12
console.log(inBlockScope); // This will result in an error!
^
ReferenceError: inBlockScope is not defined
Function Signature
The function signature refers to the arguments that a function takes and the value(s) it returns.
Consider the following sum function:
function sum(a, b) {
return a + b;
}
The function signature of the sum function can be described by saying that this function takes two numbers and returns another number.
Programmers often talk about changing the function signature. This just means changing the function such that it takes different arguments (or arguments of different data types) and/or returns different arguments (or arguments of different data types).
For example, if the sum function would take an additional argument, it would have a different function signature:
function sum(a, b, c) {
return a + b + c;
}
Similarly, if sum would take two strings instead of two numbers, it would also have a different function signature (and also a highly misleading name):
function sum(a, b) {
return `a=${a}, b=${b}`;
}
This is only an example to show a change of a function signature. Please don't write functions with highly misleading names like that.
JSDoc
JSDoc is a markup language that can be used to annotate JavaScript code. Its most important use is to annotate functions.
For example, here is how you could annotate a function using JSDoc:
/**
* Calculates the sum of two numbers.
*
* @param {number} a - The first number.
* @param {number} b - The second number.
* @returns {number} The sum of a and b.
*/
function sum(a, b) {
return a + b;
}
This is useful if you have complex functions with lots of parameters. Documenting your functions allows other developers to quickly understand their purpose without needing to read the function bodies.
Classes
— Ancient Chinese proverb
Defining Classes
Instead of manually constructing objects, you can also use classes. We will not write our own classes in this book since we adopt a functional style, so we will keep this section as brief as possible.
Nevertheless, you still have to roughly understand what a class is in order to use the pre-built classes like Error or Map that we will discuss in the following sections.
At its core, classes are templates for creating objects.
For example, you could define a Task class that would serve as a template for creating new task objects like this:
class Task {
constructor(id, title, description) {
this.id = id;
this.title = title;
this.description = description;
}
}
Note the presence of the special constructor method.
This method allows you to initialize the newly created object with some values.
Specifically, you can construct a task object from the Task class using the new operator:
const task = new Task(1, 'Read the Next.js book', 'Read and understand the Next.js book.');
If an object is constructed from a class X, we often say that the object is an instance of X or just an X object.
For example, task would be an instance of the Task class or just a Task object.
You can then access the instance properties as you normally would:
console.log(task.id); // 1
console.log(task.title); // Read the Next.js book
console.log(task.description); // Read and understand the Next.js book.
Another important keyword for working with classes is the this keyword which allows you to point to the current instance of the class you're working with.
Put simply, this is a reference to the current object.
Therefore, when we write this.id = id in the constructor, we want to initialize the id of the current object with the id that was passed as an argument to the constructor.
The this keyword is particularly important in the context of instance methods.
Instance Methods
An instance method (often just method for short) is a function which is a property of an object. Here is a simple example:
const greeter = {
greet: function () {
console.log('Hello, World!');
},
};
You can call a method like this:
greeter.greet(); // Hello, World!
Just like constructors, methods can refer to the properties of an object using the this keyword:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
longDescription: function () {
return `${this.title}(ID = ${this.id}): ${this.description}`;
},
};
You can call the method by writing task.longDescription().
This would output:
Read the Next.js book(ID = 1): Read and understand the Next.js book.
We can also define instance methods for an entire class. In that case, the instance method is available for all objects of that class.
For example, we could write an instance method that creates a short task description by combining the ID and title of a task like this:
class Task {
constructor(id, title, description) {
this.id = id;
this.title = title;
this.description = description;
}
getShortDescription() {
return `Task ${this.id} (${this.title})`;
}
}
Let's now construct two tasks:
const task1 = new Task(1, 'Read the Next.js book', 'Read and understand the Next.js book.');
const task2 = new Task(2, 'Write a task app', 'Write an awesome task app.');
We can now log the short description of the first task:
console.log(task1.getShortDescription());
This will log:
Task 1 (Read the Next.js book)
Similarly, we can log the short description of the second task:
console.log(task2.getShortDescription());
This will log:
Task 2 (Write a task app)
Note how getShortDescription is available for both task1 and task2.
But how does this work?
Put differently, how does getShortDescription know whether it should refer to task1 or task2?
The answer lies in the this keyword.
In the case of task1.getShortDescription(), this will refer to task1 and so the function will access task1.id and task1.title.
However, in the case of task2.getShortDescription(), this will refer to task2 and so the function will access task2.id and task2.title.
Static Methods
Static methods are methods that can't be accessed on instances of a class, but must be accessed directly on the class itself.
For example, you can use Number.parseInt to parse a string argument:
console.log(Number.parseInt('123')); // 123
Static methods will become important in a few sections, when we introduce a few useful static methods that deal with arrays and objects.
Error Handling
— Ancient Chinese proverb
The throw Statement
The throw statement allows you to throw an exception:
throw 'Something bad happened';
You can theoretically throw any value.
However, you will usually throw Error objects:
throw new Error('Something bad happened');
Remember that the
newoperator creates a new object (of some class).
The try...catch Statement
The try...catch statement specifies a block of statements to execute "normally" and a block to execute if the "normal" block throws an exception.
The normal block is contained in a try block while the "exception" block is contained in a catch block.
If any statement in the try block throws an exception, code execution jumps to the catch block immediately—the rest of the try block is ignored:
function divide(x, y) {
if (y === 0) {
throw new Error('Division by 0 is a bad idea');
}
return x / y;
}
try {
console.log('try block');
console.log(divide(3, 0));
} catch (e) {
console.log('catch block');
}
This will log:
try block
catch block
Note that if the try block doesn't throw an exception, the catch block is never executed.
Consider this example:
function divide(x, y) {
if (y === 0) {
throw new Error('Division by 0 is a bad idea');
}
return x / y;
}
try {
console.log('try block');
console.log(divide(3, 1));
} catch (e) {
console.log('catch block');
}
This will log:
try block
3
The finally Block
The finally block is an optional block that can be used after catch if some cleanup code should always run after the try block:
function divide(x, y) {
if (y === 0) {
throw new Error('Division by 0 is a bad idea');
}
return x / y;
}
try {
console.log('try block');
console.log(divide(3, 0));
} catch (e) {
console.log('catch block');
} finally {
console.log('finally block');
}
This will output:
try block
catch block
finally block
The finally block will become useful once we write more complex code that performs resource management and we need to perform cleanup of a resource regardless of whether an exception is thrown or not.
Error Objects
Error objects have a name and a message property which can be used to gather information when an error is thrown:
function divide(x, y) {
if (y === 0) {
throw new Error('Division by 0 is a bad idea');
}
}
try {
console.log('try block');
divide(3, 0);
} catch (e) {
console.log('catch block');
console.log(e.name);
console.log(e.message);
}
This will log:
try block
catch block
Error
Division by 0 is a bad idea
Basic Data Structures
— Ancient Chinese proverb
More on Strings
We already learned that strings represent sequences of characters.
We also learned that they can be concatenated using the + operator and that you can get their length using the length property.
However, this is not enough to efficiently work with strings.
Luckily, strings offer a wide range of additional functionality for pretty much every use case you will ever need—in this subsection we will briefly look at some of it.
First, you can access individual characters using the charAt function or array brackets:
const str = 'Hello';
console.log(str[1]); // e
console.log(str.charAt(1)); // e
Remember, there is no special character data type in JavaScript, i.e. typeof str[1] is simply 'string'.
Strings also offer a wide range of methods, most of which are self-explanatory:
const str = 'Hello';
console.log(str.concat(', World!')); // Hello, World!
console.log(str.includes('el')); // true
console.log(str.startsWith('He')); // true
console.log(str.endsWith('llo')); // true
console.log(str.indexOf('l')); // 2
console.log(str.lastIndexOf('l')); // 3
console.log(str.toLowerCase()); // hello
console.log(str.toUpperCase()); // HELLO
The substring method allows you to return a part of a string.
You need to pass a start index and an end index:
console.log(str.substring(1, 3)); // el
Note that the start index will be included and the end index will be excluded when creating the substring.
There is also the
substrmethod which is similar. However,substris deprecated and, therefore, you shouldn't use it.
The trim method allows you to remove whitespace from the start and the end of a string.
This is especially useful when you need to process user input and remove accidental whitespace at the start and the end of a string:
console.log(' Hello '.trim()); // Hello
The split method splits the string into substrings by a delimiter.
For example, here is how you might split a comma-separated list into its items:
console.log('Task 1, Task 2, Task 3, Task 4'.split(','));
This will result in the following array:
[ 'Task 1', ' Task 2', ' Task 3', ' Task 4' ]
Note that the whitespace is not removed by the split method.
You would need to iterate over the resulting array and use the trim method on each string to accomplish that.
More on Arrays
We already learned how to construct arrays and how to work with individual array elements. However, just like strings, arrays have a few additional methods that will often come in handy.
You can check whether an object is an array using the Array.isArray method:
console.log(Array.isArray([1, 2, 3])); // true
console.log(Array.isArray('123')); // false
Array.isArrayis a static method. We talked about static methods in the section on classes.
You can create an array from an object with Array.from.
To successfully use Array.from the object must be convertible to an array.
For example, a string is convertible to an array:
console.log(Array.from('123')); // [ '1', '2', '3' ]
If you try to use Array.from on an object that is not convertible to an array you will get an empty array:
console.log(Array.from(2)); // []
You can create an array from a variable number of arguments by using Array.of:
console.log(Array.of(1, 2, 3)); // [ 1, 2, 3 ]
Just like strings, arrays have a concat, includes, indexOf and lastIndexOf method:
console.log([1, 2, 3].concat([4, 5, 6])); // [ 1, 2, 3, 4, 5, 6 ]
console.log([1, 2, 3].includes(2)); // true
console.log(['a', 'b', 'b', 'c'].indexOf('b')); // 1
console.log(['a', 'b', 'b', 'c'].lastIndexOf('b')); // 2
The join method allows you to concatenate all elements in an array to a string, where the elements are separated by a delimiter:
console.log(['H', 'e', 'l', 'l', 'o'].join('')); // Hello
console.log(['H', 'e', 'l', 'l', 'o'].join(',')); // H,e,l,l,o
You can use the push method to add a new element to the end of an array:
const arr = [1, 2, 3];
arr.push(4);
console.log(arr); // [ 1, 2, 3, 4 ]
Of course, you could also do this with concat.
However, when you just want to add a single element, it's more common to use push.
The pop element removes the last element of an array:
const arr = [1, 2, 3];
arr.pop();
console.log(arr); // [ 1, 2 ]
The reverse method allows you to reverse an array:
const arr = [1, 2, 3];
arr.reverse();
console.log(arr); // [ 3, 2, 1 ]
Arrays can be nested, resulting in multidimensional arrays.
Accessing an element of such a nested array results in another array (of a lower dimension).
Nested arrays can be flattened with the flat method:
const nestedArray = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
];
console.log(nestedArray[1]); // [ 4, 5, 6 ]
console.log(nestedArray[1][2]); // 6
console.log(nestedArray.flat()); // [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
The for...of Loop
For...of loops allow you to iterate over arrays and strings (and a few other things) and perform a task for each element/character.
Let's say you want to print all tasks from a list named tasks.
Previously, we would have used a regular for loop:
const tasks = ['Task 1', 'Task 2', 'Task 3'];
for (let i = 0; i < tasks.length; i++) {
console.log(tasks[i]);
}
Instead you can use the for...of loop to accomplish the same thing:
const tasks = ['Task 1', 'Task 2', 'Task 3'];
for (let task of tasks) {
console.log(task);
}
Both versions will output:
Task 1
Task 2
Task 3
As we already mentioned, you can use a for..of loop to iterate over a string as well:
const str = 'Task';
for (let char of str) {
console.log(char);
}
This would output each character of the string, i.e.:
T
a
s
k
The general syntax of a for..of loop is
for (let variable of arrayOrString) {
statements;
}
It should be noted that if you don't change the variable inside the loop, you can and should also declare it as const.
Our first for...of example could therefore be rewritten to
const tasks = ['Task 1', 'Task 2', 'Task 3'];
for (const task of tasks) {
console.log(task);
}
Just to reiterate, a
for...ofloop can iterate over more objects than just arrays and strings. However, this is out of scope for this book.
More on Objects
You can use the static methods Object.keys and Object.values to retrieve the keys and values of an object respectively:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
console.log(Object.keys(task)); // [ 'id', 'title', 'description' ]
console.log(Object.values(task)); // [ 1, 'Read the Next.js book', 'Read and understand the Next.js book.' ]
You can also use the static method Object.entries to retrieve the key-value pairs of an object:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
console.log(Object.entries(task));
This will output:
[
['id', 1],
['title', 'Read the Next.js book'],
['description', 'Read and understand the Next.js book.'],
];
The for...in Loop
The for...in loop allows you to iterate over the properties of an object.
For example:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
for (const prop in task) {
console.log(prop);
}
This will output:
id
title
description
Maps
A Map object is a collection of a key-value pairs:
const capitals = new Map([
['Germany', 'Berlin'],
['France', 'Paris'],
]);
capitals.set('Spain', 'Madrid');
console.log(capitals.get('France')); // Paris
console.log(capitals.size); // 3
capitals.delete('France');
console.log(capitals.has('France')); // false
At first glance maps appear to be very similar to objects. However, there are a few important differences.
First, it's very easy to get the size of a map (using the size property), whereas with objects you would need to keep track of the size manually.
Second, the keys of an object are usually strings, whereas with maps they can have any data type.
It's recommended to use maps if the key-value pairs are unknown until run time (for example, because they are determined by user input), all keys have the same type and all values have the same type.
Sets
A Set object is a collection of unique values:
const values = new Set([1, 2, 3]);
values.add(4);
console.log(values.has(2)); // true
console.log(values.size); // 4
values.delete(3);
console.log(values.has(3)); // false
Note that all values in a set must be unique, i.e. duplicates are not allowed:
const values = new Set([1, 2, 3]);
values.add(2);
console.log(values); // Set(3) { 1, 2, 3 }
JSON
JSON is a data format for data exchange (e.g. on a network) and can basically store nested JavaScript objects and arrays. While it was heavily inspired by JavaScript, it has become a language-independent data format and is in fact used by many other programming languages to exchange data.
Here is an example JSON file:
{
"user": {
"name": "John Doe",
"age": 24,
"hobbies": ["running", "swimming"]
},
"group": "Example group"
}
Yes, this is exactly the same syntax that you would use in JavaScript to define objects and arrays.
You can convert a JavaScript value to a JSON string using JSON.stringify:
const result1 = JSON.stringify({ x: 1 });
console.log(typeof result1); // 'string'
console.log(result1); // {"x":1}
const result2 = JSON.stringify([1, 2, 3]);
console.log(typeof result2); // 'string'
console.log(result2); // [1,2,3]
Note that JSON.stringify has some unintuitive behaviors.
For example, running JSON.stringify on a map or a set will always return {}:
console.log(JSON.stringify(new Map([[1, 2]]))); // {}
console.log(JSON.stringify(new Set([1, 2]))); // {}
The reverse operation to JSON.stringify is JSON.parse which takes a JSON string and constructs a JavaScript value from it:
const obj = JSON.parse('{"x": 1}');
console.log(typeof obj); // 'object'
console.log(obj); // { x: 1 }
const arr = JSON.parse('[1, 2, 3]');
console.log(typeof arr); // 'object'
console.log(arr); // [ 1, 2, 3 ]
We will revisit the JSON data format when we start sending data over a network.
Functional Thinking
— Ancient Chinese proverb
Pure Functions
A function is called pure if its outputs (the returned values) depend only on its inputs and if the function doesn't have any side effects. This means that the function doesn't change program state and doesn't write anything to an external data source.
Here is an example of a pure function:
const square = (x) => x * 2;
Indeed, the output of square depends only on its input and nothing else.
In addition, square doesn't produce any side effects.
Here is an example of a function that is not pure:
const x = 2;
const addImpure = (y) => x + y;
The output of this function doesn't depend just on its input variables, but also on a global variable x.
Here is another function that's not pure:
const sayHello = () => console.log('Hello, World!');
The sayHello function has a side effect—it outputs something to the console.
Why do we care about all of this? The fundamental reason is that pure functions are very easy to reason about. There is practically no room for surprising behaviour.
Consider the above square function.
It takes an input and produces an output that is dependent only on the input.
It doesn't matter what the rest of the program is doing—the function will always produce identical outputs for identical inputs.
If you are mathematically inclined, pure functions are basically regular mathematical functions. They take an input which is a member of some domain and produce an output which is a member of some codomain. For example, the
squarefunction is simply the function f: A → B, f(x) = x² where A and B are certain sets of numbers. Note that A and B are emphatically not equal to the set of real numbers since JavaScript can't represent every possible real number (we've already discussed this).
All of the above isn't true for the addImpure function.
That's because it can produce different outputs for identical inputs.
This makes it very hard to troubleshoot the function in case of an error.
After all, you may not know what the (global) state of the program was when the error occurred.
Closely related is another very nice property of pure functions—they are easily testable. There is no need to fake global state as the function output depends only on the input. Therefore, all you need to do is to call the function, pass some input and check whether the output matches the expected output.
Immutability
A variable is immutable if it's unchangeable. Otherwise, we call it mutable. The more mutability we have inside our program the more can go wrong since it's hard to reason about (global) state.
This is where the alert reader might interject—after all, isn't the purpose of a program to do something? And how can we achieve that if we don't change state?
A fundamental correction is in order here—the purpose of every program isn't to do something, but to manipulate data. You can of course manipulate data directly by mutating global state like in the following example:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
task.title = 'Next.js book';
This works for simple objects and changes. But such an approach will quickly become brittle with growing complexity. Reasoning about state and state changes is hard.
Instead, we can create copies of the objects which contain the changes we need:
const newTask = {
...task,
title: 'Next.js book',
};
Note that we didn't change the original object, but created a copy of the object with a different title.
Immutability and pure functions are closely linked. The programs that are easiest to understand are the ones where immutable data structures are passed through pure functions.
Higher-Order Functions
We already know that JavaScript functions are just regular objects. We even showed an example of how you can assign a function to a variable:
const square = (num) => num * num;
This allows us to do interesting things. Because functions are just objects we can pass them to other functions.
Consider an example function that repeats some action n times:
function repeat(fun, n) {
for (let i = 0; i < n; i++) {
fun();
}
}
We can use it like this:
const hello = () => console.log('Hello, World!');
repeat(hello, 4);
We could even shorten this code to:
repeat(() => console.log('Hello, World!'), 4);
Both versions will produce the same output:
Hello, World!
Hello, World!
Hello, World!
Hello, World!
The most important thing here is that the repeat function doesn't care what fun is.
Indeed, fun could be a simple console.log or a function which simulates a universe.
All the repeat function does is simply repeat fun the specified number of times.
Functions which take (or return) functions are called higher-order functions.
The Trinity of map, filter and reduce
We now introduce the three most important higher-order functions—map, filter and reduce.
These functions allow you to perform an incredibly rich set of operations on arrays.
We want to use this blockquote to emphasize how often you will be using
map,filterandreduce.
We will use two running examples throughout the section—an array of numbers and an array of tasks:
const numbers = [1, 2, 3, 4];
const tasks = [
{
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
timeLogged: 60,
status: 'In progress',
},
{
id: 2,
title: 'Write a task app',
description: 'Write an awesome task app.',
timeLogged: 0,
status: 'Todo',
},
{
id: 3,
title: 'Think of a funny joke',
description: 'Come up with a funny joke to lighten the mood.',
timeLogged: 120,
status: 'In progress',
},
];
The map function takes one argument—a function f to apply to every element of the array.
It returns the array that results from applying f to every element of the original array.
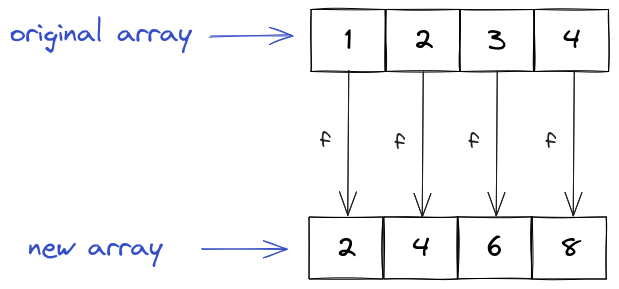
Let's say we wanted to square all the elements of numbers.
We could write something like this:
const result = [];
for (const number of numbers) {
result.push(number ** 2);
}
This is ugly and (you guessed it) tedious.
Instead we can (and should) use the map function:
const result = numbers.map((number) => number ** 2);
console.log(result); // [1, 4, 9, 16]
Consider another example.
Let's say we wanted to add a long description to all the tasks based on the title and the description.
We can use the map function again:
const longTasks = tasks.map((task) => ({
...task,
longDescription: `${task.title}: ${task.description}`,
}));
You can see why the spread syntax is so handy. Thanks to this incredible innovation, you only need to explicitly specify the object parts where something interesting happens.
The longTasks array will look like this:
[
{
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
timeLogged: 60,
status: 'In progress',
longDescription: 'Read the Next.js book: Read and understand the Next.js book.',
},
{
id: 2,
title: 'Write a task app',
description: 'Write an awesome task app.',
timeLogged: 0,
status: 'Todo',
longDescription: 'Write a task app: Write an awesome task app.',
},
{
id: 3,
title: 'Think of a funny joke',
description: 'Come up with a funny joke to lighten the mood.',
timeLogged: 120,
status: 'In progress',
longDescription: 'Think of a funny joke: Come up with a funny joke to lighten the mood.',
},
];
The filter function allows you to select elements from an array based on some condition.
It takes a function f which returns true or false for some input(s).
All elements for which f returns true are kept, all elements for which f returns false are thrown away.
A function which returns
trueorfalseis commonly referred to as a predicate.
For example, let's say we want to select all even elements from numbers.
Here is the non-functional way:
const result = [];
for (const number of numbers) {
if (number % 2 === 0) {
result.push(number);
}
}
Ugh! For loops and if statements all over the place. So non-functional. Let's rest our eyes and consider the functional approach:
const result = numbers.filter((number) => number % 2 === 0);
The filter function also works in more complicated scenarios.
For example, we might want to select all tasks from the tasks array which have the status 'Todo'.
Think for a moment what the appropriate predicate would be.
That's right, it looks like this:
const todoTasks = tasks.filter((task) => task.status === 'Todo');
Finally, there is the reduce function which (you guessed it) reduces an array to a single value.
The reduce function moves over an array from left to right and keeps track of a value (a so-called accumulator).
At every element of the array it recomputes the accumulator based on a function f (this function f is the first argument of the reduce function).
The second argument of the reduce function is the initial value.
Here is how we might compute the sum of an array:
const sum = numbers.reduce((acc, curr) => acc + curr, 0);
Basically, this is what happens:
The reduce function looks at acc (which is the initial value, i.e. 0 at the beginning) and curr (which is 1), produces acc + curr, and sets this as the new accumulator (i.e. the new accumulator is 1).
Next, the reduce function again looks at acc (which is now 1) and curr (which is 2), produces acc + curr, and sets this as the new accumulator (i.e. the new accumulator becomes 3).
The next update results in the accumulator being 6 and the final update results in the accumulator being 10.
Therefore, sum becomes 10.
For another example, let's say we would like to compute the total logged time (i.e. the time logged for all the tasks combined). This would look like this:
const totalTime = tasks.reduce((curr, task) => task.timeLogged + curr, 0);
We recommend that you try to reason through this
reducefor a deeper understanding of this topic.
Note that unlike map and filter, you should use reduce sparingly as it's very easy to write very convoluted code with reduce.
If you find yourself writing extremely complicated reduce expressions, you should consider using for loops and if statements instead.
Other Higher-Order Functions
While map, filter and reduce are the most known higher-order functions, JavaScript provides us with many more.
It's worthwhile to get to know them since they will make a lot of tasks easier.
The find method returns the first element in an array that satisfies some predicate:
const numbers = [2, 8, 4, 12, 6, 10];
console.log(numbers.find((x) => x > 9)); // 12
The findIndex method is similar, except that it returns the index of the first element in an array that satisfies some predicate:
const numbers = [2, 8, 4, 12, 6, 10];
console.log(numbers.findIndex((x) => x > 9)); // 3
The every method checks whether all elements in an array satisfy a predicate:
const numbers = [2, 8, 4, 12, 6, 10];
console.log(numbers.every((x) => x % 2 === 0)); // true
console.log(numbers.every((x) => x < 9)); // false
The some method checks whether there is at least one element in an array that satisfies a predicate:
const numbers = [2, 8, 4, 12, 6, 10];
console.log(numbers.some((x) => x < 9)); // true
console.log(numbers.some((x) => x % 2 !== 0)); // false
The forEach method executes some function for every array element.
This is very similar to a for loop (hence the name):
const numbers = [2, 8, 4, 12, 6, 10];
numbers.forEach((x) => console.log(x));
This will output:
2
8
4
12
6
10
Sorting Arrays
The sort method can be used to sort the elements of an array:
const tasks = ['Task 2', 'Task 1', 'Task 3'];
tasks.sort();
console.log(tasks); // [ 'Task 1', 'Task 2', 'Task 3' ]
The default sort order is ascending and elements are sorted by converting them to strings and then sorting the strings lexicographically. However, this may not be what you want, especially when you're trying to sort numbers:
const numbers = [2, 8, 4, 12, 6, 10];
numbers.sort();
console.log(numbers); // [ 10, 12, 2, 4, 6, 8 ]
If you want to sort differently, you need to specify a comparison function compareFn.
A comparison function takes two arguments a and b and returns a number whose sign indicates the relative order of the elements in the sorted array.
If compareFn(a, b) is greater than 0, a should be sorted after b.
If compareFn(a, b) is smaller than 0, a should be sorted before b.
If compareFn(a, b) is equal to 0, the original order of a and b should be kept.
For example, if you want to sort numbers in an ascending manner, you should specify the comparison function (x, y) => x - y.
After all, if x - y is greater than 0 then y will be sorted after x (which is exactly what you want).
Similarly, if x - y is smaller than 0 then y will be sorted before x (which is again what you want).
const numbers = [2, 8, 4, 12, 6, 10];
numbers.sort((x, y) => x - y);
console.log(numbers); // [ 2, 4, 6, 8, 10, 12 ]
If you would want to sort numbers in a descending manner, you would need to change your comparison function to (x, y) => y - x:
const numbers = [2, 8, 4, 12, 6, 10];
numbers.sort((x, y) => y - x);
console.log(numbers); // [ 12, 10, 8, 6, 4, 2 ]
You can use the comparison function to sort arbitrary objects as well.
For example, here is how you could sort the tasks array by the timeLogged property:
tasks.sort((task1, task2) => task1.timeLogged - task2.timeLogged);
Asynchronous Programming
is hard Asynchronous programming
Why Asynchronous Programming?
We often need to execute long-running operations (especially in web development).
For example, we might need to fetch a resource from a server or request camera access from a user. In the first case, we need to wait for all the network packets to arrive, which might take a long time depending on the quality of your network (especially if you happen to live in Germany). In the second case, we need to wait for the user to grant us access to the resource we require.
We want to be able to execute such long-running operations without "blocking". To accomplish this, we need to break up with our current "synchronous" programming model where statements are executed one after another.
Consider the following "synchronous" example:
function getUser(userId) {
return `User with ID ${userId}`;
}
const user = getUser(0);
console.log(user);
The getUser function is a synchronous function.
This means that the calling code (const user = getUser(0) in this case) has to wait until getUser has finished its work to continue.
That is all fine and dandy here, given that getUser should (hopefully) complete its work quite quickly.
But what if getUser represents a long-running operation, like retrieving a user from a remote server?
function getUser(userId) {
return retrieveUserFromServer(userId);
}
const user = getUser(0);
console.log(user);
Now the calling code has to wait for the network request to complete before it can do anything else.
This is potentially a huge problem in the browser environment, given that synchronous functions like getUser are "blocking".
Therefore, as long as getUser is executing, no other code will be able to run, including code that handles user events.
In practical terms, this means that the user will not be able to select text, click buttons or do anything else with the website, i.e. the website will "hang".
Of course, we want to avoid such a nuisance since this will result in the much-dreaded negative user experience.
If you've ever clicked a button on a website and everything just freezes for three seconds, this is probably the result of a synchronous function being used to handle a long-running operation.
We therefore need a mechanism to start a (potentially) long-running operation and still be able to do other things (like respond to user events) instead of blocking until the operation is finished. Once the operation is completed, our program also needs to be notified with the result of the long-running operation.
Here is a step-by-step breakdown of what we want to accomplish:
- Call a function that starts a long-running operation.
- The function should return immediately, so that the "main" program is able to do something else.
- Once the long-running operation is completed, the "main" program should be notified with the result of the long-running operation.
In case you think to yourself right now "this all sounds very complicated and when do I need long-running operations anyway, maybe I'll skip this section"—don't. Practically every project you'll write (essentially when doing web development) will contain a lot of asynchronous code.
Promises
The central object in asynchronous JavaScript is the promise. A promise represents the eventual completion (or failure) of an asynchronous operation. Now, that you're sufficiently confused by this opaque definition, we can move on to an actually useful explanation.
Basically, a promise is like an IOU document—it "promises" you that it's currently working on some long-running operation and that it will eventually get back to you with the result of that long-running operation.
To give another metaphor, consider the process of ordering a hamburger at SyncMcBurgers. For simplicity (and improved metaphormaking), we will pretend that SyncMcBurgers only has a single counter.
In a perfect “synchronous” world, you would walk up to the counter, tell your order to the hardworking employee of the restaurant and then they would immediately create the hamburger right then and there. However, unless SyncMcBurgers has rediscovered the ancient secret art of instant burgermaking using dark magic, the preparation of a hamburger doesn't happen immediately (it's a "long-running operation").
Therefore, in reality the following process happens when you try to order something at SyncMcBurgers. You walk up to the counter and the employee takes your order (a hamburger) and starts preparing the hamburger right there at the counter in front of you. In the meantime, you have to wait at the counter until the hamburger is finished.
This process has an obvious problem—both you and the employee now block the entire restaurant from doing anything else (remember, there is only a single counter). No other customer can try to order anything (because you're standing at the counter) and no other employee can take an order anyway (because the employee serving you is blocking the counter with his hamburger preparation). This doesn't sound like a recipe for success.
After a while the restaurant owners realize this, there is a change in management and SyncMcBurgers rebrands as AsyncMcBurgers. The important difference between SyncMcBurgers and the new and improved AsyncMcBurgers is a change in the burger ordering process.
There is still only one counter though. After all, even the new management at AsyncMcBurgers wants to respect our metaphor.
The new process looks as follows. You walk up to the counter, an employee takes your order and hands it to the kitchen. Instead of the burger, they hand you a receipt, which is a promise (get it?) that you will get your burger after some time. Now you don't have to stand in front of the counter waiting for the employee to finish making the burger. Instead, you take your receipt, leave the counter and the next customer may order.
In case you missed it, this is how every normal fast food restaurant in the world operates—and for good reason (except that normal fast food restaurants usually have more than a single counter).
Armed with these examples, we can now actually understand the definition of a promise.
Again, a promise represents the eventual completion (or failure) of an asynchronous operation.
In this example, the asynchronous operation is the preparation of the hamburger. This asynchronous operation will eventually complete (the hamburger will be prepared) or fail (there will be a problem during the hamburger preparation). The order receipt that you get represents the eventual (i.e. probably not immediate) completion of the burger preparation.
Now, we can also introduce the three states a promise can be in:
We say that a promise is pending when it has been created, but the asynchronous operation it represents has not been completed yet. This would be the case when you already received the order receipt but you're still waiting for the hamburger.
We say that a promise is fulfilled when the asynchronous operation it represents has been successfully completed. This would be the case when the hamburger has been successfully prepared and handed to you.
We say that a promise is rejected when the asynchronous operation it represents has failed. This would be the case when (for example) the kitchen spontaneously combusts due to the ongoing AsyncMcBurger dark magic experiments in the backroom lab.
Promises also allow us to associate handlers (also called handler functions) with the eventual success or failure. For example, we could say that when the hamburger is prepared, we want to eat it (or throw it in the trash, which might actually be the preferable alternative in some cases).
Working with Promises in JavaScript
Let's work through an example—fetching a resource from a server via HTTP. The HTTP protocol will be discussed in more detail later, but basically it enables us to send a request to a server and get a response. Since network packets don't arrive immediately, this can take a while, so we are dealing with a "long-running operation" here.
Both the browser as well as Node.js allow us to retrieve a resource from the network via the asynchronous fetch function.
The fetch function returns a promise and we can then schedule a callback to be executed when the promise has succeeded by using the then method.
Here is how this looks in code:
const url = 'https://jsonplaceholder.typicode.com/todos/1';
const fetchPromise = fetch(url);
fetchPromise.then((response) => console.log(response));
console.log(fetchPromise);
This code is unnecessarily verbose right now, we will fix this in a second. Also, we wouldn't normally log the
fetchPromiseobject, we're just doing this for illustration purposes right now.
This is what happens:
- We call
fetchwhich immediately returns a pending promise. - The
thenmethod allows us to register a handler function that should be called once the promise has been fulfilled. In this case, we register a simple handler function(response) => console.log(response)that logs the response. - After a while the
fetchsucceeds,fetchPromiseis (hopefully) fulfilled and theresponseobject is logged.
It's important to note that fetch returns immediately.
The return value of fetch is a pending promise (that will eventually settle with either a response value or some kind of error).
This is why console.log(fetchPromise) is executed before console.log(response) and you'll see the following output in the console:
Promise { <pending> }
Response {
...
}
Additionally, the then method also returns immediately after it has attached the handler function to the fetchPromise.
However, the execution of the handler function happens only after the promise returned by fetch is fulfilled.
On one hand, this is what we want—while we are waiting for the network request to complete, we can do other stuff (like logging fetchPromise).
On the other hand, this is the reason why asynchronous programming is often so confusing to beginners—it "breaks" the regular programming model.
When we write synchronous code, we just execute statements one after another. If line A comes before line B in synchronous code, then line A will also be executed before line B in synchronous code.
With asynchronous code this is no longer the case—here we "register" a function to be executed later, do something else, and then at some point the registered function is executed. This means that even if line A comes before line B in asynchronous code, it's quite possible that line A will be executed after line B. Therefore, you have to be very careful when reading and writing asynchronous code.
Finally, we note that our code can be rewritten in a simpler way:
const url = 'https://jsonplaceholder.typicode.com/todos/1';
fetch(url).then((response) => console.log(response));
Chaining Promises
The response object is not terribly useful by itself.
Let's retrieve the "actual" response which is a JSON object.
Here is how the JSON we get from https://jsonplaceholder.typicode.com/todos/1 looks like:
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": false
}
The response object has a json method to retrieve the JSON contained in a response.
However, the json method is also asynchronous, so we are again dealing with promises.
Your first instinct might be to write something like this:
const url = 'https://jsonplaceholder.typicode.com/todos/1';
const fetchPromise = fetch(url);
const jsonPromise = fetchPromise.then((response) => {
const jsonPromise = response.json();
jsonPromise.then((json) => console.log(json));
});
This is technically not wrong, but it's very ugly. Basically, every time we need to add an asynchronous operation to our code that depends on the result of a previous asynchronous operation, we would need to add one level of nesting which will quickly become unreadable.
Luckily for us, the benevolent god-emperors of JavaScript have eliminated this problem by making then return a promise that "resolves" to the result of the handler function.
Therefore, instead of nesting promises, we can chain promises:
const url = 'https://jsonplaceholder.typicode.com/todos/1';
const fetchPromise = fetch(url);
const jsonPromise = fetchPromise.then((response) => response.json());
jsonPromise.then((json) => console.log(json));
This is (quite appropriately) called promise chaining.
Here is what happens when we call this code:
- The
fetchmethod immediately returns a pending promisefetchPromise. - The
thenmethod offetchPromiseattaches the handler function(response) => response.json()to thefetchPromiseand also immediately returns. This time the return value is the pending promisejsonPromise. - The
thenmethod ofjsonPromiseattaches the handler function(json) => console.log(json)and also immediately returns another pending promise (which we ignore here). - After a while, the network request initiated by
fetchfinishes andfetchPromiseis fulfilled (with aResponseobject as its fulfillment value). - Now that
fetchPromiseis fulfilled, the handler function(response) => response.json()is kicked off and attempts to parse the response as a JSON object. At some point, the JSON parsing is finished andjsonPromiseis fulfilled. - Now that
jsonPromiseis fulfilled the handler function(json) => console.log(json)is kicked off and the JSON object is logged to the console.
A promise chain is basically executed in two stages.
In the first stage, the promises are set up and the handler functions are attached using the then method.
This stage happens immediately.
In the second stage, the promises are settled and the attached handler functions are actually executed. This stage can take quite some time, depending on how long the operations we want to accomplish take.
This explanation is the most important part of this entire section. You should pause and think about this promise chain for a second (or maybe even multiple seconds). If you understand this point, you (mostly) understand asynchronous programming.
Finally, we can rewrite our promise chain to be a bit more elegant:
const url = 'https://jsonplaceholder.typicode.com/todos/1';
fetch(url)
.then((response) => response.json())
.then((json) => console.log(json));
Handling Errors
The above code is completely missing one very important point—error handling.
Most long-running operations (especially those that involve external resources like a network or a file system) can fail.
For example, fetch will fail and fetchPromise will thus be rejected if your network is down.
You can test this—turn off your WiFi and execute the above code again. You will get a weird error that looks approximately like this:
TypeError: fetch failed
at Object.fetch (node:internal/deps/undici/undici:11457:11)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5) {
cause: Error: getaddrinfo EAI_AGAIN jsonplaceholder.typicode.com
at GetAddrInfoReqWrap.onlookup [as oncomplete] (node:dns:107:26) {
errno: -3001,
code: 'EAI_AGAIN',
syscall: 'getaddrinfo',
hostname: 'jsonplaceholder.typicode.com'
}
}
Additionally, we will usually want to throw an error if fetch itself succeeds, but the status of the response is "not ok" (we will return to this in more detail in the section about HTTP):
const url = 'https://jsonplaceholder.typicode.com/todos/1';
fetch(url)
.then((response) => {
if (!response.ok) {
throw new Error(`Request failed with status ${response.status}`);
}
return response.json();
})
.then((json) => console.log(json));
We want to be able to catch all the errors that can happen and log an error message to the console.
The Promise API gives us the appropriately named catch method to accomplish this.
We can simply add a catch handler to the end of our promise chain—it will be called when any of the asynchronous operations fail:
const url = 'https://jsonplaceholder.typicode.com/todos/1';
fetch(url)
.then((response) => {
if (!response.ok) {
throw new Error(`Request failed with status ${response.status}`);
}
return response.json();
})
.then((json) => console.log(json))
.catch((error) => console.error(error));
Turn off your network and try running the fetch again.
You will now see an appropriately logged error.
Instead of just crashing, your program can now do something else (like showing an error modal to the user and informing them that something went wrong).
The async and await Keywords
Promises are great, but as discussed, they are not completely intuitive.
We can use async and await keywords to simplify asynchronous code and make it look more like synchronous code.
Instead of using the then() method, we can use the await keyword to wait for a promise and get its fulfillment value.
This looks as follows:
const response = await fetch(url);
Just like then(), this will not block the main program.
Instead, the function containing the await will be "paused" until the awaited promise is fulfilled or rejected.
After that, the function will be "resumed" again.
Functions that contain await statements have to be marked as async.
Here is how we can rewrite our task fetching code to use async and await:
async function fetchTask(url) {
try {
const response = await fetch(url);
if (!response.ok) {
throw new Error(`Request failed with status ${response.status}`);
}
const json = await response.json();
return json;
} catch (error) {
console.error(`Could not fetch URL ${url}`);
}
}
// Note that for some runtimes you can only use "await" inside an "async" function.
// Therefore, our main code still uses the regular then() method.
const url = 'https://jsonplaceholder.typicode.com/todos/1';
fetchTask(url).then((json) => console.log(json));
The void Operator
The void operator evaluates an expression and returns undefined.
This can be used with promises if you simply want to start an asynchronous operation, but you don't care about the result:
void fetchTask(url);
Modules
— Ancient Chinese proverb
Module System
At the moment, the scripts we write are not large and easily fit into a single file. However, as we begin writing our task application, we will run into the problem that if we try to fit our entire project into a single file, that file will quickly become unreadable and unmaintainable.
Additionally, we might often want to use third-party libraries (i.e. libraries written by someone else) in our project. Copy and pasting the code from a third-party library seems like an obviously bad idea. First, this would make our scripts even less readable. Second, what do we do if the library receives an update?
Luckily, JavaScript provides us with a mechanism to use code from one file in another file—modules.
We will mostly discuss ECMAScript modules (ESM). There are other module systems, but we will only cover them very briefly and only use them for minor examples. Especially for the final project, we will only use ESM.
The import and export Keywords
Let's start our module discussion with a very simple example. We will create a file containing a function and then try to use that function in another file.
Create a file greeter.js containing the following code:
export function greet(name) {
return `Hello, ${name}!`;
}
Note the export keyword here.
This exports the greet function, i.e. it tells JavaScript to make this function available to other files.
We can now import the greet function in another file.
Create a file main.js in which we try to use the greet function:
import { greet } from './greeter.js';
console.log(greet('World'));
This is the basic setup, but in order to actually execute this in the browser or in Node.js we need to make some more adjustments.
ESM in the Browser
Let's create a file named index.html in which we use main.js as a JavaScript module:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>ESM Demo</title>
</head>
<body>
<script type="module" src="main.js"></script>
</body>
</html>
If you just try to open index.html in the browser, you will a CORS Error:
Access to script at 'file:///.../main.js' from origin 'null' has been blocked by
CORS policy: Cross origin requests are only supported for protocol schemes:
http, data, isolated-app, chrome-extension, chrome, https, chrome-untrusted.
We won't go into the details of CORS, but basically this error happens because ECMAScript modules are subject to the same-origin policy. We therefore need to serve our files over a server instead of just trying to open them in our browser.
Let's install the http-server package:
pnpm add -g http-server
The
-gflag tellspnpmto install the package globally and not just for a particular project. This is similar to the-gflag fornpm.
Now, enter the directory where you've stored index.html, main.js and greeter.js and execute the following command:
http-server .
Go to http://localhost:8080, open the console and you should see Hello, World! in your console.
ESM in Node.js
To use main.js and greeter.js in Node.js, we will need to create a project.
Therefore you need to create the following package.json file in the same directory as main.js and greeter.js:
{
"name": "projectname",
"version": "1.0.0",
"main": "main.js",
"type": "module"
}
Note that it is very important that you specify
typeasmodule. This tells node to interpret JavaScript files as using ESM syntax (which is what we use in this section).
You can then execute main.js by running:
node main.js
We will return to the concept of
package.jsonin more detail later.
Named Exports and Imports
The example above showed the use of named exports. Here, each function is referred by its name when exporting and the same name is used when importing. You can export multiple functions when performing named exports.
You can create a named export by prefixing a function with the export keyword:
export function getGreeting(name) {
return `Hello, ${name}!`;
}
export function greet(name) {
console.log(getGreeting(name));
}
Alternatively, you can use an export list:
function getGreeting(name) {
return `Hello, ${name}`;
}
function greet(name) {
console.log(getGreeting(name));
}
export { getGreeting, greet };
You should use named exports if you need to export several values/functions.
Note that you can rename exports in an export list:
function getImportantGreeting(name) {
return `Hello, ${name}!`;
}
export { getImportantGreeting as getGreeting };
If you need to import multiple functions, you can do that as well:
import { getGreeting, greet } from './greet.js';
You can also rename imports:
import { getGreeting, greet as sayHello } from './greet.js';
This is useful if you have several modules that export functions with a same name.
For example if you had a module greet that exports the function greet and a module other-greet that exports the function greet as well, you would run into problems if you just tried to import greet:
import { greet } from './greet.js';
import { greet } from './other-greet.js';
Instead you could rename one or both greet functions:
import { greet } from './greet.js';
import { greet as otherGreet } from './other-greet.js';
Default Exports and Imports
If you want to have a default function provided by your module, you can use a default export:
function getGreeting(name) {
return `Hello, ${name}!`;
}
export default function greet(name) {
console.log(getGreeting(name));
}
Alternatively you could write:
function getGreeting(name) {
return `Hello, ${name}!`;
}
function greet(name) {
console.log(getGreeting(name));
}
export default greet;
You could also write:
function getGreeting(name) {
return `Hello, ${name}!`;
}
function greet(name) {
console.log(getGreeting(name));
}
export { greet as default };
Note that you can't have more than one default export. This means that you should use default exports when you have one very important value or function that you'd like to export.
You can import a default exported value like this:
import greet from './greet.js';
console.log(greet('World'));
Alternatively, you could use the default as syntax:
import { default as greet } from './greet.js';
console.log(greet('World'));
Note that you can import the default exported value using any name you like:
import thingy from './greet.js';
Namespace Imports
If you wish to avoid name conflicts (like in the greet situation presented previously) you can do even better with namespace imports:
import * as greet from './greet.js';
greet.getGreeting('World');
The import * as syntax retrieves all exports available in greet.js, creates a namespace object greet and makes all the exports available as a member of that object.
This means that the greet conflict can be resolved like this:
import * as greetModule from './greet.js';
import * as otherGreetModule from './other-greet.js';
greetModule.greet('World');
otherGreetModule.greet('World');
Module Scope
You already know the global scope, the function scope and the block scope. Now that we've introduced modules, there is one more scope you should know about—the module scope.
As the name already says this is the scope of a module and each module has its own scope. This means that variables and functions declared in a module are not visible to code outside the module unless they are explicitly exported. Even if a variable or a function is explicitly exported it can't be used in outside code unless it has been explicitly imported first.
This ensures that modules don't accidentally interfere with each other.
Consider this example:
function getGreeting(name) {
return `Hello, ${name}!`;
}
export function greet(name) {
console.log(getGreeting(name));
}
Here the getGreeting function is not exported, meaning that it will remain completely private to the module.
Only the greet function can be used (since it's exported).
Let's try importing getGreeting:
import { greet, getGreeting } from './greet.js';
You will get the following error:
import { greet, getGreeting } from './greet.js';
^^^^^^^^^^^
SyntaxError: The requested module './greet.js' does not provide an export named 'getGreeting'
CJS Modules
So far, we've been discussing ECMAScript modules (ESM). One alternative to ESM is a module system called CommonJS (CJS for short).
You can export objects in CJS using module.exports and import objects in CJS using require().
Let's rewrite our running example in CJS. If you're following along, you should create a separate directory for this example.
Create a file greet.js and export functions using module.exports:
function getGreeting(name) {
return `Hello, ${name}!`;
}
function greet(name) {
console.log(getGreeting(name));
}
// Exporting the functions
module.exports = { getGreeting, greet };
And now create a file app.js where you import the functions from greet.js using require():
// Importing the module
const { getGreeting, greet } = require('./greet');
console.log(getGreeting('World')); // Hello, World!
greet('World'); // Hello, World!
You can now run the greet.js without any additional configuration (you don't even need a package.json):
node app.js
We will only use CJS for short Node.js examples where we want to avoid the setup of a new project. However, other than that, we will follow the current best practices and only use ESM throughout this book. This is mainly because CJS is an older module system that was designed exclusively for Node.js and has been mostly replaced by ESM.
Packages
— Ancient Chinese proverb
Creating a Package
The heart of any JavaScript package is the package.json file.
This should contain JSON with important information about the package like its name, version, and many other things.
Here is the minimal package.json:
{
"name": "example-package",
"version": "1.0.0"
}
The version field follows a convention called SemVer (short for Semantic Versioning).
This defines that any version of a package (or library) should have the format MAJOR.MINOR.PATCH where MAJOR, MINOR, and PATCH are non-negative integers.
Whenever you update a package, you should make a change to the package version.
This might be a change to either MAJOR, MINOR or PATCH, depending on the kind of change you make.
Most importantly, you should ask yourself if the change is backwards compatible with the old version of the package.
A change is backwards compatible if a user of the old package can switch to your new package without any issues. For example, if you simply add a new function to your package, then that change is backwards compatible. This is also true if you change some code in a function without changing the functionality of the function.
However, if you change the way an existing package function works, the change is no longer backwards compatible. If a user of your package now tries to switch from the old version to the new version, all the calls to that function will no longer work. Programmers call this "breaking the package".
If you make such a backwards incompatible change, you should increment the MAJOR number and reset the other numbers.
For example, if you release a big update of a package with the version 1.32.2 where you change a lot of function signatures you should update the version to 2.0.0.
If you add functionality in a backwards compatible manner, you should increment the MINOR number and reset the PATCH number.
For example, if you release an update of a package with the version 1.32.2 and you add a couple of new functions you should update the version to 1.33.0.
If you just make backwards compatible bug fixes, you should increment the PATCH number.
For example, if you release an update of a package with the version 1.32.2 and you fix a bug in one of your functions you should update the version to 1.32.3.
The main field can be used to specify the entry point of your package.
This is the primary file that will be loaded if your package is required by a Node.js application.
Since we use ESM for our modules, we will also need to specify "type": "module" in our package.json.
For example, if we want index.js to be the entry point of our package, we would need to specify the following package.json file:
{
"name": "example-package",
"version": "1.0.0",
"type": "module",
"main": "index.js"
}
Next, let's create an ESM module index.js:
export function greet(name) {
console.log(`Hello ${name}`);
}
You can now use the greet function of your package in other packages that import it.
We will show an example of this in a second.
Installing Dependencies
To install dependencies, you will need a package manager like npm or pnpm.
The main difference between these is that pnpm stores packages globally meaning that if multiple projects use the same package, pnpm will only store it once and then link to it as needed.
We use pnpm throughout this book.
There is also a difference between dependencies and "dev" dependencies. Regular dependencies are packages that your project needs to run. "Dev" dependencies are packages that are only needed during development or testing. These will not be included in the final production build of your package (the final production build is the code that will actually be deployed to your users' devices).
You can install a dependency by running pnpm add $PACKAGE_NAME in the project directory.
You can install a "dev" dependency by running pnpm add --save-dev $PACKAGE_NAME instead.
Let's install the lodash dependency which is a widely used utility library:
pnpm add lodash
The dependency will now appear in your package.json:
{
"name": "example-package",
"version": "1.0.0",
"type": "module",
"main": "index.js",
"dependencies": {
"lodash": "^4.17.21"
}
}
You will also see a pnpm-lock.yaml which specifies the locked package versions:
lockfileVersion: '6.0'
settings:
autoInstallPeers: true
excludeLinksFromLockfile: false
dependencies:
lodash:
specifier: ^4.17.21
version: 4.17.21
packages:
/lodash@4.17.21:
resolution:
{
integrity: sha512-v2kDEe57lecTulaDIuNTPy3Ry4gLGJ6Z1O3vE1krgXZNrsQ+LFTGHVxVjcXPs17LhbZVGedAJv8XZ1tvj5FvSg==,
}
dev: false
The actual package will be located in the node_modules directory (more specifically, at node_modules/lodash).
Don't be afraid of the
node_modulesdirectory. There is no black magic there—node_modulessimply contains the code of the dependencies you've installed. In fact, we encourage you to browse through thenode_modules/lodashdirectory and realize that it's just regular JavaScript code.
Let's now use lodash in our index.js:
import _ from 'lodash';
console.log(_.capitalize('hello, World!'));
Execute the file by running node index.js.
This should output:
Hello, World!
Scripts
To simplify running scripts, the package.json allows you to define a scripts field:
{
"name": "example-package",
"version": "1.0.0",
"type": "module",
"main": "index.js",
"dependencies": {
"lodash": "^4.17.21"
},
"scripts": {
"greet": "node index.js"
}
}
Now you can run:
pnpm run greet
This will again output Hello, World!.
The scripts mechanism becomes especially useful if you need to execute a lot of commands to achieve a result.
Instead of repeating those commands over and over again, you can specify a script and then just run that script.
Publishing Packages
Let's return to our package from the beginning of this section.
We had this package.json file:
{
"name": "example-package",
"version": "1.0.0",
"type": "module",
"main": "index.js"
}
And we had this ESM module index.js:
export function greet(name) {
console.log(`Hello ${name}`);
}
What if we want to make this package available to other people?
We could publish our package to the npm repository.
This is in fact where we pulled the lodash package from earlier.
Please don't actually publish this silly example package to the npm repository. It's already plenty polluted as it is. However, the steps outlined below will be useful to you, if you plan to actually publish something interesting.
The publishing process is pretty simple:
First, you need to create an account at npmjs.com.
Second, you need to log in to your account in your terminal by running:
npm login
Third, you will need to publish the package by running:
pnpm publish --access public
After you're done, you can verify that the package was published successfully by going to https://www.npmjs.com/package/$YOUR_PACKAGE_NAME.
Writing Decent Code
— Ancient Chinese proverb
It Just Works
A common misunderstanding among beginner programmers is that if the program runs correctly, then the code must automatically be fine. A correctly running program is indeed better than a crashing program (a truly shocking insight for some developers). However, good code should not just work, but also be maintainable in the future.
This maintainability has two aspects:
- Code should be maintainable by future you in (let's say) six months.
- Code should be maintainable by other people that aren't you.
We wish to reiterate that there are indeed people that aren't you in the world, some of which might even end up on your team. There are programmers that tend to forget that.
This section is aimed at giving you a few practical tips to achieve these goals. It won't make you a great programmer, but it will help you to make your teammates hate you slightly less (which is why the section is called "writing decent code" and not "writing the greatest code of all time").
Sensible Naming
In order for code to be maintainable, it has to be readable first. After all, if you can't read something, you most certainly will not be able to maintain it.
The ultimate number one tip for writing better code is therefore as obvious in theory, as it's complicated in practice:
Your variables and functions should have sensible names that describe their purpose.
Consider this simple example:
function f(a, s) {
const r = [];
for (const i of a) {
if (i.st === s) {
r.push(i.su);
}
}
return r;
}
Clearly, this code sucks. It's absolutely unreadable and the unreadability is solely down to really terrible variable names.
Let's rewrite it:
function getTaskTitlesByStatus(tasks, status) {
const taskTitles = [];
for (const task of tasks) {
if (task.status === status) {
taskTitles.push(task.title);
}
}
return taskTitles;
}
And suddenly the purpose of the code is clear as day.
The function getTaskTitlesByStatus gets all the titles of the tasks that have a certain status.
And we know that, because it is literally in the name of the function!
Not only does the function have a good name (which is important when trying to use this function), but so do the variables (which is important when we need to fix possible mistakes in this function).
This is a very extreme example (that's on purpose), but very often even professional software developers give terrible names to functions and variables.
Of course, naming things is usually not as easy as in this example. There are many legitimate cases where giving something a good name is not trivial. Nevertheless, you should at least always try hard to have sensible names. The poor soul that will have to fix your bugs six months from now will really thank you for that. And you should always remember that this poor soul might be you.
Note how we wrote try hard and not just try. The worst code is code that has lots of bad naming. You should therefore absolutely invest time into thinking about good names for your variables and functions.
Know and Use Your Language Features
JavaScript has drastically changed for the better in the past decade—there is no need to write code like it's 2012.
For example getTaskTitlesByStatus could be rewritten in a functional style:
function getTaskTitlesByStatus(tasks, status) {
return tasks.filter((task) => task.status === status).map((task) => task.title);
}
Modern programming languages have a wide variety of features, most of which can make your life easier. Use them.
Write Small Helper Functions
Most of the time a function is not as simple as getTaskTitlesByStatus, which often leads to many lines of complex code that are hard to understand.
A common practice for such cases is this:
Extract code from complicated functions into helper functions and then call the helper functions.
Consider a function that takes an array of tasks and returns an array of generated notifications to be shown to the user.
The notifications are generated for urgent tasks (i.e. tasks where the deadline is in the next two days). Additionally, we generate a notification with the number of uncompleted tasks.
You might write the function like this:
function generateNotifications(tasks) {
const urgentTasks = [];
let uncompletedTaskCount = 0;
tasks.forEach((task) => {
const today = new Date();
const twoDaysLater = new Date(today.getFullYear(), today.getMonth(), today.getDate() + 2);
if (task.deadline <= twoDaysLater) {
urgentTasks.push(task);
}
if (task.status === 'todo' || task.status === 'inprogress') {
uncompletedTaskCount++;
}
});
const notifications = [];
if (urgentTasks.length > 0) {
notifications.push(
`You have ${urgentTasks.length} urgent tasks. Here they are: ${urgentTasks}.`,
);
}
if (uncompletedTaskCount > 0) {
notifications.push(`You have ${uncompletedTaskCount} uncompleted tasks.`);
}
return notifications;
}
Try to read this function and understand it—this will probably take up quite some time.
We can massively improve this code by splitting the function into small helper functions.
If you look at this function closely, you can see that it really does two different things. It prepares the relevant information to generate the notifications and then generates the actual notifications.
Therefore, we can split this function into two smaller functions, where the first function prepares the information and the second function generates the notifications.
Additionally, the first function computes two different pieces of information. First, it finds all the urgent tasks and second, it finds the number of tasks that haven't been yet completed.
Therefore, we can split the initial function into three smaller functions and call them one by one:
- a
findUrgentTasksfunction which finds all the tasks that are urgent - a
countUncompletedTasksfunction which finds the number of uncompleted tasks - a
generateNotificationsFromTasksfunction which generates the notifications
Here is how the final result could look like:
function findUrgentTasks(tasks) {
const urgentTasks = [];
const today = new Date();
const twoDaysLater = new Date(today.getFullYear(), today.getMonth(), today.getDate() + 2);
tasks.forEach((task) => {
if (task.deadline <= twoDaysLater) {
urgentTasks.push(task);
}
});
return urgentTasks;
}
function countUncompletedTasks(tasks) {
let uncompletedTaskCount = 0;
tasks.forEach((task) => {
if (task.status === 'todo' || task.status === 'inprogress') {
uncompletedTaskCount++;
}
});
return uncompletedTaskCount;
}
function generateNotificationsFromTasks(urgentTasks, uncompletedTaskCount) {
const notifications = [];
if (urgentTasks.length > 0) {
notifications.push(
`You have ${urgentTasks.length} urgent tasks. Here they are: ${urgentTasks}.`,
);
}
if (uncompletedTaskCount > 0) {
notifications.push(`You have ${uncompletedTaskCount} uncompleted tasks.`);
}
return notifications;
}
function generateNotifications(tasks) {
const urgentTasks = findUrgentTasks(tasks);
const uncompletedTaskCount = countUncompletedTasks(tasks);
return generateNotificationsFromTasks(urgentTasks, uncompletedTaskCount);
}
The generateNotifications function is now much simpler to read.
Instead of a multiple potentially complex calculations, it contains functions where each function is responsible for exactly one complex calculation.
Note that the if statements and loops didn't really change, but they now do isolated things inside helper functions with sensible names.
For example, the for loop that calculates the uncompletedTaskCount is now isolated inside the countUncompletedTasks function and therefore its purpose is immediately clear—even before you've read the actual loop.
Of course, the implementations of the helper functions in this section could be improved by using a more functional style. You should absolutely go ahead and try it out.
Make Functions Reusable
You try to keep your functions not just small, but also reusable.
A practical hint for making functions more reusable is this:
Extract values from function bodies into (default) parameters.
For example, findUrgentTasks calculates the future date by adding 2.
But what if that changes, or even worse, different users can set a different number of added days for their notifications?
Then we would have to update the function implementation or write another function that does essentially the same thing but with a different number of added days.
This seems kind of redundant.
Let's move the number of added days into a default parameter:
function findUrgentTasks(tasks, addedDays = 2) {
const urgentTasks = [];
const today = new Date();
const laterDate = new Date(today.getFullYear(), today.getMonth(), today.getDate() + addedDays);
tasks.forEach((task) => {
if (task.deadline <= laterDate) {
urgentTasks.push(task);
}
});
return urgentTasks;
}
Note how we've also renamed twoDaysLater to laterDate since that variable now has a more general purpose.
Don't Repeat Yourself
This is probably one of the most well-known idioms in software development:
Don't repeat yourself.
For example, if you write a book, you shouldn't repeat the subsection heading in your text—that looks ugly and doesn't make any sense. Only a fool would do that.
The same principle goes for writing code. Consider the following example:
function reportOverdueTasks(tasks) {
const today = new Date();
const overdueTasks = tasks.filter((task) => {
return task.deadline < today && task.status !== 'done';
});
return overdueTasks.map((task) => `Task ID: ${task.id}, Title: ${task.title}`).join('\n');
}
function reportCompletedTasks(tasks) {
const completedTasks = tasks.filter((task) => task.status === 'done');
return completedTasks.map((task) => `Task ID: ${task.id}, Title: ${task.title}`).join('\n');
}
You might notice that the last line of both functions is essentially the same. This leads to a problem: If the report format changes, we need to update it multiple times.
Not only does this mean more work, we might even forget to update the report format in some place, leading to inconsistencies in our code.
We can refactor reportOverdueTasks and reportCompletedTasks like this:
function formatReport(tasks) {
return tasks.map((task) => `Task ID: ${task.id}, Title: ${task.title}`).join('\n');
}
function reportOverdueTasks(tasks) {
const today = new Date();
const overdueTasks = tasks.filter((task) => {
return task.deadline < today && task.status !== 'done';
});
return formatReport(overdueTasks);
}
function reportCompletedTasks(tasks) {
const completedTasks = tasks.filter((task) => task.status === 'done');
return formatReport(completedTasks);
}
Again, this is a very simple example, but the general principle holds for more complex situations as well. If you find yourself repeating very similar code over and over, you should probably extract it into a function.
Remember, that's why we introduced functions in the first place.
Avoid Deep Nesting
Consider a function that filters tasks based on their status, user ID and days until deadline. We could write it like this:
function filterTasks(tasks, status, userId, daysUntilDeadline) {
const filteredTasks = [];
for (let i = 0; i < tasks.length; i++) {
if (tasks[i].status === status) {
if (tasks[i].assignee === userId) {
const deadline = new Date(tasks[i].deadline);
const today = new Date();
const futureDate = new Date(
today.getFullYear(),
today.getMonth(),
today.getDate() + daysUntilDeadline,
);
if (deadline <= futureDate) {
filteredTasks.push(tasks[i]);
}
}
}
}
return filteredTasks;
}
This looks supremely ugly and hard to read due to the deep nesting of the code. Luckily, this is pretty easy to fix using two very specific tricks:
First, we can extract the body of the for loop into a helper function:
function taskMatchesCriteria(task, status, userId, daysUntilDeadline) {
if (task.status === status) {
if (task.assignee === userId) {
const today = new Date();
const futureDate = new Date(
today.getFullYear(),
today.getMonth(),
today.getDate() + daysUntilDeadline,
);
if (task.deadline <= futureDate) {
return true;
}
}
}
return false;
}
function filterTasks(tasks, status, userId, daysUntilDeadline) {
return tasks.filter((task) => taskMatchesCriteria(task, status, userId, daysUntilDeadline));
}
One level of nesting gone already.
For the second trick, we can simplify the taskMatchesCriteria by either flattening the conditions or using early exits.
Flattening the condition is simple:
function taskMatchesCriteria(task, status, userId, daysUntilDeadline) {
const today = new Date();
const futureDate = new Date(
today.getFullYear(),
today.getMonth(),
today.getDate() + daysUntilDeadline,
);
return task.status === status && task.assignee === userId && task.deadline <= futureDate;
}
However, sometimes this isn't possible or leads to a very complex logical expression. In this case we can check the "inverted" conditions one by one and "early exit" if something doesn't match:
function taskMatchesCriteria(task, status, userId, daysUntilDeadline) {
// Early exit number 1
if (task.status !== status) {
return false;
}
// Early exit number 2
if (task.assignee !== userId) {
return false;
}
const today = new Date();
const futureDate = new Date(
today.getFullYear(),
today.getMonth(),
today.getDate() + daysUntilDeadline,
);
return task.deadline <= futureDate;
}
The general takeaway is this:
Flatten deeply nested code by extracting helper functions and simplifying conditions.
Think About Edge Cases
One of the big differences between junior programmers and more senior developers is that juniors tend to ignore edge cases and just focus on the "happy path".
Consider this piece of code:
const task = tasks.find((task) => task.id === taskId);
task.assignee = userId;
task.status = 'inprogress';
This has a big problem: What if taskId is not present in the IDs of tasks?
Then task will be undefined and our program will crash when trying to assign the assignee property to task.
This edge case needs to be handled:
const task = tasks.find((task) => task.id === taskId);
if (task === undefined) {
console.log(`Task with ID ${taskId} not present`);
} else {
task.assignee = userId;
task.status = 'inprogress';
}
Example operations which can lead to problems if you don't consider edge cases are:
- division (because you could divide by zero)
- processing strings (because strings could be empty or have whitespace at the beginning or the end)
- extracting elements from arrays by a condition (because there might be no elements present that match the condition)
- processing user input (because users can and will type arbitrary garbage into your application)
Finally, every time you work with an external resource (like fetching something), you need to handle potential errors.
The main takeaway from this subsection is:
Don't be satisfied by just writing the happy path. Think about the edge cases.
Tips for Larger Projects
— Ancient Chinese proverb
The Product Drives the Code
The most important insight is:
The product drives the code, not the other way around.
A lot of software developers think it's their job to write code. This is wrong. The job of a software developer is to work on products.
This also means that your code should reflect the product and not some fancy abstraction that you thought would be fun to write.
If you're not working on a feature or something that supports the feature (like a test), you should think very hard about what you're doing and why.
Additionally, when you're working on a product, your names should also be as close to the application domain as possible.
If the client and the project managers talk about tasks and notifications and the UI shows big, fat texts called "Tasks" and "Notifications", then your variable names should probably not be jobs and reports.
You will just needlessly confuse everyone.
Keep It Simple, Stupid
The KISS principle (short for "keep it simple, stupid") states that you should keep your code as simple as possible, but not simpler.
Generally speaking, try to not outsmart yourself and stick to writing actual features instead of fancy abstractions that might or might not come in handy later. You should always remember that reading and fixing code is much harder than writing it in the first place. This means, that if you write code as smart as you possibly can, you aren't going to be able to fix it later.
Of course, if you realize that you're writing the same thing for the tenth time, it might be a good idea to take a step back and think if you can abstract that thing in a straightforward way. Unfortunately, many developers take this way too far. Don't be one of them.
The complexity of a codebase that doesn't religiously adhere to the KISS principle grows much faster than you think and will quickly overwhelm you completely.
Define Responsibilities Clearly
Split your code into well structured functions and modules. Generally speaking, a function should do one thing and do it well.
Of course "one thing" can mean different levels of detail. "One thing" might be everything from "add two numbers" to "simulate a universe".
If your function is simulating a universe, then it should probably call smaller, more focused functions internally (we've discussed this already). Nevertheless, avoid writing functions that do two completely unrelated things. For example, it's poor style to write a function that simulate a universe and then adds two numbers for some reason.
Similarly, try to follow the Single Responsibility Principle for modules. Every module should be responsible for a particular part of the application.
Use Docstrings
Document your most important functions using docstrings. This will help both you and your fellow teammates. Writing docstrings might seem tedious and unnecessary at first, but clear documentation can save hours of debugging later on.
Additionally, good documentation can help onboard new team members more quickly.
A good goal to strive for is that if I read the docstring of your function I should have a good understanding of how and when I can call it without having to read the implementation.
This is good because not only is it usually harder to read an implementation than a simple text (especially if the implementation is very long), but also because the implementation might change over time.
Perfect is the Enemy of Good
A lot of beginners think that the main difference between a junior and a senior is that the senior always writes perfect code (for some vague definition of perfect). That's not the case.
In fact, optimizing for perfect code is often a really terrible idea since that means that you will spend a lot of time "optimizing" code that was already good enough. This is a problem, because you will throw most of your code away due to ever-changing requirements.
You should try to follow our tips from the previous section on writing decent code. But in the end, your code won't be perfect and that's fine.
Final Remarks
Well, now that you made it through the last two sections, are you a great programmer? Unfortunately, the answer is a hard no.
If you could become a great programmer just by reading a couple of pages, then there wouldn't be entire bookshelves devoted to that topic.
There is only one way to become a good programmer:
You need to actually go out and write projects.
There is no way around it and in the end, experience is king.
But there is one important caveat—you have to actually learn from that experience and reflect on your mistakes.
So go out there, write features, make mistakes and learn something!
Chapter 2: Leveling Up with TypeScript
— Ancient Chinese proverb
Now that we learned the basics of JavaScript, we could theoretically dive right into writing our application. However, JavaScript as a language has a central problem—it does not come with type checking. For example, there is nothing preventing you from trying to add two objects except the fact that—well—your application will crash and burn.
In general, one of the most common error sources are what can be described as type errors: a certain kind of value was used where a different kind of value was expected. This could be due to simple typos, a failure to understand how to use a library correctly, incorrect assumptions about runtime behavior and more.
The goal of TypeScript is to provide static type checking for JavaScript programs—in other words, TypeScript provides you with tooling that runs before your code is executed (static) and ensures that the types of the program are correct (type checking).
Why TypeScript?
— Ancient Chinese proverb
A Little Story
Consider the following scenario.
You have a JavaScript function showTask(task) which takes a task object and displays the task in a UI (or in the console).
For example, let's say you have a task object looks like this:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
Can you pass this object to showTask?
Well, it's hard to tell.
Maybe the showTask function expects an object that has id, title, description and status fields.
The only way to find out if your task object is a valid input for showTask is to—well—actually pass it and find out.
This is obviously not the ideal workflow, especially if you happen to find out that your object lacked some important properties in production.
Additionally, if the author of the showTask function changes their function to expect additional properties on the task object, they would now have to check all the invocations of showTask to verify that they didn't accidentally break something.
This is where TypeScript comes in. With TypeScript we would be able to statically type the function by adding type annotations like this:
type Task = {
id: number;
title: string;
description: string;
};
function showTask(task: Task) {
// Implementation here
}
Now we know exactly what kind of object showTask expects.
Namely, it needs an id property which is a number, a title property which is a string and a description property which is also a string.
Here is how we could call this function:
showTask({
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
});
If we would pass an object that lacks some of the expected properties and run type checks (more on that later) we would get an error long before the bad code could make it anywhere near production. Even better—your editor would now be able to show you that you might have a problem during development:
showTask({
id: 1,
title: 'Read the Next.js book',
});
// Most editors will now show a squiggly red line somewhere around here and
// politely scream at you that the object is missing the description property.
Better still (TypeScript just keeps giving), you now get autocompletion—editors will show possible suggestions for the property names your object should have while you are typing. This saves an enormous amount of time and effort when writing code.
To summarize, using TypeScript massively enhances your developer workflow. This is why most large projects use TypeScript instead of vanilla JavaScript these days.
The TypeScript Compiler
You can install the TypeScript compiler globally by running the following command:
pnpm add -g typescript
Let's see how we can use the TypeScript compiler.
First, create a file index.ts:
type Task = {
id: number;
title: string;
description: string;
};
function showTask(task: Task) {
console.log(
`Task with ID=${task.id} has the title ${task.title} and description ${task.description}`,
);
}
showTask({
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
});
We can't execute TypeScript files in the browser or in Node.js directly. Instead we need to first compile the TypeScript code to JavaScript—which is why we installed the compiler.
Here is how we can compile the index.ts file:
tsc --strict index.ts
Note that the
--strictturns on certain "strict" type checks. We will basically always use this flag.
Since there were no type errors, nothing is logged in the console and we get a file index.js which looks (approximately) as follows:
function showTask(task) {
console.log(
'Task with ID='
.concat(task.id, ' has the title ')
.concat(task.title, ' and description ')
.concat(task.description),
);
}
showTask({
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
});
Note that all the type annotations are gone and all we get is vanilla JavaScript that we can execute.
Additionally, the TypeScript compiler downleveled our code so that it can be executed by older platforms.
Here the template string syntax (which is not supported by very old browsers) was replaced by a series of concat calls.
Note that by the time you're reading this the default target settings might be different and you might not see this particular downleveling anymore.
What if there is an error in index.ts?
Consider the following TypeScript code:
type Task = {
id: number;
title: string;
description: string;
};
function showTask(task: Task) {
console.log(
`Task with ID=${task.id} has the title ${task.title} and description ${task.description}`,
);
}
showTask({
id: 1,
title: 'Read the Next.js book',
});
If you would compile this code using tsc --strict index.ts, you would get the following error:
index.ts:13:10 - error TS2345: Argument of type '{ id: number; title: string; }' is not assignable to parameter of type 'Task'.
Property 'description' is missing in type '{ id: number; title: string; }' but required in type 'Task'.
13 showTask({
~
14 id: 1,
~~~~~~~~
15 title: 'Read the Next.js book',
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
16 });
~
index.ts:4:3
4 description: string;
~~~~~~~~~~~
'description' is declared here.
Found 1 error in index.ts:13
The compiler correctly informed us that if we were to run this code it would probably result in bad things happening due to the missing description property.
We now know that the code is probably wrong long before it made to production and can fix it accordingly.
Executing TypeScript Directly with tsx
Sometimes you want to execute a TypeScript file directly (especially during development) and not go through the "compile and run" cycle manually.
There are a couple of tools that allow you to do that—here we will introduce tsx (short for "TypeScript Execute").
Install tsx using the package manager:
pnpm add -g tsx
You can now execute a TypeScript file index.ts directly by running:
tsx index.ts
Basic Types
— Ancient Chinese proverb
Annotating Variables
You can annotate variables by adding a type annotation:
let task: string = 'Read the Next.js book';
You can annotate constants in a similar fashion:
const name: string = 'Read the Next.js book';
Note that explicit type annotations are usually not needed, since TypeScript can perform type inference to automatically infer the type of a variable or a constant.
In this example, the variable name will automatically be inferred to have the type string:
let name = 'Read the Next.js book';
We will very rarely write explicit type annotations (only if we really need them) and instead let TypeScript infer as much as it can. You will be surprised by how few type annotations you need to get completely type checked code!
Primitive Types
The primitive types that are present in TypeScript should already be familiar to you from the chapter on JavaScript.
TypeScript has the number type:
const id: number = 1;
TypeScript also has the string type:
const task: string = 'Read the Next.js book';
It also has the boolean type:
const inProgress: boolean = true;
Additionally, TypeScript has the null and undefined types:
const undefinedTask: undefined = undefined;
const nullTask: null = null;
Remember, in a real codebase we would let TypeScript infer the variables:
const id = 1;
const task = 'Read the Next.js book';
const inProgress = true;
const undefinedTask = undefined;
const nullTask = null;
In this example, TypeScript will infer that id has the type number, task has the type string, inProgress has the type boolean, undefinedTask has the type undefined and nullTask has the type null.
The any and unknown Types
TypeScript also has the any type.
When a value is of the type any, you can access its properties, call it, or assign it freely, and basically do anything (get it?) that's syntactically correct.
Also note that any property that you access will in turn have the type any.
Let's say you have a task variable of type any—then these are all legal:
let task: any;
console.log(task.title);
task();
task.thingy();
Basically using any is a way to tell the compiler to "shut up" and skip type checking altogether.
This is also the reason why using any is generally a bad idea since it defeats the purpose of using TypeScript in the first place!
However, sometimes you do find yourself in a situation where you really don't know much or don't particularly care about a variable type.
In this case it's better to use the unknown type.
Anything is assignable to unknown (just as with any).
However, no operations are allowed on an unknown variable without further assurances about the type of the variable.
For example, if you have a task variable of type unknown, then these are all no longer legal:
let task: unknown;
console.log(task.title);
task();
task.thingy();
Typing Arrays
You can type arrays as T[] where T is the type of the elements of the array.
For example, here is how you would type an array of numbers:
const evenNumbers: number[] = [2, 4, 6, 8];
Here is how you would type an array of strings:
const tasks: string[] = ['First task', 'Second task', 'Third task'];
Note that for these simple examples we could again have TypeScript infer the types.
In this example evenNumbers would have the type number[] and tasks would have the type string[]:
const evenNumbers = [2, 4, 6, 8];
const tasks = ['First task', 'Second task', 'Third task'];
Typing Objects
You can type an object by writing the property keys and types inside curly braces {}.
For example, here is how you could declare an object that has the properties id of type number, title of type string and description of type string:
const task: { id: number; title: string; description: string } = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
Here too, you don't need to manually specify object types.
In this example, task will be inferred to have the type { id: number; title: string; description: string }:
const task = {
id: 1,
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
};
You can mark properties as optional by using the question mark ?.
If a property is marked as optional, you can assign undefined to it or even not specify it altogether.
For example, this is valid:
const task: { id: number; title: string; description?: string } = {
id: 1,
title: 'Read the Next.js book',
};
const task2: { id: number; title: string; description?: string } = {
id: 1,
title: 'Read the Next.js book',
description: undefined,
};
Type Aliases
The object type syntax we just introduced is often quite verbose. This is why TypeScript gives you the possibility to specify a type alias (i.e. another name) for an object type:
type Task = {
id: number;
title: string;
description: string;
};
Note that you can specify type aliases for more than just object types since type aliases are basically just different names for types.
For example, we could specify a type alias for the primitive type string:
type ID = string;
Another important point to make about type aliases is that two type aliases are exactly the same as long as the underlying types are the same. For example, this is valid even though it doesn't look like it at first glance:
type MyString = string;
const s1: MyString = 'My string';
const s2: string = s1;
This is because TypeScript uses a structural type system—it doesn't matter what the types are named (except for the primitive types of course), it only matters what their structure looks like.
Note that you can also use the interface keyword to achieve a similar effect:
interface Task {
id: number;
title: string;
description: string;
}
We will stick to always using type.
The interface keyword is out of scope for this book and will not be discussed further.
We briefly note that
typeandinterfaceare not exactly the same and have a few subtle, but important differences. Again, we will not discuss this further.
Type Assertions
Sometimes, you know more about the type of a variable than TypeScript.
For example, let's say that you have a function that returns an any value, but for some reason you know that in fact that value is definitely going to be a string in your case.
Then you can use a type assertion (also called a type cast) to force TypeScript to treat that value as a string.
Here is a (slightly contrived) example:
const str: any = 'This is a string';
const strLength = (str as string).length;
You should use type assertions sparingly since you give up some of the benefits of using TypeScript. Usually there are better ways.
Annotating Functions
— Ancient Chinese proverb
Annotating Parameters
We can annotate functions in TypeScript by annotating their parameters.
Consider a function greet that takes a parameter name of type string and simply outputs a greeting to the console.
Here is how we would annotate the function:
function greet(name: string) {
console.log(`Hello, ${name}`);
}
Now arguments to the function will be checked against our annotation:
greet(false);
// This will result in a type error
You can annotate functions that expect arrays or objects by simply using the syntax you learned in the previous section:
function showTask(task: { id: number; summary: string; description: string }) {
console.log(
`Task with ID=${task.id} has the summary ${task.summary} and description ${task.description}`,
);
}
This is not particularly readable. Here, type aliases come in handy:
type Task = {
id: number;
summary: string;
description: string;
};
function showTask(task: Task) {
console.log(
`Task with ID=${task.id} has the summary ${task.summary} and description ${task.description}`,
);
}
Note that TypeScript will not just check that the passed arguments have the correct types, but also check that the correct number of arguments was passed. This has an interesting side effect—introducing the TypeScript compiler in a JavaScript codebase can reveal bugs without any further work:
function showTask(task) {
console.log(
`Task with ID=${task.id} has the summary ${task.summary} and description ${task.description}`,
);
}
// Uh-oh, we are passing multiple variables instead of a single object!
showTask(1, 'Read the Next.js book', 'Read and understand the Next.js book.');
If we run tsc --strict on this code, we will get the following error:
index.ts:8:13 - error TS2554: Expected 1 arguments, but got 3.
8 showTask(1, 'Read the Next.js book', 'Read and understand the Next.js book.');
Quite nifty indeed!
Return Type Annotations
We can also annotate the return types of our functions:
function getGreeting(name: string): string {
return `Hello, ${name}`;
}
Note that you usually don't need a return type annotation because TypeScript can do type inference for return types:
function getGreeting(name: string) {
return `Hello, ${name}`;
}
Nevertheless, return types are often typed explicitly to avoid accidentally returning a type you didn't want to return or to prevent accidental changes to the return type.
Optional Parameters
Similar to object properties, function parameters can be marked as optional.
In this case we can, but don't need to pass the corresponding argument to the function.
If a parameter is marked as optional, the corresponding argument might also be undefined:
function getGreeting(name: string, message?: string): string {
return `${message !== undefined ? message : 'Hello'}, ${name}`;
}
// These are all valid
getGreeting('John Doe');
getGreeting('John Doe', undefined);
getGreeting('John Doe', 'Welcome');
Function Type Expressions
Sometimes, you need to create a type that specifies a function itself, instead of just its parameters or its return type.
For example, you might want to say that f is a function that takes two strings and returns a string.
You can achieve this with a function type expression:
let f: (x: string, y: string) => string;
The parameter names are required here, if you write (string, string) => string then TypeScript will think that you have a function with two parameters named string of type any.
This syntax is very useful for typing higher-order functions:
function getGreeting(name: string, greeter: (name: string) => string) {
return greeter(name);
}
const myName = 'John Doe';
const greeter = (name: string) => `Hello ${name}`;
console.log(getGreeting(myName, greeter));
One interesting consequence of the way TypeScript inference works, is that parameters of functions can often be inferred.
Let's change this example and make an anonymous function out of greeter:
function getGreeting(name: string, greeter: (name: string) => string) {
return greeter(name);
}
const myName = 'John Doe';
console.log(getGreeting(myName, (name) => `Hello ${name}`));
Note how we no longer need to explicitly specify the type of name in the anonymous function—TypeScript has automatically inferred it to be of type string.
Union Types
— Ancient Chinese proverb
Literal Types
A literal type is a type whose only value is a literal.
Here is how we could define a literal type 'Todo':
type TodoType = 'Todo';
Here is how we can use it:
let todo: TodoType = 'Todo';
Note that we can't assign any other value to todo including other strings.
For example, this isn't possible:
let todo: TodoType = 'Done';
// This will result in a type error
We could also skip declaring the type alias and just use the literal type directly:
let todo: 'Todo' = 'Todo';
It should be noted that if we declare a variable, then by default TypeScript will infer it as a string.
This makes sense since we could change the variable later:
let todo = 'Todo';
// Without the explicit type annotation, todo is a string
However, if we declare a constant, then by default TypeScript will infer a literal type. This also makes sense since we can't change the constant later:
const todo = 'Todo';
// Even without the explicit type annotation,
// todo now has the literal type 'Todo'
While literal types by themselves are not very helpful, they become extremely useful in the context of union types.
Unions of Literal Types
A union type is a type that represents a value which may be one of multiple types.
Consider a type TaskState which represents one of the following states:
- Todo
- InProgress
- Done
Here is how we would define the TaskState type:
type TaskState = 'Todo' | 'InProgress' | 'Done';
The TaskState type is a union type and each of the literal types 'Todo', 'InProgress' and 'Done' is a member of the union.
A variable of type TaskState can only be of one of these literal types, i.e. it can only have one of the respective values.
For example these assignments are all valid:
const state: TaskState = 'Todo';
const state2: TaskState = 'InProgress';
const state3: TaskState = 'Done';
On the other hand, this assignment isn't valid:
const invalidState: TaskState = 'Dropped';
Other Union Types
We can also declare unions of arbitrary types.
The general syntax for declaring a union type is Type1 | Type2 | Type3 | ... and a value of this union type can have the type Type1 or Type2 or Type3 etc.
The various types Type1, Type2, Type3 etc are called members of the union.
One particularly common union type is T | undefined.
Consider this example:
function getTaskId(taskName: string): string | undefined {
// Implementation here
}
This function takes a taskName and returns the corresponding ID.
Because we might discover that no task with the given name is present, we return either a string or undefined.
Working with a Union Type
It should be clear by now how we can define a union type, but how can we work with a union type? Consider the following function:
function logTaskName(taskName: string | undefined) {
console.log({
taskName,
taskNameLength: taskName.length,
});
}
Compiling this example will result in the following error:
index.ts:4:21 - error TS18048: 'taskName' is possibly 'undefined'.
4 taskNameLength: taskName.length,
~~~~~~~~
Found 1 error in index.ts:4
TypeScript will only allow to do an operation with the value of a union type if that operation is valid for every member of the union.
Since taskName can be either a string or undefined, we can't access .length on it, because .length is not a valid property of undefined!
Instead we need to perform type narrowing where we narrow the type of a variable with code.
Basically, TypeScript can look at our code and understand that in certain code parts a value of a union type can only have the type of a particular member of the union.
The simplest way of narrowing a type is equality narrowing.
Here we use the === or !== operators to narrow a type.
Consider this example:
function logTaskName(taskName: string | undefined) {
if (taskName !== undefined) {
console.log({
taskName,
taskNameLength: taskName.length,
});
} else {
console.log('The task is not defined');
}
}
We narrow the type of taskName in the taskName !== undefined branch.
TypeScript will inspect our code and realize that since taskName had the string | undefined type and taskName !== undefined in the truthy branch of the if statement, taskName must be of type string inside that branch (there is simply no other way).
Similarly, in the falsy branch of the if statement (i.e. the else branch), TypeScript will know that taskName must be undefined.
This example also showcases a very important concept: The same variable can have a different type depending on the part of the code we are in. This is not the case in many other programming languages, where a variable will always have the same type once it has been initialized.
Another (similar) way of narrowing a type is truthiness narrowing. Here we use the fact that certain values are truthy or falsy to narrow a type.
Consider this example:
function logTaskName(taskName: string | undefined | null) {
if (taskName) {
console.log({
taskName,
taskNameLength: taskName.length,
});
} else {
console.log('The task is not defined');
}
}
Since undefined and null are both falsy, the taskName in the truthy branch of the if statement can only have the type string and we can use the .length property.
However, truthiness narrowing can lead to subtle bugs due to the way truthy and falsy values work (we covered this in the JavaScript chapter).
Indeed, the function logTaskName has a hard-to-spot error.
Can you see it?
That's right—it doesn't correctly handle the case of the empty string.
After all, the empty string '' is also falsy, therefore logTaskName("") would print that the task is not defined, which is probably not what we were going for.
We could fix the function like this:
function logTaskName(taskName: string | undefined | null) {
if (taskName === '') {
console.log('The task is empty');
} else if (taskName) {
console.log({
taskName,
taskNameLength: taskName.length,
});
} else {
console.log('The task is not defined');
}
}
You should generally be careful when relying on truthiness or falsiness. The way these concepts work in JavaScript can be a bit confusing and it's easy to miss edge cases.
Some people prefer to avoid these concepts altogether and instead provide explicit checks, for example:
function logTaskName(taskName: string | undefined | null) {
if (taskName !== undefined && taskName !== null) {
console.log({
taskName,
taskNameLength: taskName.length,
});
} else {
console.log('The task is not defined');
}
}
The last way of narrowing a type is typeof narrowing.
TypeScript knows how the typeof operator works and you can use it to narrow a type as you would expect:
function processInput(value: string | number): number {
if (typeof value === 'string') {
// Here, value must be a string
return value.length;
} else {
// Here, value must be a number
return value;
}
}
The Non-Null Assertion Operator
You can use the non-null assertion operator to tell TypeScript that a value is definitely not undefined or null:
let input: string | undefined = 'Some string';
let trimmedInput: string = input!.trim();
Just as with type assertions, you should use this sparingly and usually there is a better way.
Type Predicates
We can write user-defined type guards by utilizing type predicates. Consider the following example:
const array = ['Hello', undefined, 'World', undefined];
const filteredArray = array.filter((val) => val !== undefined);
Here array is a (string | undefined)[] and filteredArray removes the undefined elements.
However, the inferred type of filteredArray would still be (string | undefined)[] because TypeScript can't easily inspect the contents of the filter function to realize that we remove the undefined elements.
We could theoretically use a type assertion here:
const array = ['Hello', undefined, 'World', undefined];
const filteredArray = array.filter((val) => val !== undefined) as string[];
However, instead of yelling at the TypeScript compiler that we know better, it's more productive to write a user-defined type guard:
function isString(val: string | undefined): val is string {
return typeof val === 'string';
}
The isString function is a type guard, because it's return type is the type predicate val is string.
Generally, a type predicate must have the form parameter is Type where parameter is the name of a parameter from the function signature.
We can use the type guard like this:
const array = ['Hello', undefined, 'World', undefined];
const filteredArray = array.filter(isString);
Now the inferred type of filteredArray will be string[]—and all that without using a single type assertion.
Discriminated Unions
A particularly important union type is the discriminated union. This is a union where a property is used to discriminate between union members. Consider the following example:
type Square = {
kind: 'square';
size: number;
};
type Rectangle = {
kind: 'rectangle';
width: number;
height: number;
};
type Shape = Square | Rectangle;
We can now narrow values of the discriminated union based on the discriminant property (which in this case is kind):
function getArea(shape: Shape) {
if (shape.kind === 'square') {
// Here, shape must be of type Square
return shape.size * shape.size;
} else {
// Here, shape must be of type Rectangle
return shape.width * shape.height;
}
}
Generics
— Ancient Chinese proverb
Why Generics?
Generics allow us to write code that is type-safe, yet independent of specific types.
Consider the example of retrieving the first element of an array:
function getFirstElement(arr) {
return arr[0];
}
How would we type this?
We could use any:
function getFirstElement(arr: any): any {
return arr[0];
}
However using any is—as we already mentioned—a bad idea since we lose all the type information even if we pass in an array of a known type.
For example, all these constants would be inferred to have type any:
const num = getFirstElement([1, 2, 3]);
const str = getFirstElement(['a', 'b', 'c']);
We also can't use the unknown type since it doesn't permit any operations:
function getFirstElement(arr: unknown) {
// This will result in a type error
return arr[0];
}
We could also make use of function overloads and write something like this:
function getFirstElement(arr: number[]): number;
function getFirstElement(arr: string[]): string;
function getFirstElement(arr: undefined[]): undefined;
// More overloads and implementation here
We will not discuss function overloads in more detail as it's out of scope for this book.
But this obviously gets very tedious and error-prone for most cases. Instead, TypeScript allows us to use generics to specify that some code doesn't depend on the concrete types and only cares about the relation between certain types.
Generic Functions
Consider the identity function that simply takes an argument arg and returns it unchanged.
We can use a type variable Type and type it like this:
function identity<Type>(arg: Type): Type {
return arg;
}
This basically says that the identity function takes an argument of type Type and that its return type is of the same type as the argument.
Now we get proper type inference:
let val = 'Hello, World!';
let val2 = identity<string>(val); // val2 is of type string
We don't actually have to manually specify the type string when calling the function and can instead rely on the inference capabilities of TypeScript once again:
let val = 'Hello, World!';
let val2 = identity(val); // val2 is of type string
There is no single convention for naming type parameters. Common names include
T,TypeandTType. We will stick to theTypeconvention throughout this book.
Similarly, we can type the getFirstElement function using type parameters:
function getFirstElement<Type>(arr: Type[]): Type {
return arr[0];
}
const num = getFirstElement([1, 2, 3]);
const str = getFirstElement(['a', 'b', 'c']);
Unlike in the getFirstElement example that was typed using any, we now get meaningful type inference.
For example, num will have the type number (instead of any) and str will have the type string.
You can use any number of type parameters you want.
Here is how we could write a correctly annotated map function:
function map<In, Out>(array: In[], f: (value: In) => Out): Out[] {
return array.map(f);
}
Here, we have two type parameters In and Out.
The type parameter In indicates the types of the elements of the original array.
The type parameter Out indicates the types of the elements of the result array.
Note how the type of the parameter f makes uses of both the In and Out parameter types.
This makes sense since f transforms an element of the original array (In) into an element of the result array (Out).
Again, we will get proper type inference:
const arr = map([1, 2, 3, 4], (x) => x % 2 === 0);
Here arr will have the type boolean[].
Generic Object Types
Just as with functions, we can use type parameters with objects:
type Box<Type> = {
content: Type;
};
Now we can use the Box type with any type:
// Here, box has the type Box<number>
const box = {
content: 0,
};
// Here, box2 has the type Box<string>
const box2 = {
content: 'Hello, world!',
};
We can also use generic functions and objects together:
function extractContent<Type>(box: Box<Type>): Type {
return box.content;
}
Important Builtin Generics
Generic object types are often useful for collections (and containers), since collection logic is often independent of the specific item types.
For example, retrieving the first element of an array or finding an element of a set by value using the === operator will work the same way regardless of the types of the array or set elements.
You already learned about generic arrays (note that you can use Array<T> in place of T[]).
If you have an object type where the property keys have a certain known type and the property values have a certain known type, you can use the generic type Record<Key, Value>
const ScoreRecord: Record<string, number> = {
Alice: 50,
Bob: 60,
Charlie: 70,
};
Two other generic data structures that you already know about are sets and maps:
const mySet: Set<number> = new Set([1, 2, 3]);
const myMap: Map<string, number> = new Map([
['Item 1', 1],
['Item 2', 2],
]);
This example can also be written like this:
const mySet = new Set<number>([1, 2, 3]);
const myMap = new Map<string, number>([
['Item 1', 1],
['Item 2', 2],
]);
One other very important generic type is the Promise<Type> type which is most commonly used to annotate asynchronous functions.
For example, if we have an asynchronous function f that returns a promise that will eventually fulfill with a string, we would annotate it like this:
async function f(): Promise<string> {
// Implementation here
}
Generic Constraints
Often, we don't want to pass completely arbitrary type parameters.
Consider this example:
function getLength<Type>(arg: Type): number {
return arg.length;
}
This will throw the following error:
index.ts:2:14 - error TS2339: Property 'length' does not exist on type 'Type'.
2 return arg.length;
~~~~~~
Found 1 error in index.ts:2
This makes sense since arg can be of literally any type and there is no guarantee that arg will actually have the property length.
To change this, we need to constrain the type Type and make sure that arg must have the length property:
function getLength<Type extends { length: number }>(arg: Type): number {
return arg.length;
}
As usual, we can use a type alias here:
type HasLength = {
length: number;
};
function printLength<Type extends HasLength>(arg: Type): number {
return arg.length;
}
Configuring TypeScript
— Ancient Chinese proverb
Creating a TypeScript Project
We already learned how to create and run individual TypeScript files. However, as with JavaScript, we will usually be working with larger projects.
Let's create a JavaScript project and add TypeScript support to it.
First, we create a directory where our project will reside:
mkdir example
cd example
Next, we need to create the package.json file to indicate that this directory should be a JavaScript project:
pnpm init
This will create a package.json file containing the project settings:
{
"name": "example",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Next, let's create a tsconfig.json to indicate that this particular project will use TypeScript:
{
"compilerOptions": {
"strict": true
}
}
Setting the strict option in compilerOptions is equivalent to running tsc with the --strict flag.
We will talk about this option in some more detail later.
We could have also created the
tsconfig.jsonfile by runningtsc --init, however this will add a lot of options that we really don't care about at the moment.
Now, let's create an index.ts file:
function getGreeting(name: string): string {
return `Hello, ${name}!`;
}
console.log(getGreeting('World'));
Finally, we can compile the code:
tsc
This will create approximately the following index.js file:
'use strict';
function getGreeting(name) {
return 'Hello, '.concat(name, '!');
}
console.log(getGreeting('World'));
We can execute this file the same way we would execute any other JavaScript file:
node index.js
There is one small modification we need to make to this process.
While using the globally installed TypeScript compiler is fine if you have a single project, you often might need to work on multiple projects at the same time.
Since these projects might use different TypeScript versions, we usually want to install tsc on a per-project basis.
Let's therefore install tsc as a dev (development) dependency (since we will not need it in the final code output):
pnpm add --save-dev typescript
This will install TypeScript only for this particular project.
We can now run the tsc that was installed for this project using the following command:
pnpm tsc
Using Modules in a TypeScript Project
Now that we know how to create TypeScript projects in general, let's quickly talk about how we can use modules in TypeScript projects.
This process will be very similar to what we learned about JavaScript modules, except that we may need to make minor modifications to the tsconfig.json file.
Create a src directory containing the files greet.ts and index.ts.
You overall project structure should now look as follows:
.
├── package.json
├── pnpm-lock.yaml
├── tsconfig.json
├── node_modules/
└── src/
├── index.ts
└── greet.ts
Add the following exported function to greet.ts:
export function getGreeting(name: string): string {
return `Hello, ${name}!`;
}
Now, let's use getGreeting in index.ts:
import { getGreeting } from './greet';
console.log(getGreeting('World'));
We could theoretically compile our project using this setup already.
However we will make a small modification to our tsconfig.json to avoid polluting the src directory with our compilation outputs.
To this end, we utilize the outDir option, which specifies the output directory, where TypeScript will put the compilation result.
Change your tsconfig.json file to be as follows:
{
"compilerOptions": {
"strict": true,
"outDir": "./dist"
}
}
We can now compile again:
pnpm tsc
The project structure looks like this now:
.
├── package.json
├── pnpm-lock.yaml
├── tsconfig.json
├── node_modules/
├── src/
│ ├── index.ts
│ └── greet.ts
└── dist/
├── index.js
└── greet.js
The files from src were successfully compiled and the compilation output is in dist.
We can now execute index.js by running:
node ./dist/index.js
You should see "Hello, World!" logged to the console.
Including and Excluding Files
Sometimes you want to include or exclude certain files from being processed by the TypeScript compiler.
To accomplish this, you can specify the include or exclude parameters in the tsconfig.json.
The include option takes an array of filenames or patterns to include in the program (relative to the directory containing the tsconfig.json file).
For example, we could include all files in src directory by setting include to ["src/**/*"].
The src/**/* notation is a so called glob pattern.
Here, * matches zero or more characters (excluding directory separators) and **/ matches any directory (with arbitrary nesting).
Therefore, src/**/* means "match any file in the directory src and all its subdirectories (no matter how deeply nested)".
Note that by default
includeis set to["**/*"](i.e. it's set to match all files including arbitrarily nested subdirectories).
The exclude parameter specifies an array of filenames or patterns that should be skipped when resolving include.
It is important to note that the exclude parameter does not necessarily exclude the file from your codebase—a file specified by exclude can still become part of your codebase if you import it somewhere.
The exclude parameter only changes which files are found by the include option.
Consider the following example.
Let's say that you have a bunch of *.test.ts files containing tests, like the following greet.test.ts:
import { getGreeting } from './greet';
function testGreeting() {
if (getGreeting('World') !== 'Hello, World!') {
throw new Error('Test failed');
}
}
This is not how we would really write a test, but that's irrelevant for now.
If we would run pnpm tsc right now, we would see the we have greet.test.js in the output which is probably not desirable, since the tests probably shouldn't be part of the final compilation output.
Therefore we could write the following tsconfig.json:
{
"include": ["src/**/*"],
"exclude": ["src/**/*.test.ts"],
"compilerOptions": {
"strict": true,
"outDir": "./dist"
}
}
If we delete the dist directory and run pnpm tsc again, we will see that greet.test.js is no longer present.
Compiler Options
There a lot of compiler options that we can set in the compilerOptions section of tsconfig.json besides strict and outDir.
Let's discuss some of them.
The strict Option
The strict option enables a wide range of—well—strict type checking.
Here is some example code that contains a few type issues:
function getNumber(): number | undefined {
return Math.random() > 0.5 ? 0 : undefined;
}
function logNumber(n: number) {
console.log(n);
}
function logAny(x) {
console.log(x);
}
const number = getNumber();
logNumber(number);
logAny(number);
If we set strict to false (which it is by default), this code will (surprisingly) compile.
However, if we turn strict on, we get the errors that you would expect if you remember what you've learned in the previous sections of the TypeScript chapter:
src/index.ts:9:17 - error TS7006: Parameter 'x' implicitly has an 'any' type.
9 function logAny(x) {
~
src/index.ts:14:11 - error TS2345: Argument of type 'number | undefined' is not assignable to parameter of type 'number'.
Type 'undefined' is not assignable to type 'number'.
14 logNumber(number);
~~~~~~
Found 2 errors in the same file, starting at: src/index.ts:9
You should always turn strict on, unless you have a really good reason not to (for example because you are migrating from a JavaScript or a very old TypeScript codebase).
The target Option
Remember, how we talked about downleveling in the first section of this chapter?
The target option changes which JS features are downleveled and which are left as is.
For example, if target is es5 template strings will be downleveled, but if it's es2015 (equivalent to es6) they won't be, because template strings were introduced in ES2015.
Take this code:
const world = 'World';
console.log(`Hello ${world}`);
If target is set to es5, it would compile to this:
'use strict';
var world = 'World';
console.log('Hello '.concat(world));
If target is set to es2015, the compilation output would look like this:
'use strict';
const world = 'World';
console.log(`Hello ${world}`);
This is because with target set to es5 the template string had to be downleveled.
Some valid targets are:
es5es2015(equivalent toes6)es2016up toes2022
There is also the esnext target which refers to the highest version of TypeScript.
This target should be used with caution since it means different things between different TypeScript versions.
Modern browsers support all es6 features, so es6 is often a good choice.
You might choose to set a lower target though if your code is deployed to older environments.
Alternatively, you might choose a higher target if your code is guaranteed to run in newer environments.
The lib Option
The lib option allows you to specify libraries to be included in the compilation.
Basically, you can use this to let TypeScript know which APIs will be available in the runtime environment.
Let's say we have this code which would only work in the browser since it attaches an event listener to the browser document:
document.addEventListener('DOMContentLoaded', () => {
console.log('DOM has loaded');
});
If we set lib to ["es2015"], we will get a bunch of compilation errors:
src/index.ts:1:1 - error TS2584: Cannot find name 'document'. Do you need to change your target library? Try changing the 'lib' compiler option to include 'dom'.
1 document.addEventListener('DOMContentLoaded', () => {
~~~~~~~~
src/index.ts:2:5 - error TS2584: Cannot find name 'console'. Do you need to change your target library? Try changing the 'lib' compiler option to include 'dom'.
2 console.log("DOM has loaded");
~~~~~~~
Found 2 errors in the same file, starting at: src/index.ts:1
But if we set lib to ["es2015", "dom"] the compilation errors go away since TypeScript now introduces the DOM types into the compilation process.
The noEmit Option
The noEmit option can be set to true to not produce JavaScript output.
This makes room for another tool to convert the TypeScript files to something that can be run inside a JavaScript environment.
This is often done when we only want to use TypeScript as a type checker (as is common in many projects) or to provide suggestions in your coding editor.
An Example tsconfig.json
You now learned about some of the most important tsconfig.json settings!
Here is an example tsconfig.json to summarize your newfound knowledge:
{
"include": ["src/**/*"],
"exclude": ["src/**/*.test.ts"],
"compilerOptions": {
"strict": true,
"noEmit": true,
"target": "es2015",
"lib": ["es2015", "dom"]
}
}
In this case, we don't produce compilation output, but only type check the code (due to noEmit being true).
We only look at the files in src and its subdirectories, ignoring the *.test.ts file (because of the include and exclude setting).
Finally, the type checking process is strict (due to noEmit being true), all features that are not available before ES2015 will be downleveled (since target is es2015) and we can use the DOM API types.
Reusing a tsconfig.json
The extends option can be used to inherit from another configuration file.
For example, we might have a base.json configuration file like this:
{
"compilerOptions": {
"strict": true
}
}
Now, the tsconfig.json could extend this file:
{
"extends": "base.json",
"include": ["src/**/*.ts"],
"compilerOptions": {
"noEmit": true
}
}
The resulting configuration would be strict and not emit JavaScript files.
This feature is particularly useful because it allows someone to write a TypeScript configuration file that specifies the settings that should be applied to TypeScript codebases in a company or a project and then everyone can simply extend this configuration file.
Chapter 3: Networking Fundamentals
— Seconds before disaster
Now that you've learned a bit of programming, we're almost ready to start diving into writing web applications. However, before we can do so, we need to introduce a couple of networking concepts. If you don't know what an IP address is or how an HTTP request works, it will be very hard to get things done, which is what this book is really about.
Don't worry, this won't be a university course—we will only touch the concepts that are absolutely necessary to understand the later chapters.
IPs, Ports and Domains
— Seconds before disaster
Network Interfaces
Network interfaces are the mechanism your computer uses to connect to a network. Network interfaces can correspond to physical objects like a network interface controller (the hardware component that allows a computer to connect to a network via a cable or wireless connection). They can also be virtual, i.e. only exist in software.
Protocols
A protocol defines the rules by which the network interfaces communicate. Protocols allow computers to "speak the same language".
The internet knows a lot of different protocols—from really common ones like IP, HTTP, HTTPS or DNS to really exotic ones that are only relevant for a select group of specialists.
For example, if you're browsing http://example.com, the underlying protocol is HTTP.
Similarly, if you browse https://www.google.com/, the underlying protocol is HTTPS.
Protocols can also use other protocols. For example, the HTTP protocol uses the TCP protocol which in turn uses the IP protocol.
The IP Protocol
The IP protocol powers a large portion of the modern web. Its most important concept is the so-called IP address.
Note that there are two versions of the IP protocol—the IPv4 protocol and the IPv6 protocol. We will only talk about the IPv4 protocol and ignore the IPv6 protocol in this book.
An IPv4 address (or simply IP for short) is an identifier that is assigned to a network interface on your computer. For example, your wireless network interface might have an IPv4 address that it can use to communicate with other computers on the same wireless network.
Such an address consists of 4 numbers between 0 and 255, separated by dots.
Therefore, IP addresses look like 123.56.1.17 or 192.168.178.47.
Note that instead of saying that a network interface has a particular IP, we will often say that a computer has some IP. This is because often we only really care about a particular interface (usually your Ethernet or your wireless interface). However, it's important to understand that different network interfaces will usually have different IP addresses even if they're located on the same machine.
The loopback address 127.0.0.1 is a special IP address which can be used to identify the machine you're currently on.
You can basically use this to talk to your own computer.
For example, if you run a local web server, you could access it at 127.0.0.1.
Additionally, some IP addresses are designated as private addresses, i.e. they can only appear on local networks and can't be used on the public internet. The Internet Assigned Number Authority (IANA) has reserved the following blocks of IP addresses for private networks:
10.0.0.0-10.255.255.255172.16.0.0-172.31.255.255192.168.0.0-192.168.255.255
This has the important consequence that if you're on a local network you usually won't be able to access a machine from another local network using its private address.
For example, let's say that you're in your home network and you've finally managed to host a web server on your machine which has the IP address 172.16.32.155.
Full of excitement, you send a link to your friend Alice (who is on her home network), only for her to tell you that she can't reach your IP address.
The problem is that your machine is only reachable at 172.16.32.155 from your home network and can't be reached under that address from any other network.
Therefore, if you want your machine to be reachable from anywhere it needs to have a public address.
A public address is basically any address that hasn't been explicitly marked as private.
For example, 142.251.37.14 is a public address since it's not in one of the private address blocks.
There are a few other special address blocks like the "link local" block. However, they won't be important for this book and therefore we'll simply skip over them.
Ports
Usually, you want to be able to run multiple networking services on your machine. This poses the problem of uniquely identifying those services. After all, if they all share the same IP, how can we distinguish them from one another?
The answer is that we can use ports. A port is simply a number assigned to uniquely identify a connection endpoint on a machine.
Let's say you want to have a web service and an ssh service running on the same machine.
The
sshprotocol allows you to remotely log in to a computer and execute commands on it.
You could assign the web service the port 443 and the ssh service the port 22.
Even though these services run on the same machine with the same IP, they can be distinguished from each other by their port number.
If a service is assigned some port, programmers often say that the service is listening (for incoming connections) on that port.
In our example, the web service would be listening on port 443 and the ssh service would be listening on port 22.
If you want to specify an IP and a port together, you use the colon : notation.
For example, if you have an HTTPS web server running on a machine with the IP 123.56.1.17 and you have assigned the port 443 to the web server, it would be reachable at 123.56.1.17:443.
If we add the protocol (HTTPS), we would get the correct URL for the web server, which would be
https://123.56.1.17:443. We will talk about URLs in more detail soon.
Similarly, if you start an HTTP web server locally (i.e. on 127.0.0.1) on port 80, you could access it at 127.0.0.1:80.
If we add the protocol (HTTP), we would get the correct URL for the web server, which would be
http://127.0.0.1:80.
There is a list of well-known ports.
For example, an HTTP application typically runs on port 80 while an HTTPS application typically runs on port 443.
This is why you don't need to explicitly tell your browser that google.com can be found at port 443—your web browser will figure this out automatically because 443 is a well-known port.
During development we will not follow this convention and mostly run our applications on port
3000. This is because you don't need special "root" permissions to run something on port3000. Typically, ports below1024are considered "privileged" and require these special permissions. However, when we deploy our final application to production, it will run on the well-known port443.
Domains
While IP addresses are great, they are very unwieldy and hard to remember for humans.
Imagine that instead of "just google it" or "go to google.com" you would have to tell someone to "go to 142.251.37.14".
That would suck!
This is why the concept of a domain was introduced. A domain is a string that identifies some network resource. In our neat and tidy web development world, a domain usually has a corresponding IP address.
For example, the domain google.com might correspond to the IP address 142.251.37.14.
That is, you can identify the resource either via google.com or via 142.251.37.14.
The translation of domains to IP addresses is handled by the Domain Name System (DNS) protocol.
If you type google.com into your browser address bar, DNS will translate it to the correct IP under the hood.
The reality is much more complicated and involves something called DNS records. This means that domains can have IPv4 addresses, IPv6 addresses, mail addresses etc. Domains can also be forwarded to other domains with so-called CNAME records. The picture becomes even more complicated once we go into load balancing. Nevertheless, for our purposes the mental model of "there are domains and they correspond to IP addresses" is enough.
A special domain is localhost which resolves to 127.0.0.1.
This means that if you want to access a locally running HTTP web server on port 3000, you would need to go to localhost:3000 or, more specifically, http://localhost:3000.
An HTTP Primer
— Seconds before disaster
Servers and Clients
Servers and clients are nothing more than regular programs (like the ones you saw in the first chapter). For example, a server might be a JavaScript program that waits for HTTP requests and sends back responses. A client might be a browser on your laptop or your phone—it might even be a regular script.
Often, the term "server" is also used to refer to the actual machine the software is running on.
The distinction between a client and a server is extremely important, because the location of our code (i.e. whether it's on the client or the server) will determine what features we can use. We've already mentioned this in the JavaScript chapter.
For example, if your code runs on the client, you won't (for example) have access to the filesystem. However, you will have access to various browser features. For instance, you could add a new element, get the size of the browser window and so on.
If your code runs on the server, you will have access to the filesystem, but you won't have access to the browser features. This makes sense since the browser is running on your client and the server (mostly) doesn't have access to it.
This also means that we will often need to transmit data from the client to the server (and the other way around). When writing a web application, the most common way to do so is by using the HTTP protocol.
Requests and Responses
The HTTP protocol is a request/response protocol, i.e. HTTP clients send requests to an HTTP server and receive responses in return.
You have in fact already used the HTTP protocol. Pretty much every time you browse the internet, HTTP requests are sent under the hood.
The usual request-response lifecycle looks like this:
First, the user interacts with your web application, e.g. by submitting a form, clicking a button etc.
Second, the client sends an HTTP request to the server that contains information about resources to retrieve, data to send etc.
Third, the server receives the request, reads its data and then performs appropriate calculations, database queries and so on. Afterwards, the server creates a response and sends it back to the client.
And, finally, the client looks at the response and determines how to update the UI (user interface).
HTTPS
We should mention that nowadays developers never use plain HTTP in production. Instead, they use the HTTPS protocol, which is encrypted HTTP.
HTTPS basically wraps HTTP in a layer of encryption using a method called TLS (Transport Layer Security). This allows encrypting your traffic such that an adversary spying on your network won't be able to read the content you're sending over the network. This is a really good thing especially if we're talking something like your bank passwords—you certainly want to keep that information protected!
We won't cover HTTPS in more detail, since that will automatically be handled for us by our web hosting provider that we will use later on.
HTTP and Express
We could use the built-in HTTP module of Node.js, but this is not terribly convenient. Instead we will use an extremely popular framework called Express. While Express builds on top of the HTTP module, it provides a lot of additional useful functionality.
Create a new Node.js project inside a directory on your computer:
pnpm init
Install Express:
pnpm add express
Create a file named app.js inside the directory.
In that file we will create an Express application and then make that application listen for connections on a specified host and port.
This is how you can create an Express application and make it listen on port 3000:
const express = require('express');
const app = express();
const PORT = 3000;
app.listen(PORT, () => {
console.log(`Server listening on port ${PORT}...`);
});
This application is not very useful, so let's add a route to it.
Add the following code above the call to listen:
app.get('/', (req, res) => {
res.send('Hello, world!');
});
Start the application:
node app.js
If you open a browser and navigate to http://localhost:3000 you will see
Hello, world!
You can also use cURL, which includes a command-line tool for transferring data on a network. Among other things it supports HTTP and is available on pretty much every mainstream operating system out there.
Open a command line and run:
curl http://localhost:3000/
This will output the following:
Hello, world!
Note that you will need to press Ctrl + C in your command line to stop the server.
HTTP URLs
The string http://localhost:3000/ is a so-called URL.
You have already seen URLs in the previous section.
Navigate to Google and search for "Next.js"—you will notice that the URL in your browser looks like this:
https://www.google.com/search?q=nextjs
For didactic reasons we will include the port:
https://www.google.com:443/search?q=nextjs
Generally speaking, a typical HTTP(s) URL has the following form:
scheme://host:port/path?key1=value1&key2=value2#fragment
Note the word typical here. HTTP URLs (and especially more general URLs) can become much more complicated, but we will not cover all the little details in this book. In fact, the complexity of URLs is often a source of subtle bugs and browser crashes. For example—at some point Android Chrome would crash when trying to open
http://../foo.
Let's go over the individual component of a typical URL one by one.
The scheme usually indicates the protocol which describes how information should be transmitted.
We will almost exclusively use HTTP or HTTPS in this book.
Therefore, the scheme will almost always be either http or https.
In the above Google URL the scheme is clearly https.
You've already learned about the host and the port—the host identifies the device you wish to connect to and the port is the communication endpoint on that device.
Note that the host could be a domain (like www.google.com) or an IP address (like 142.251.36.238).
Usually we will work with domains since they're stable and rarely change (unlike some IP addresses).
At the time of this writing
142.251.36.238is one of Google's IP addresses. This may of course change by the time you are reading this book.
The next part is the path.
Assuming it's not empty, the path begins with a forward slash / and uniquely identifies the resource we want to query.
In the Google URL, the path is /search.
Often, paths will be hierarchical.
In this case the different components of the hierarchy are generally separated by slashes, e.g. /path/to/resource.
The path can be followed by a query.
The query begins with a question mark and is followed by key-value pairs.
In the Google URL, the query is given by ?q=nextjs.
Here, the query provides information about your search.
If there are multiple key-value pairs, they're separated by ampersands &.
For example, a query might look like ?key1=value1&key2=value2.
The query can be followed by a fragment.
This is used for navigation by the client and is not sent to the server.
A fragment begins with the # character, e.g. ?key1=value1&key2=value2#fragment.
For example, if you go to a Wikipedia article and click a heading in the table of contents, you will be navigated to that heading and a fragment will be appended to the URL in your browser address bar.
GET and POST requests
HTTP knows many request methods. We primarily care about two request methods for now—namely GET and POST.
GET requests are generally used to retrieve data.
Recall our route from above:
app.get('/', (req, res) => {
res.send('Hello, World!');
});
This indicates that if a GET request is sent to the path /, we would like to return 'Hello, World!' to the client.
The req variable represents the request object and res represents the response object.
If we want to send a HTTP response to the client we use the res.send method.
POST requests are generally used to send information to instruct the server to create a new resource or update an existing resource. For example, a login request will generally be a POST request since it tells the server that a user has logged in to the application. Similarly, if you submit a web form, there will usually be a POST request attached to that, since form submissions carry new information.
With POST requests, we're more interested in telling the server that something happened than in the data the server returns to us.
POST requests usually need to send much more information to the server than GET requests. Therefore, POST requests can have a request body which allows us to carry this additional data when sending a request.
Let's have a look at an example. Note that we need to enable some middleware in our script. Middleware functions are functions that do some additional processing on requests or responses.
Specifically, we will need to use the express.text() middleware function to parse incoming request payloads into a string.
Add the following line of code to your script right after the initialization of the app variable:
// code
const app = express();
const PORT = 3000;
app.use(express.text());
// more code
Consider the following route which simply returns the request body back to the client:
app.post('/echo', (req, res) => {
res.send(req.body);
});
We can send a POST request via curl.
We need to specify that we want to send a POST request using the -X flag.
Additionally, we can specify the data that we want to send in the body of the POST request using the -d flag.
Finally, we specify a header called Content-Type and set it to text/plain.
This indicates that the data we want to send is plain text.
The final command looks like this:
curl -X POST -H "Content-Type: text/plain" -d 'test' http://localhost:3000/echo
Generally speaking, GET requests transmit information in the URL, while POST requests transmit information in the request body.
Note that we will rarely send plain text in the request. Instead, we will usually use the JSON format that we've already introduced in the JavaScript chapter.
In order to accept JSON requests, we need to replace the express.text middleware with the express.json middleware:
app.use(express.json());
Now we can curl the /echo path like this:
curl -X POST -H "Content-Type: application/json" -d '{ "key": "value" }' http://localhost:3000/echo
Note that here we need specify the application/json content type instead of the text/plain content type.
More on HTTP
— Seconds before disaster
Status Codes
Responses can have status codes attached to them. These indicate the status of a request.
Each status code is a number that indicates some information about the response.
For example, the status code 400 represents a Bad Request.
There are a lot of status codes and they're grouped in five classes:
- the status codes
100-199indicate informational responses (and you'll rarely see them) - the status codes
200-299indicate successful responses - the status codes
300-399indicate redirection responses - the status codes
400-499indicate client errors - the status codes
500-599indicate server errors
Quoting the famous HTTP status ranges in a nutshell, you could also rephrase this as:
100-199: hold on200-299: here you go300-399: go away400-499: you fucked up500-599: I fucked up
Let's have a quick look at the most important status codes.
The status code 200 (OK) is the standard response for a successful HTTP request.
The status code 201 (Created) is often used for requests where a resource has been successfully created.
The status code 400 (Bad Request) means that the server can't process the request due to a client error.
For example, a 400 should be returned if the client has provided the server with a malformed request.
The status code 401 (Unauthorized) usually means that the client couldn't be successfully authenticated.
The status code 403 (Forbidden) usually means that the client doesn't have the necessary rights to access the requested content.
Note that there is an important difference between 401 and 403.
The code 401 means that the client couldn't be authenticated at all, the code 403 means that the client could be authenticated, but doesn't have the correct access rights.
You've probably heard of the most famous status code 404 (Not Found).
As the name already says, this means that the server can't find the requested resource (usually because the resource doesn't exist).
The status code 405 (Method Not Allowed) means that the resource exists, but the client is trying to access it using the wrong method.
This occurs if, for example, a client is trying to send a GET request to a route that only supports POST requests.
The most important status codes for server errors are 500 (Internal Server Error) and 503 (Service Unavailable).
The status code 500 basically indicates a server crash, while 503 indicates that the server is overloaded.
Here is how you can manually return a status code in Express:
app.post('/', (req, res) => {
const data = req.body;
// If the request body is empty, we return status code 400 (Bad Request)
if (Object.keys(data).length === 0) {
res.status(400).send('Bad Request: No data provided');
} else {
res.status(201).send(`Received data: ${JSON.stringify(data)}`);
}
});
Try to curl the endpoint both with an empty and a non-empty object.
For example, you can curl the endpoint with an empty object like this:
curl -X POST -H "Content-Type: application/json" -d '{}' -w '\nStatus: %{http_code}' http://localhost:3000
The output would be:
Bad Request: No data provided
Status: 400
Let's also curl the endpoint with a non-empty object like this:
curl -X POST -H "Content-Type: application/json" -d '{"key": "value"}' -w '\nStatus: %{http_code}' http://localhost:3000
The output would be:
Received data: {"key":"value"}
Status: 201
Headers
Both requests and responses can have headers which provide important information that is not part of the main request or response content. For example, request headers might contain the version of the browser that is making the request, what languages are accepted, what encodings are accepted etc.
Here is how you can read request headers in Express:
app.get('/request-header-example', (req, res) => {
const customHeaderValue = req.get('Custom-Header');
if (customHeaderValue) {
const responseData = { 'Received-Custom-Header': customHeaderValue };
res.send(`Received data: ${JSON.stringify(responseData)}`);
} else {
res.status(400).send('No Custom-Header provided');
}
});
You can set a header in curl like this:
curl -H "Custom-Header: ExampleValue" http://localhost:3000/request-header-example
You will receive the following response:
Received data: {"Received-Custom-Header":"ExampleValue"}
Similarly, response headers might contain the type of the content, the date of the response etc.
Here is how you can set response headers in Express:
app.get('/response-header-example', (req, res) => {
const data = req.body;
// Add a custom header
res.set('X-Custom-Header', 'MyHeaderValue');
res.status(201).send(`Received data: ${JSON.stringify(data)}`);
});
You can see the response headers in curl by using the -i flag:
curl -i http://localhost:3000/response-header-example
This will output:
HTTP/1.1 201 Created
X-Powered-By: Express
X-Custom-Header: MyHeaderValue
Content-Type: text/html; charset=utf-8
Content-Length: 17
ETag: W/"11-10nwzUtYNUZcrMxeVU7fTdmCYaI"
Date: Thu, 14 Mar 2024 11:23:03 GMT
Connection: keep-alive
Keep-Alive: timeout=5
Received data: {}
Note that Express and other web frameworks already set quite a few response headers by default.
You can also see the response headers in the network tab of your browser if you click on an individual request.
Cookies
HTTP cookies are pieces of data that are created by the server, sent to the browser and then saved on the browser. Cookies can be used for things like authentication, personalization and tracking.
For example, the server might generate a cookie for a logged in user, send it to the browser and then the browser could send the cookie with each request (avoiding the need for the user to log in on every request).
Note that cookies are simply set as part of the headers.
For example, a request might contain a Cookie header containing the cookies it has currently stored.
A response might contain a Set-Cookie header which contains the cookies that the browser should set (or clear).
Let's have a look at a small example.
First, we'll need to install the cookie-parser package in addition to the express package:
pnpm install -g cookie-parser
Next, we will create an Express application with three routes.
The first route will be a /set-cookie route that will allow us to set a cookie.
The second route will be a /read-cookie route that will allow us to read the cookie.
Finally, we will add a third route /clear-cookie which will allows us to clear the cookie.
const express = require('express');
const cookieParser = require('cookie-parser');
const app = express();
const PORT = 3000;
app.use(cookieParser());
// Route to set a cookie
app.get('/set-cookie', (req, res) => {
res.cookie('myCookie', 'test', { httpOnly: true });
res.send('Cookie has been set!');
});
// Route to read the cookie
app.get('/read-cookie', (req, res) => {
const myCookie = req.cookies.myCookie;
if (myCookie) {
res.send(`myCookie: ${myCookie}`);
} else {
res.status(404).send('No cookie found');
}
});
// Route to clear the cookie
app.get('/clear-cookie', (req, res) => {
res.clearCookie('myCookie');
res.send('Cookie has been cleared');
});
app.listen(PORT, () => {
console.log(`Server listening on port ${PORT}...`);
});
Let's launch the server, open a browser and go to http://localhost:3000/set-cookie.
You should see a message Cookie has been set! and a new key-value pair appearing in your "cookies" tab.
If you now go to http://localhost:3000/read-cookie, you will see myCookie: test on the page.
Finally, if you go to http://localhost:3000/clear-cookie, you will see that the cookie has been cleared.
Redirects
The 301 (Moved Permanently) status code is used for URL redirection.
This basically informs a client that the resource has been permanently moved.
A response with a 301 status code should contain the URL where the resource has been moved to.
The 302 (Found) status code is also used for URL redirection, but it indicates to the client that the resource has been temporarily moved.
Again, a response with a 302 status code should contain the URL where the resource has been moved to.
Let's have a look at an Express example:
const express = require('express');
const cookieParser = require('cookie-parser');
const app = express();
const PORT = 3000;
// 301 Redirect (Permanent)
app.get('/permanent-redirect', (req, res) => {
res.redirect(301, '/permanent-target');
});
// 302 Redirect (Temporary)
app.get('/temporary-redirect', (req, res) => {
res.redirect(302, '/temporary-target');
});
// Target Route for 301 Redirect
app.get('/permanent-target', (req, res) => {
res.send('This is the permanent target route');
});
// Target Route for 302 Redirect
app.get('/temporary-target', (req, res) => {
res.send('This is the temporary target route');
});
app.listen(PORT, () => {
console.log(`Server listening on port ${PORT}...`);
});
If you open http://localhost:3000/permanent-redirect in your browser, you will see that the address in the browser address bar suddenly changes to http://localhost:3000/permanent-target and you see the content 'This is the permanent target route'.
If you open the network tab, you will see that two requests are sent to accomplish this.
First, your browser sends a request to http://localhost:3000/permanent-redirect and receives a response with status code 301 and the response header Location set to /permanent-target.
Your browser now sends another request to the URL that is indicated in the Location header and receives the actual content.
You will see similar behaviour with the /temporary-redirect and /temporary-target routes.
Servers and Clients
— Seconds before disaster
Basics
We've already discussed servers and clients at the beginning of this chapter.
Additionally, we wrote a server and even used a few clients (like our browser and the curl tool).
However, because this is such an important concept we will use this section to cover a complete and standalone example of a server-client setup.
Remember our definition of servers and clients:
Servers and clients are nothing more than regular programs (like the ones you saw in the first chapter). For example, a server might be a JavaScript program that waits for HTTP requests and sends back HTTP responses. A client might be a browser on your laptop or your phone—it might even be a regular script. Often, the term "server" is also used to refer to the actual machine the software is running on.
We've also discussed that we will often need to transmit data from the client to the server (and the other way around). When writing a web application, the most common way to do so is by using the HTTP protocol.
Let's now dive into an example. We will create a simple server that exposes an API to add and list tasks and a simple client that uses the API.
Building the Server
First, we will create the server.
Create a new directory named server and enter it:
mkdir server
cd server
Initialize a new project and add the express dependency to it:
pnpm init
pnpm add express
Now, create an app.js file.
Here, we will create an express app that will listen on port 3000.
We will also add a JSON middleware and a list that will store the added tasks:
const express = require('express');
const app = express();
const port = 3000;
// Middleware
app.use(express.json());
// In-memory store for tasks
const tasks = [];
// Start server
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});
Next, we need two routes—a GET route for listing all tasks and a POST route for adding a new task.
This is nothing new, we've already covered how to do this in the previous sections:
app.get('/tasks', (req, res) => {
res.json(tasks);
});
app.post('/tasks', (req, res) => {
const { name } = req.body;
if (!name) {
return res.status(400).json({ error: 'Name is required' });
}
const task = { id: tasks.length + 1, name };
tasks.push(task);
res.status(201).json(task);
});
Here is how the full server code looks like:
const express = require('express');
const app = express();
const port = 3000;
// Middleware
app.use(express.json());
// In-memory store for tasks
const tasks = [];
// Routes
app.get('/tasks', (req, res) => {
res.json(tasks);
});
app.post('/tasks', (req, res) => {
const { name } = req.body;
if (!name) {
return res.status(400).json({ error: 'Name is required' });
}
const task = { id: tasks.length + 1, name };
tasks.push(task);
res.status(201).json(task);
});
// Start server
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});
Start the server by running:
node app.js
Building the Client
Return to the top-level directory, create a new directory named client and enter it:
mkdir client
cd client
Initialize a new project and add the node-fetch dependency to it.
This will allow us to use the fetch function in Node.js:
pnpm init
pnpm add node-fetch
Finally, add {"type": "module"} to the package.json file.
Next, we will write a script client.js that will contain a CLI that allows us to list all tasks and add a task:
import fetch from 'node-fetch';
const baseUrl = 'http://localhost:3000/';
async function listTasks() {
// Make a GET request to `${baseUrl}/tasks`
}
async function addTask(name) {
// Make a POST request to `${baseUrl}/tasks`
}
function showHelp() {
console.log(`
Usage:
node client.js list List all tasks
node client.js add <name> Add a new task
`);
}
const args = process.argv.slice(2);
if (args.length === 0) {
showHelp();
} else if (args[0] === 'list') {
listTasks();
} else if (args[0] === 'add' && args[1]) {
addTask(args[1]);
} else {
showHelp();
}
To make the requests, we will use the fetch function that we've already discussed in the JavaScript chapter.
You already know how to make a GET request:
async function listTasks() {
try {
const response = await fetch(`${baseUrl}/tasks`);
const tasks = await response.json();
console.log('Tasks:', tasks);
} catch (error) {
console.error('Error fetching tasks:', error);
}
}
However, POST requests using fetch are a bit more complex.
First, we will need to explicitly set the method to POST inside the fetch function and pass the request body.
However, that's not all.
Since we want to pass a JSON in the request body, we will also need to explicitly specify that using the Content-Type header.
Therefore, this is how the fetch call should look like:
await fetch(`${baseUrl}/tasks`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name }),
});
And this is how the addTask function will look like in the end:
async function addTask(name) {
try {
const response = await fetch(`${baseUrl}/tasks`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name }),
});
const task = await response.json();
console.log('Added task:', task);
} catch (error) {
console.error('Error adding task:', error);
}
}
For your reference, here is how the full client should look like:
import fetch from 'node-fetch';
const baseUrl = 'http://localhost:3000/';
async function listTasks() {
try {
const response = await fetch(`${baseUrl}/tasks`);
const tasks = await response.json();
console.log('Tasks:', tasks);
} catch (error) {
console.error('Error fetching tasks:', error);
}
}
async function addTask(name) {
try {
const response = await fetch(`${baseUrl}/tasks`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name }),
});
const task = await response.json();
console.log('Added task:', task);
} catch (error) {
console.error('Error adding task:', error);
}
}
function showHelp() {
console.log(`
Usage:
node client.js list List all tasks
node client.js add <name> Add a new task
`);
}
const args = process.argv.slice(2);
if (args.length === 0) {
showHelp();
} else if (args[0] === 'list') {
listTasks();
} else if (args[0] === 'add' && args[1]) {
addTask(args[1]);
} else {
showHelp();
}
Let's now add a task using the client command line interface:
node client.js add example
This will output:
Added task: { id: 1, name: 'example' }
Let's also list the tasks using the CLI:
node client.js list
This will output:
Tasks: [ { id: 1, name: 'example' } ]
It works! In reality, our client would not be a command-line client, but a client running in our browser. Additionally, in practice we wouldn't store the tasks in an in-memory list (because this list would vanish once we stop the server). Instead, we would persist our tasks in a database, which is what we will cover in the next chapter.
Chapter 4: Persistence with SQL
— Ancient Chinese proverb
But our users don't really care about the code we write nor the theory we know—they care about their data. After all, the primary purpose of web applications is to ingest and show interesting data to the user.
Of course, it would be really bad if after every page refresh that data would be lost—therefore we need a way to store data persistently which is where relational databases and the SQL language come into play.
This chapter will introduce these concepts.
Setup
— Ancient Chinese proverb
Persisting Data
A database is nothing more than a collection of data that supports persistent storage and updates. If you store a value, it will be available to you regardless of whether you refresh the page, close your browser or even move to a different country altogether.
In this book, we will restrict ourselves to relational databases only. These consist of multiple tables with optional relations between the tables.
The SQL language allows us to interact with a relational database.
There are many different relational databases that support different dialects of SQL. In this book, we will stick to a relational database called PostgreSQL.
We will use the PostgreSQL term to refer both to the database and to the specific SQL dialect supported by the database.
Create a Database
First, we need to create a new database. For this book, we will use Supabase, a service that will manage our relational databases for us.
Go to Supabase. Create a new project, give it a name and select a database password (which you should write down somewhere).
Once you've created the new project, go to "Project Settings > Database" and copy and paste the URI connection string.
Replace [YOUR-PASSWORD] with the password you gave the database in the previous step.
Save the connection string somewhere, you will need it to—well—connect to the database.
Next, you should navigate to the Supabase SQL editor of your project to be able to execute queries.
Table Creation
Consider a simple task table whose purpose is to persistently store created tasks.
Let's think about the columns we might need for that table.
First, we should have an id column which would store a unique identifier for every task.
Second, we will probably need a title and description column which would store the title and description of the tasks respectively.
We will also add two more columns for educational purposes.
The status column will hold the status of the task.
Additionally, the duration column will store the estimated duration of the task in minutes.
Finally, it is good practice to always have a created_at column in every table, where we will store the time at which the row was created.
Let's create the task table.
We can use the create table SQL statement to accomplish this.
create type status as enum ('todo', 'inprogress', 'done');
create table task (
id serial primary key,
title text not null unique,
description text not null,
status status,
duration integer check (duration > 0),
created_at timestamp default current_timestamp not null
);
Note that each column has a name, a data type and optional constraints. We will talk about data types and optional constraints in more detail in the next subsection.
Inserting and Selecting Data
Now that we've created the table, we can use SQL statements to create, read, update or delete data.
For example, we can insert some data using the insert statement:
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress');
We can select that data using the select statement:
select * from task;
This will return:
| id | title | description | status | duration | created_at |
| -- | --------------------- | ------------------------------------- | ---------- | -------- | -------------------------- |
| 1 | Read the Next.js book | Read and understand the Next.js book. | inprogress | 60 | 2024-04-17 11:34:06.502155 |
We can also delete data using the delete statement.
Let's delete the data we have inserted so far to have a clean setup for the next section:
delete from task;
We will discuss these statements in more detail in later sections.
Note that when executing an SQL statement in Supabase, you don't necessarily need to provide the semicolon. However, in other SQL clients you will need the semicolon and so we will always write it for consistency.
Data Types and Constraints
— Ancient Chinese proverb
Numeric Data Types
The integer data type allows you to store integers.
You usually use this data type for counts, identifiers etc.
In our example, we use integer for the duration column of the task table.
Note that there are actually multiple integer data types in PostgreSQL.
The smallint data type allows you to store "small-range integers" and the bigint data type allows you to store "large-range integers".
The difference between smallint, integer and bigint is basically the number of bytes they contain which impacts the minimum and maximum integers that can be stored.
A smallint value has 2 bytes, i.e. it can store values from -32768 up to 32767.
An integer value has 4 bytes, i.e. it can store values from -2147483648 up to 2147483647.
A bigint value has 8 bytes, i.e. it can store values from -9223372036854775808 up to 9223372036854775807.
For most regular web applications, integer values are more than enough, and by default, PostgreSQL uses integer values for numbers.
Consider this example:
select 41234, pg_typeof(41234);
This will return:
| ?column? | pg_typeof |
| -------- | --------- |
| 41234 | integer |
The
pg_typeofoperator returns the data type of an expression. Additionally, you should ignore the column names in this section—only the column values are relevant for us here.
Note that by default integers have the type integer even if they could be smallint.
Consider this example:
select 42, pg_typeof(42);
This will return:
| ?column? | pg_typeof |
| -------- | --------- |
| 42 | integer |
You could use the :: operator to convert a value into a different data type:
select 42::smallint, pg_typeof(42::smallint);
Note that
::is a PostgreSQL-specific operator and not part of the official SQL standard.
This will return:
| int2 | pg_typeof |
| ---- | --------- |
| 42 | smallint |
Of course, if you provide a bigint value, PostgreSQL will use the bigint data type, since bigint doesn't fit into integer:
select 2147483652, pg_typeof(2147483652);
This will return:
| ?column? | pg_typeof |
| ---------- | --------- |
| 2147483652 | bigint |
If you would try to convert this value to an integer, you would get an error.
For example, trying to execute select 2147483652::integer would result in the error ERROR: 22003: integer out of range.
The serial data type allows you to represent autoincrementing integers (along with smallserial and bigserial).
This makes serial very useful for unique identifiers since you don't need to handle the incrementing logic yourself.
In the task table, the id column has the serial data type.
Note that there are many other data types and strategies for automatically handling unique identifiers. For simple applications it doesn't matter, so in this chapter we will stick to the
serialdata type.
PostgreSQL knows four data types for storing real numbers—decimal, numeric, real and double precision.
The decimal and numeric types are equivalent and allow you to store numbers with a very large number of digits.
These data types are recommended for quantities where your floating-point calculations need to be exact (e.g. when working with money).
By default, PostgreSQL will use numeric for floating-point numbers:
select 0.5::double precision, pg_typeof(0.5);
This will return:
| float8 | pg_typeof |
| ------ | --------- |
| 0.5 | numeric |
Note that because of the arbitrary precision requirement, calculations on values of the numeric data type are relatively slow.
The real and double precision data types allow you to store floating-point numbers with a precision of 6 and 15 digits, respectively.
Consider this example:
select 0.123456789123456789::real, pg_typeof(0.123456789123456789::real);
This will return:
| float4 | pg_typeof |
| -------- | --------- |
| 0.123457 | real |
Note that you only have a precision of 6 digits left after the conversion.
Something similar happens for the double precision data type:
select 0.123456789123456789::double precision, pg_typeof(0.123456789123456789::double precision);
This will return:
| float8 | pg_typeof |
| ----------------- | ---------------- |
| 0.123456789123457 | double precision |
Note that you have a precision of 15 digits now (which is more than the real data type, but still not enough to represent the number in the given example).
Character Data Types
PostgreSQL supports the char(n), varchar(n) and text data types for storing characters and strings.
The char(n) and varchar(n) data types can store strings up to n characters in length.
For example, conversions to char(n) and varchar(n) would silently truncate the string:
select 'Next.js book'::char(3), pg_typeof('Next.js book'::char(3));
This will return:
| bpchar | pg_typeof |
| ------ | --------- |
| Nex | character |
You will get a similar result if you use varchar:
select 'Next.js book'::varchar(3), pg_typeof('Next.js book'::varchar(3));
This will return:
| varchar | pg_typeof |
| ------- | ----------------- |
| Nex | character varying |
The text data type allows you to store strings of arbitrary length.
For example:
select 'Next.js book'::text, pg_typeof('Next.js book'::text);
This will return:
| text | pg_typeof |
| ------------ | --------- |
| Next.js book | text |
Note that while theoretically char(n) and varchar(n) have minor performance advantages over text, these performance advantages are usually irrelevant in practice (at least for PostgreSQL), so throughout this book we will simply always use the text data type.
In our task table we use text both for the title and the description column.
If you're interested in more details about the tradeoffs between
char(n),varchar(n)andtext, check out the official PostgreSQL documentation.
Date/Time Data Types
Dates and times are a famously dreaded topic among programmers, especially in combination with persistent data storage. We will only look at the very tip of the iceberg here. However, you should keep in mind that there are many complexities that we will skip for now.
The three most important date/time data types are date, time and timestamp.
The date data type allows you to store the date part (year, month, day) without the time information.
Consider this example:
select '2023-07-04'::date, pg_typeof('2023-07-04'::date);
This will return:
| date | pg_typeof |
| ---------- | --------- |
| 2023-07-04 | date |
The time data type is basically the "complement" to the date type and allows you to store the time part (hours, minutes, seconds) without the date information.
Consider this example:
select '07:05:16'::time, pg_typeof('07:05:16'::time);
This will return:
| time | pg_typeof |
| -------- | --------- |
| 07:05:16 | time |
Finally, the timestamp data type allows us to store a date and a time.
This is also the most commonly used date/time data type (since you usually care about the date and time).
Consider this example:
select '2023-07-04 07:05:16'::timestamp, pg_typeof('2023-07-04 07:05:16'::timestamp);
This will return:
| timestamp | pg_typeof |
| ------------------- | --------------------------- |
| 2023-07-04 07:05:16 | timestamp without time zone |
In our task table, we use the created_at column to store the time at which a task has been created.
Since we care about the date and the time, we use the timestamp data type here.
There are additional data types like timestamp with time zone (if we want to store the time zone with the timestamp), however for now we have enough data types to confidently work with dates and times in simple applications.
Enums
Enumerated data types are data types which comprise a static (and also ordered) set of values. This is a bit similar to creating a union of literal types in TypeScript (although enums and union types are not the same).
You can define an enum using the create type statement.
For example, this is how we defined the status enum:
create type status as enum ('todo', 'inprogress', 'done');
Once the enum is defined, it can be used like every other data type:
create table task (
-- code
status status,
-- code
);
Constraints
Often, we want to limit the kind of data that can be stored in a table beyond just limiting the data types. This can be accomplished with constraints.
The unique constraint is used to ensure that the data in a column is unique among all the rows in a table.
For example, we gave the title column the unique constraint to ensure that there will never be two tasks with the same title:
create table task (
-- code
title text unique,
-- code
);
Another important constraint is the not null constraint.
By default, you can insert a null value as data, where null is basically a special marker indicating that the given data doesn't exist (a bit similar to null and undefined in TypeScript).
The not null constraint quite sensibly indicates that the inserted value can't be null.
In our example, we want every task to have a title, a description and a status so we mark these columns as not null:
create table task (
-- code
title text not null,
description text not null,
-- code
);
However, we allow a task to not have a duration and don't mark that column as not null.
Basically, we apply the not null constraint if we want to ensure that a value is always present in this column.
The primary key constraint means that the column should be used to identify the rows of the table.
If a column is marked as primary key, its values must be unique and they can't be null.
Since we want the id to uniquely identify each task, we apply the primary key constraint to the id column:
create table task (
id serial primary key,
-- code
);
The check constraint is used to specify a condition that each row must satisfy for the value to be accepted into a column.
We could have used this for the status column by writing check in ('todo', 'inprogress', 'done').
However, since we knew the values in advance, we were able to use an enum instead.
Unlike enums though, check constraints allow more flexibility.
For example, we can give the duration column a constraint that its values must be greater than 0:
create table task (
-- code
duration integer check (duration > 0),
-- code
);
The default constraint allows us to specify a default value for a column.
If an insert operation doesn't provide a value for a column, PostgreSQL will automatically insert the specified value.
In our example, we want the created_at value to simply be the current time and use the default constraint together with current_timestamp to accomplish that:
create table task (
-- code
created_at timestamp default current_timestamp
);
Inserting, Updating and Deleting Data
— Ancient Chinese proverb
Inserting Data
To insert rows into a table, you use the insert statement.
Here, you need to declare the table to write to, the columns to fill and one or more rows of data to insert.
Let's insert some values into our task table:
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress'),
('Write a task app', 'Write an awesome task app.', 10, 'todo'),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress');
Note that we do not need to include the id and created_at column values.
After all, the id value has the serial data type, so PostgreSQL will automatically create new values for this column.
Additionally, the created_at column has a default constraint, so PostgreSQL will automatically create new values for this column too.
It's crucial to ensure that the inserted data respects the constraints we defined earlier.
For example, we need to respect the check constraint on the duration column.
This statement wouldn't work because it would violate this constraint:
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book', -10, 'todo');
We would get the following error:
ERROR: 23514: new row for relation "task" violates check constraint "task_duration_check"
We would get a similar error if we would try to insert a null value into a column that declares a not null constraint:
insert into task (title, description, duration, status) values
('Read the Next.js book', null, 60, 'todo');
Now we would get the following error:
ERROR: 23502: null value in column "description" of relation "task" violates not-null constraint
Updating Data
You can update rows using the update statement.
Here you need to specify the table, the columns and the rows to update.
The following statement would set all tasks with the ID 1 to done:
update task
set status = 'done'
where id = 1;
You can also update more than one column at the same time:
update task
set status = 'done', duration = 0
where id = 1;
You should be very careful when updating data.
If you make a mistake in the where clause you can update rows that you never intended to change.
Deleting Data
You can delete rows using the delete statement.
Here you need to specify which table to use and which rows to remove.
The following statement would delete all done tasks from the task table:
delete from task
where status = 'done';
If you don't specify a filter all data will be deleted:
delete from task;
Again, you should be very careful when deleting data.
If you make a mistake in the where clause you will delete rows that you never intended to remove.
Selecting Data
— Ancient Chinese proverb
Basics
We will continue working with the inserted data from the last section. As a reminder, this was the data that we've inserted:
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress'),
('Write a task app', 'Write an awesome task app.', 10, 'todo'),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress');
You can use the select statement to select rows from your table.
Here is how you can specify which columns to retrieve during selection:
select title, status from task;
This would return:
| title | status |
| --------------------- | ---------- |
| Read the Next.js book | inprogress |
| Write a task app | todo |
| Think of a funny joke | inprogress |
You can also select all columns using the * notation:
select * from task;
This would return:
| id | title | description | status | duration | created_at |
| -- | --------------------- | ---------------------------------------------- | ---------- | -------- | -------------------------- |
| 1 | Read the Next.js book | Read and understand the Next.js book. | inprogress | 60 | 2024-04-19 14:26:44.726311 |
| 2 | Write a task app | Write an awesome task app. | todo | 10 | 2024-04-19 14:26:44.726311 |
| 3 | Think of a funny joke | Come up with a funny joke to lighten the mood. | inprogress | 120 | 2024-04-19 14:26:44.726311 |
Filtering Results
You can use the where clause to filter the results that are returned by the select statement.
The where clause takes one or multiple conditions.
The conditions can contain operators like =, !=, <, <=, >, >=.
For example, here is how you can select all tasks that are in progress:
select id, title, status from task where status = 'inprogress';
This would return:
| id | title | status |
| -- | --------------------- | ---------- |
| 1 | Read the Next.js book | inprogress |
| 3 | Think of a funny joke | inprogress |
Here is how you can select all tasks that will take longer than 30 minutes:
select id, title, duration from task where duration > 30;
This would return:
| id | title | duration |
| -- | --------------------- | -------- |
| 1 | Read the Next.js book | 60 |
| 3 | Think of a funny joke | 120 |
You can use the like operator for more involved (string) comparisons.
When using the like operator, there are two characters of particular interest.
The % character matches a sequence of zero or more characters.
The _ character matches a single character.
For example, you could match all tasks that contain the sequence "book" somewhere in the description like this:
select id, title, description from task where description like '%book%';
This would return:
| id | title | description |
| -- | --------------------- | ------------------------------------- |
| 1 | Read the Next.js book | Read and understand the Next.js book. |
You could match all tasks that have the sequence 'Write', followed by three characters, followed by 'task app' like this:
select id, title, description from task where title like 'Write___task app';
This would return:
| id | title | description |
| -- | ---------------- | -------------------------- |
| 2 | Write a task app | Write an awesome task app. |
You can create a filter that checks if a value exists in a list by using the in operator:
select id, title from task where status in ('todo', 'inprogress');
This would return:
| id | title |
| -- | --------------------- |
| 1 | Read the Next.js book |
| 2 | Write a task app |
| 3 | Think of a funny joke |
You can use the and and or keywords to combine conditions.
For example, you could select all tasks that are in progress and will take longer than 90 minutes:
select id, title, status, duration
from task
where status = 'inprogress' and duration > 90;
This would return:
| id | title | status | duration |
| -- | --------------------- | ---------- | -------- |
| 3 | Think of a funny joke | inprogress | 120 |
You could also select all tasks that are in progress or will take longer than 90 minutes:
select id, title, status, duration
from task
where status = 'inprogress' or duration > 90;
This would return:
| id | title | status | duration |
| -- | --------------------- | ---------- | -------- |
| 1 | Read the Next.js book | inprogress | 60 |
| 3 | Think of a funny joke | inprogress | 120 |
Ordering and Limiting Results
You can order the results using the order by keyword.
To specify the ordering, you can use the asc (ascending) or desc (descending) keywords.
Here is how you could order the tasks by duration (ascending):
select id, title, duration from task order by duration asc;
This would return:
| id | title | duration |
| -- | --------------------- | -------- |
| 2 | Write a task app | 10 |
| 1 | Read the Next.js book | 60 |
| 3 | Think of a funny joke | 120 |
Alternatively, you could order the tasks by duration (descending):
select id, title, duration from task order by duration desc;
This would return:
| id | title | duration |
| -- | --------------------- | -------- |
| 3 | Think of a funny joke | 120 |
| 1 | Read the Next.js book | 60 |
| 2 | Write a task app | 10 |
You can limit results using the limit clause.
The limit clause allows you to limit the number of records to return.
For example, here is how you could get the two tasks with the highest duration:
select id, title, duration
from task
order by duration desc
limit 2;
This would return:
| id | title | duration |
| -- | --------------------- | -------- |
| 3 | Think of a funny joke | 120 |
| 1 | Read the Next.js book | 60 |
Of course, you can use the order by and limit clauses together with the where clause.
For example, here is how you could get the longest task that has the status inprogress:
select id, title, duration, status
from task
where status = 'inprogress'
order by duration desc
limit 1;
This would return:
| id | title | duration | status |
| -- | --------------------- | -------- | ---------- |
| 3 | Think of a funny joke | 120 | inprogress |
Modifying Tables
— Ancient Chinese proverb
The Task Table
Remember that our task table looks like this at the moment:
create type status as enum ('todo', 'inprogress', 'done');
create table task (
id serial primary key,
title text not null unique,
description text not null,
status status,
duration integer check (duration > 0),
created_at timestamp default current_timestamp not null
);
Adding and Dropping Columns
To add a column, we can use the alter table ... add column statement.
For example, here is how we can add a priority column that has the text data type:
alter table task
add column priority text;
When adding a column, we can also specify constraints on it.
For example, here is how we can add a priority column with a check constraint:
alter table task
add column priority text
check (priority in ('low', 'medium', 'high'));
You can use the alter table ... drop column statement to remove a column.
For example, here is how we can drop the priority column again:
alter table task
drop column priority;
Adding and Dropping Constraints
You can add a new constraint to a column using the alter table ... add constraint statement.
For example, here is how we can add a check constraint to the duration column:
alter table task
add constraint check_duration_max check (duration <= 600);
You can drop an existing constraint from a column using the alter table ... drop constraint statement.
Let's undo the addition of the check constraint:
alter table task
drop constraint check_duration_max;
Renaming Columns and Tables
You can rename a column using the alter table ... rename column statement.
For example, here is how you can rename the column description to details:
alter table task
rename column description to details;
You can rename an entire table using the alter table rename ... statement.
For example, here is how you can rename the task table to task_list:
alter table task
rename to task_list;
Removing Tables
You can remove an entire table using the drop table statement.
For example, here is how you can remove the task table completely:
drop table task;
It hopefully goes without saying that you should be very careful when removing an entire table, as you will also remove all the data it currently stores.
Working with Multiple Tables
— Ancient Chinese proverb
Adding Projects
Let's add projects to our application. Each project can contain multiple tasks and each task should belong to exactly one project.
It might be tempting to simply add a project ID and name to each task row. However, that would lead to a lot of redundant data. After all, you would now have to repeat the project name over and over again.
And consider what would happen once you add more project fields like a project description, status, etc. You would now have to repeat all these fields as well for every project. This will quickly become quite repetitive.
Repeating this information is not just unwieldy, it means that if we update some project fields we might make a mistake somewhere resulting in malformed data.
For example, we might forget to change a project name in some row. Suddenly we would have a project with one ID and two names.
Therefore, it is good practice to split data into multiple tables to reduce redundancy and improve data integrity. Each table should contain data about a specific entity (like "task" or "project").
The entities can then be linked together using foreign keys.
Foreign Keys
Let's create a project table:
create table project (
id serial primary key,
name varchar(255) not null
);
Let's add a column to the task table that will store the project ID:
alter table task
add column project_id integer;
Finally, we will establish a foreign key relationship. A foreign key is a column in one table that links to the primary key in another table.
Here, the project_id column in the task table should reference the id column in the project table:
alter table task
add constraint fk_project
foreign key (project_id)
references project(id);
Note that foreign keys are basically just another type of constraint.
You can't insert a task into the task table if the project_id column doesn't reference a valid project.
Consider this example:
insert into task (title, description, duration, status, project_id) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress', 1);
This statement would result in the following error:
ERROR: 23503: insert or update on table "task" violates foreign key constraint "fk_project"
DETAIL: Key (project_id)=(1) is not present in table "project".
In order to avoid this, we would need to add a new project first:
insert into project (name) values ('Learn web development');
Let's look at the newly added project:
select * from project;
This should result in something like:
| id | name |
| -- | --------------------- |
| 1 | Learn web development |
Now we could actually insert a task with a project_id of 1:
insert into task (title, description, duration, status, project_id) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress', 1);
Note that adding a foreign key constraint does not automatically add a not null constraint.
For example, you could still do this:
insert into task (title, description, duration, status, project_id) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress', null);
If you want every task to always have a project_id you would need to explicitly add a not null constraint to the project_id column.
Inner Joins
If we want to select data from multiple tables, we can use join operations.
The most common and important join operation is the inner join which combines rows from tables based on a related column between them.
Consider the following data:
insert into project (name) values ('Learn web development'), ('Gain practical experience'), ('Have fun');
insert into task (title, description, duration, status, project_id) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress', 1),
('Read the Next.js docs', 'Read and understand the Next.js docs.', 120, 'inprogress', 1),
('Write a task app', 'Write an awesome task app.', 120, 'todo', 2),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress', null);
Now let's query some data across both tables. For example, we might care about getting every task ID, title and status together with the project ID and name.
To accomplish this, we need to query both the task and project table at the same time and join them on the project ID:
select task.id as task_id, task.title as task_title, task.status as task_status, project.id as project_id, project.name as project_name
from task
inner join project on task.project_id = project.id;
This would return:
| task_id | task_title | task_status | project_id | project_name |
| ------- | --------------------- | ----------- | ---------- | ------------------------- |
| 1 | Read the Next.js book | inprogress | 1 | Learn web development |
| 2 | Read the Next.js docs | inprogress | 1 | Learn web development |
| 3 | Write a task app | todo | 2 | Gain practical experience |
Pay attention to the way the inner join statement looks like.
Here you join the task table with the project table on the statement task.project_id = project.id.
This means that every time we have a task whose project ID is equal to some ID of a project, the two records will appear in the same row in the final result.
This is why the Have fun project doesn't appear in the table since there are no corresponding tasks.
The same goes for the Think of a funny joke task.
Outer Joins
If we wanted tasks or projects that don't have corresponding projects or tasks to appear as well, we would need to use an outer join—either a left outer join or a right outer join.
For example, if we wanted to get all tasks that don't have any associated project, we could use a left join:
select task.id as task_id, task.title as task_title, task.status as task_status, project.id as project_id, project.name as project_name
from task
left join project on task.project_id = project.id;
This would return:
| task_id | task_title | task_status | project_id | project_name |
| ------- | --------------------- | ----------- | ---------- | ------------------------- |
| 1 | Read the Next.js book | inprogress | 1 | Learn web development |
| 2 | Read the Next.js docs | inprogress | 1 | Learn web development |
| 3 | Write a task app | todo | 2 | Gain practical experience |
| 4 | Think of a funny joke | inprogress | | |
Similarly, if we wanted to return all projects that don't have any associated tasks, we could use a right join:
select task.id as task_id, task.title as task_title, task.status as task_status, project.id as project_id, project.name as project_name
from task
right join project on task.project_id = project.id;
This would return:
| task_id | task_title | task_status | project_id | project_name |
| ------- | --------------------- | ----------- | ---------- | ------------------------- |
| 1 | Read the Next.js book | inprogress | 1 | Learn web development |
| 2 | Read the Next.js docs | inprogress | 1 | Learn web development |
| 3 | Write a task app | todo | 2 | Gain practical experience |
| | | | 3 | Have fun |
Of course, you can achieve the same effect by using a left join here and just swapping the order of the task and project table in the statement.
Association Tables
So far the relationships we worked with were one-to-many relationships (or many-to-one relationships depending on your point of view). However, often we need to work with many-to-many relationships instead.
Let's say that one task could belong to multiple projects at the same time. Since one project can have multiple tasks, we now have a many-to-many relationship.
The way to model this in SQL is by using a junction table (also called an associative table). A junction table is a table whose sole purpose is to create a many-to-many relationship between two other tables.
Consider the following task table:
create table task (
id serial primary key,
title text not null,
description text not null,
status status,
duration integer check (duration > 0),
created_at timestamp default current_timestamp not null
);
And consider the following project table:
create table project (
id serial primary key,
name text not null
);
The junction table would need to reference the project table on one side and the task table on the other side:
create table project_task (
project_id integer,
task_id integer,
primary key (project_id, task_id),
foreign key (project_id) references project(id),
foreign key (task_id) references task(id)
);
Let's insert some projects and some tasks:
insert into project (name) values ('Learn web development'), ('Gain practical experience'), ('Have fun');
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress'),
('Read the Next.js docs', 'Read and understand the Next.js docs.', 120, 'inprogress'),
('Write a task app', 'Write an awesome task app.', 120, 'todo'),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress');
Here is how we could then link tasks and projects:
insert into project_task (project_id, task_id) values
(1, 1), (1, 2), (1, 3), (2, 3)
Note that the task 'Write a task app' is now linked to both the 'Learn web development' and the 'Gain practical experience' project.
To query the data, we would need to perform a join over multiple tables:
select p.name as project_name, t.title as task_title, t.status as task_status
from project_task pt
join project p on pt.project_id = p.id
join task t on pt.task_id = t.id;
This would return:
| project_name | task_title | task_status |
| ------------------------- | --------------------- | ----------- |
| Learn web development | Read the Next.js book | inprogress |
| Learn web development | Read the Next.js docs | inprogress |
| Learn web development | Write a task app | todo |
| Gain practical experience | Write a task app | todo |
Chapter 5: Typesafe SQL with Drizzle
— From Drizzles' official marketing page
Drizzle is an ORM (object relational mapping) framework written in TypeScript. ORM frameworks allow you to convert data between regular (TypeScript) objects and SQL rows.
Basically, instead of writing SQL queries directly and then laboriously translating the results between TypeScript objects and SQL rows, you let the ORM do the translation for you.
Unfortunately, a lot of ORMs add a ton of (often unnecessary) abstractions. Luckily, Drizzle decided to go the opposite direction—it provides you a very simple and intuitive collection of functions that closely mirror the way SQL works. You can think of Drizzle as basically being typesafe SQL.
This makes Drizzle very simple to learn, simple to use and simple to debug problems.
Setup
... and we regret everything omg this thing sucks
— From Drizzles' official marketing page
A Simple Example
Create a new Supabase database and recreate the task table from the SQL chapter:
create type status as enum ('todo', 'inprogress', 'done');
create table task (
id serial primary key,
title text not null unique,
description text not null,
status status,
duration integer check (duration > 0),
created_at timestamp default current_timestamp not null
);
Let's also insert some values into the task table:
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress'),
('Write a task app', 'Write an awesome task app.', 10, 'todo'),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress');
Don't add the project table yet, that will come later.
Before we can write code, we need to setup Drizzle.
First, we have to initialize a new TypeScript project and also add a tsconfig.json file.
You already know the relevant commands from the TypeScript chapter:
pnpm init
pnpm add typescript tsx --save-dev
pnpm tsc --init
Next, we have to install Drizzle.
The core package is called drizzle-orm.
We will also need the pg package to be able to interact with our PostgreSQL database.
pnpm add drizzle-orm pg
We will also need the @types/pg package to get the type definitions for pg:
pnpm add @types/pg --save-dev
Create the following file demo.ts:
import {
pgTable,
pgEnum,
serial,
text,
integer,
timestamp,
varchar,
check,
} from 'drizzle-orm/pg-core';
import { sql } from 'drizzle-orm';
import { drizzle } from 'drizzle-orm/node-postgres';
// Paste the supabase URI here
const databaseURI = '...';
const statusEnum = pgEnum('status', ['todo', 'inprogress', 'done']);
// Declare the task table
const taskTable = pgTable(
'task',
{
id: serial('id').primaryKey(),
title: text('title').notNull(),
description: text('description').notNull(),
status: statusEnum().notNull(),
duration: integer('duration'),
createdAt: timestamp('created_at').defaultNow().notNull(),
},
(table) => [
{
durationCheckConstraint: check('duration_check', sql`${table.duration} > 0`),
},
],
);
// Connect Drizzle to the database
const db = drizzle(databaseURI);
// Execute a query
async function getTasks() {
return await db.select().from(taskTable);
}
getTasks().then(console.log);
Note that hardcoding passwords and secrets in code is really poor style. We will fix this at the end of this chapter.
There are two really important functions that Drizzle provides for you.
First, we have the pgTable function.
This declares a table schema and allows you to map the underneath SQL table to JavaScript (or TypeScript) objects.
Second, we have the drizzle function.
This allows you to establish the actual connection to the database and serves as the entry point for all your database interactions.
It returns a db object that represents the Drizzle client and allows you execute the actual queries (like db.select().from(taskTable)).
Execute the file:
pnpm tsx demo.ts
You will see a list of all the tasks that are currently present in the table:
[
{
"id": 1,
"title": "Read the Next.js book",
"description": "Read and understand the Next.js book.",
"status": "inprogress",
"duration": 60,
"createdAt": "2024-12-15T10:49:46.049Z"
},
{
"id": 2,
"title": "Write a task app",
"description": "Write an awesome task app.",
"status": "todo",
"duration": 10,
"createdAt": "2024-12-15T10:49:46.049Z"
},
{
"id": 3,
"title": "Think of a funny joke",
"description": "Come up with a funny joke to lighten the mood.",
"status": "inprogress",
"duration": 120,
"createdAt": "2024-12-15T10:49:46.049Z"
}
]
Drizzle as Typesafe SQL
Did you notice how similar the Drizzle function and the SQL statement are? The Drizzle function is:
db.select().from(taskTable);
The SQL function was:
select * from task;
This similarity is quite intentional and will be a major theme in this chapter. Unlike many other frameworks which try to "abstract" SQL away, Drizzle embraces SQL and only adds a bit of type safety on top of it.
If you know SQL, learning Drizzle is a very fast process.
Inserting, Updating and Deleting Data
— From Drizzles' official marketing page
Inserting Data
To insert data in SQL, you use the insert statement.
In Drizzle, you can use the appropriately named insert function on the db object:
await db.insert(table).values(values);
You need to declare the table to write to and the dictionary containing the columns and the values to insert into the respective columns.
For example, here is how you would insert a row into taskTable:
await db.insert(taskTable).values({
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
status: 'inprogress',
duration: 60,
});
You can also insert a row and get it back using the returning function.
This is useful if you want to get the data that has been automatically inserted into the database (like an ID):
const row = await db
.insert(taskTable)
.values({
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
status: 'inprogress',
duration: 60,
})
.returning();
console.log(row.id); // Will output the ID of the resulting row
You can insert multiple rows at the same by providing an array of objects:
await db.insert(taskTable).values([
{
title: 'Read the Next.js book',
description: 'Read and understand the Next.js book.',
status: 'inprogress',
duration: 5000,
},
{
title: 'Write a task app',
description: 'Write an awesome task app.',
status: 'todo',
duration: 120,
},
{
title: 'Think of a funny joke',
description: 'Come up with a funny joke to lighten the mood.',
status: 'inprogress',
duration: 5,
},
]);
Updating Data
To update data in SQL, you use the update statement.
In Drizzle, you can use the appropriately named update function on the db object:
await db.update(table).set(object).where(condition);
You need to specify the table to update, the columns with the values to update, and a condition for which rows to update.
For example, let's say that wanted to set status of the task with the ID 1 to 'done':
await db.update(taskTable).set({ status: 'done' }).where(eq(taskTable.id, 1));
Just as with SQL, you can update more than one column at the same time:
await db.update(taskTable).set({ status: 'done', duration: 0 }).where(eq(taskTable.id, 1));
Deleting Data
To delete data in SQL, you use the delete statement.
In Drizzle, you can use the appropriately named delete function on the db object:
await db.delete(table).where(condition);
You need to specify the table to delete data from as well as a condition that specifies what data to delete.
For example, here is how you could delete all the completed tasks:
await db.delete(taskTable).where(eq(taskTable.status, 'done'));
Selecting Data
— From Drizzles' official marketing page
Basics
We will work with the data that we've inserted in the last section. As a reminder, this is how it looked like:
insert into task (title, description, duration, status) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress'),
('Write a task app', 'Write an awesome task app.', 10, 'todo'),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress');
To select data in SQL, you use the select statement.
In Drizzle, you can use the appropriately named select function on the db object.
You can select all columns from a table:
await db.select().from(taskTable);
This would return the following:
[
{
"id": 1,
"title": "Read the Next.js book",
"description": "Read and understand the Next.js book.",
"status": "inprogress",
"duration": 60,
"createdAt": "2024-12-15T10:49:46.049Z"
},
{
"id": 2,
"title": "Write a task app",
"description": "Write an awesome task app.",
"status": "todo",
"duration": 10,
"createdAt": "2024-12-15T10:49:46.049Z"
},
{
"id": 3,
"title": "Think of a funny joke",
"description": "Come up with a funny joke to lighten the mood.",
"status": "inprogress",
"duration": 120,
"createdAt": "2024-12-15T10:49:46.049Z"
}
]
You can also specify certain columns to select:
await db.select({ title: taskTable.title }).from(taskTable);
This would return the following:
[
{ "title": "Read the Next.js book" },
{ "title": "Write a task app" },
{ "title": "Think of a funny joke" }
]
Filtering Results
You can use the where function to filter results which works similar to the where clause in SQL.
This function takes one or multiple conditions.
The conditions can contain functions like eq, ne, lt, lte, gt, gte.
For example, here is how you could select all tasks that are in progress:
import { eq } from 'drizzle-orm';
// ...
await db
.select({
id: taskTable.id,
title: taskTable.title,
status: taskTable.status,
})
.from(taskTable)
.where(eq(taskTable.status, 'inprogress'));
This would return the following:
[
{
"id": 1,
"title": "Read the Next.js book",
"status": "inprogress"
},
{
"id": 3,
"title": "Think of a funny joke",
"status": "inprogress"
}
]
Here is how you can select all tasks that will take longer than 30 minutes:
import { gt } from 'drizzle-orm';
// ...
await db
.select({
id: taskTable.id,
title: taskTable.title,
duration: taskTable.duration,
})
.from(taskTable)
.where(gt(taskTable.duration, 30));
This would return the following:
[
{
"id": 1,
"title": "Read the Next.js book",
"duration": 60
},
{
"id": 3,
"title": "Think of a funny joke",
"duration": 120
}
]
You can use the and and or functions to combine conditions.
For example, you could select all tasks that are in progress and will take longer than 30 minutes:
import { and, eq, gt } from 'drizzle-orm';
// ...
await db
.select({
id: taskTable.id,
title: taskTable.title,
status: taskTable.status,
duration: taskTable.duration,
})
.from(taskTable)
.where(and(eq(taskTable.status, 'inprogress'), gt(taskTable.duration, 30)));
This would return the following:
[
{
"id": 1,
"title": "Read the Next.js book",
"status": "inprogress",
"duration": 60
},
{
"id": 3,
"title": "Think of a funny joke",
"status": "inprogress",
"duration": 120
}
]
You could also select all tasks that are in progress or will take longer than 30 minutes:
import { or, eq, gt } from 'drizzle-orm';
// ...
await db
.select({
id: taskTable.id,
title: taskTable.title,
status: taskTable.status,
duration: taskTable.duration,
})
.from(taskTable)
.where(or(eq(taskTable.status, 'inprogress'), gt(taskTable.duration, 30)));
This would return the following:
[
{
"id": 1,
"title": "Read the Next.js book",
"status": "inprogress",
"duration": 60
},
{
"id": 3,
"title": "Think of a funny joke",
"status": "inprogress",
"duration": 120
}
]
Ordering and Limiting Results
You can order the results using the orderBy function.
To specify the ordering, you can use asc (ascending) or desc (descending).
For example, this is how you could retrieve all the tasks from the task table and sort them by the duration in an ascending order:
import { asc } from 'drizzle-orm';
// ...
await db
.select({
id: taskTable.id,
title: taskTable.title,
duration: taskTable.duration,
})
.from(taskTable)
.orderBy(asc(taskTable.duration));
This would return:
[
{ "id": 2, "title": "Write a task app", "duration": 10 },
{ "id": 1, "title": "Read the Next.js book", "duration": 60 },
{ "id": 3, "title": "Think of a funny joke", "duration": 120 }
]
Alternatively you could order the tasks by the duration in a descending order:
import { desc } from 'drizzle-orm';
await db
.select({
id: taskTable.id,
title: taskTable.title,
duration: taskTable.duration,
})
.from(taskTable)
.orderBy(desc(taskTable.duration));
You can also limit results using the limit function:
await db
.select({
id: taskTable.id,
title: taskTable.title,
duration: taskTable.duration,
})
.from(taskTable)
.orderBy(asc(taskTable.duration))
.limit(2);
This would return:
[
{ "id": 2, "title": "Write a task app", "duration": 10 },
{ "id": 1, "title": "Read the Next.js book", "duration": 60 }
]
Again, note how similar all these statements are to the statements from the SQL chapter.
Multiple Tables
— From Drizzles' official marketing page
Adding Projects
Let's again add projects to our application. Remember, that each project can contain multiple tasks and each task should belong to exactly one project.
Here is how we could accomplish this in SQL:
create table project (
id serial primary key,
name varchar(255) not null
);
alter table task
add column project_id integer;
alter table task
add constraint fk_project
foreign key (project_id)
references project(id);
Let's also add new tasks and projects to the task and project tables respectively:
insert into project (name) values ('Learn web development'), ('Gain practical experience'), ('Have fun');
insert into task (title, description, duration, status, project_id) values
('Read the Next.js book', 'Read and understand the Next.js book.', 60, 'inprogress', 1),
('Read the Next.js docs', 'Read and understand the Next.js docs.', 120, 'inprogress', 1),
('Write a task app', 'Write an awesome task app.', 120, 'todo', 2),
('Think of a funny joke', 'Come up with a funny joke to lighten the mood.', 120, 'inprogress', null);
Foreign Keys
Let's recreate the project and task table from the SQL chapter in Drizzle:
const statusEnum = pgEnum('status', ['todo', 'inprogress', 'done']);
const projectTable = pgTable('project', {
id: serial('id').primaryKey(),
name: text('name').notNull(),
});
const taskTable = pgTable(
'task',
{
id: serial('id').primaryKey(),
title: text('title').notNull(),
description: text('description').notNull(),
status: statusEnum().notNull(),
duration: integer('duration'),
createdAt: timestamp('created_at').defaultNow().notNull(),
projectId: integer('project_id').references(() => projectTable.id),
},
(table) => [
{
durationCheckConstraint: check('duration_check', sql`${table.duration} > 0`),
},
],
);
Inner Join
In the SQL chapter, we've already explained that to select data from multiple tables, we can use join operations.
In Drizzle, the innerJoin function can be used to perform an inner join:
await db.select().from(projectTable).innerJoin(taskTable, eq(projectTable.id, taskTable.projectId));
This would return:
[
{
"project": { "id": 1, "name": "Learn web development" },
"task": {
"id": 1,
"title": "Read the Next.js book",
"description": "Read and understand the Next.js book.",
"status": "inprogress",
"duration": 60,
"createdAt": "2024-12-15T19:31:15.196Z",
"projectId": 1
}
},
{
"project": { "id": 1, "name": "Learn web development" },
"task": {
"id": 2,
"title": "Read the Next.js docs",
"description": "Read and understand the Next.js docs.",
"status": "inprogress",
"duration": 120,
"createdAt": "2024-12-15T19:31:15.196Z",
"projectId": 1
}
},
{
"project": { "id": 2, "name": "Gain practical experience" },
"task": {
"id": 3,
"title": "Write a task app",
"description": "Write an awesome task app.",
"status": "todo",
"duration": 120,
"createdAt": "2024-12-15T19:31:15.196Z",
"projectId": 2
}
}
]
Note that the result is a list of objects, where each object in turn contains multiple objects representing the rows from the different tables.
For example, here is you could access the task and the project of the first record in the join result:
const tasksAndProjects = await db
.select()
.from(projectTable)
.innerJoin(taskTable, eq(projectTable.id, taskTable.projectId));
const firstTask = tasksAndProjects[0].task;
const firstProject = tasksAndProjects[0].project;
console.log({ firstTask, firstProject });
This would output:
{
"firstTask": {
"id": 1,
"title": "Read the Next.js book",
"description": "Read and understand the Next.js book.",
"status": "inprogress",
"duration": 60,
"createdAt": "2024-12-15T19:31:15.196Z",
"projectId": 1
},
"firstProject": { "id": 1, "name": "Learn web development" }
}
You can perform a left join and a right join in a similar manner:
await db.select().from(projectTable).leftJoin(taskTable, eq(projectTable.id, taskTable.projectId));
await db.select().from(projectTable).rightJoin(taskTable, eq(projectTable.id, taskTable.projectId));
Migrations
— From Drizzles' official marketing page
Why Migrations?
Quite often, during the course of development an application will have to change. This will sometimes include the underlying tables in the database.
The problem is when you need to change the tables, you usually already have some data in those tables which will not match the new table structures.
For example, let's say that you want to add a finished_at column to the tasks table.
What would you do with the tasks that are already present in the table?
Do you set the finished_at value for all those tasks to null?
Do you set them to some arbitrary "default" date?
Database migrations are sets of changes that allow you to transition a database schema from a current state to a new desired state without breaking your existing data. These changes can involve adding tables, adding columns, removing columns and even changing data type or constraints.
How do we perform database migrations in practice? We could theoretically just execute SQL queries that modify our tables and call it a day. However, in a real project that's a bad idea.
For example, if you execute a mistaken SQL query during a migration you will have no simple way to reverse the change, i.e. to perform a so-called "rollback". Additionally, you want to be able to allow other developers to reproduce the changes you made to a database, especially if you work with different database instances during development (which is a common practice).
Therefore, most tools (including Drizzle) split the migration process in two separate steps.
First, you need to create a file containing the desired migration. Second, you need actually execute that file to perform the migration and move your database to the new desired state.
If you want to follow along, you should drop the task and project tables along with the status enum:
drop table task;
drop table project;
drop type status;
You should also delete the demo.ts as we will now split the logic across multiple files.
Creating Your First Migration
Install the drizzle-kit package as a dev dependency:
pnpm add drizzle-kit --save-dev
Let's create a schema.ts file that will contain all our table definitions.
For now, we will only add the task table to it:
import { pgTable, serial, text, integer, timestamp, check, pgEnum } from 'drizzle-orm/pg-core';
import { sql } from 'drizzle-orm';
export const statusEnum = pgEnum('status', ['todo', 'inprogress', 'done']);
export const taskTable = pgTable(
'task',
{
id: serial('id').primaryKey(),
title: text('title').notNull(),
description: text('description').notNull(),
status: statusEnum().notNull(),
duration: integer('duration'),
createdAt: timestamp('created_at').defaultNow().notNull(),
},
(table) => [
{
durationCheckConstraint: check('duration_check', sql`${table.duration} > 0`),
},
],
);
Next, we need to create a drizzle.config.ts file.
This file should specify the various configuration options we use when connecting to the database and performing migrations:
import { defineConfig } from 'drizzle-kit';
export default defineConfig({
out: './migrations',
schema: './schema.ts',
dialect: 'postgresql',
dbCredentials: {
url: '$YOUR_DATABASE_URL_HERE',
},
});
Now, we need to generate out first migration file:
pnpm drizzle-kit generate
This will create a migrations directory containing meta directory and an SQL file with the migration.
It's quite instructive to look inside the SQL file:
CREATE TYPE "public"."status" AS ENUM('todo', 'inprogress', 'done');
CREATE TABLE "task" (
"id" serial PRIMARY KEY NOT NULL,
"title" text NOT NULL,
"description" text NOT NULL,
"status" "status" NOT NULL,
"duration" integer,
"created_at" timestamp DEFAULT now() NOT NULL
);
As you can see, a Drizzle migration file simply specifies the SQL queries that should be executed when you perform the migration.
In this example, running the migration will create a new task table with the columns we would expect.
Run Migrations
To run the migration script, we simply need to execute the following command:
pnpm drizzle-kit migrate
You will see that the table now appears in Supabase.
The Second Migration
Now, let's add the project ID and table to the schema.
Here is how the final schema.ts file should look like:
import { pgTable, serial, text, integer, timestamp, check, pgEnum } from 'drizzle-orm/pg-core';
import { sql } from 'drizzle-orm';
export const statusEnum = pgEnum('status', ['todo', 'inprogress', 'done']);
export const projectTable = pgTable('project', {
id: serial('id').primaryKey(),
name: text('name').notNull(),
});
export const taskTable = pgTable(
'task',
{
id: serial('id').primaryKey(),
title: text('title').notNull(),
description: text('description').notNull(),
status: statusEnum().notNull(),
duration: integer('duration'),
createdAt: timestamp('created_at').defaultNow().notNull(),
projectId: integer('project_id').references(() => projectTable.id),
},
(table) => [
{
durationCheckConstraint: check('duration_check', sql`${table.duration} > 0`),
},
],
);
Next, we create the second migration:
pnpm drizzle-kit generate
This will create another migration file in the migrations directory which looks as follows:
CREATE TABLE "project" (
"id" serial PRIMARY KEY NOT NULL,
"name" text NOT NULL
);
ALTER TABLE "task" ADD COLUMN "project_id" integer;
ALTER TABLE "task" ADD CONSTRAINT "task_project_id_project_id_fk" FOREIGN KEY ("project_id") REFERENCES "public"."project"("id") ON DELETE no action ON UPDATE no action;
You will see that the migration contains the "diff" between the old schema and the new desired schema. Namely:
- the migration adds the
projecttable - the migration adds a
project_idcolumn to thetasktable - the migration adds the relevant
foreign keyconstraint to thetasktable
Finally, you can execute the migration by running pnpm drizzle-kit migrate.
This will execute the migration and you should see the updated tables in your Supabase project.
Read the Database Password from Environment
There is one last thing that we need to fix.
Right now we're hardcoding our database connection URL into our script.
In real life, we want to avoid this to prevent everyone who has access to our code also having access to our database. Therefore, in practice, we read such secret information from an environment variable.
The change is relatively simple.
All we need to do is to replace the hardcoded database URL in the drizzle.config.ts file with process.env.DATABASE_URL:
import { defineConfig } from 'drizzle-kit';
export default defineConfig({
out: './migrations',
schema: './schema.ts',
dialect: 'postgresql',
dbCredentials: {
url: process.env.DATABASE_URL!,
},
});
Now you just need to export the DATABASE_URL environment variable and you can run all the commands as you normally would:
export DATABASE_URL="$YOUR_DATABASE_URL_HERE"
pnpm drizzle-kit generate
pnpm drizzle-kit migrate
Alternatively, you can read the environment variables from a .env file:
DATABASE_URL=$YOUR_DATABASE_URL_HERE
Again, you can run the commands as you usually would:
pnpm drizzle-kit generate
pnpm drizzle-kit migrate
You can now recreate the demo.ts script from the first section:
import 'dotenv/config';
import { drizzle } from 'drizzle-orm/node-postgres';
import { taskTable } from './schema';
const db = drizzle(process.env.DATABASE_URL!);
async function getTasks() {
return await db.select().from(taskTable);
}
getTasks().then(console.log);
If you run it with pnpm tsx demo.ts, you will get the same results as in the first section.
Chapter 6: A Vanilla Client
And who in their right mind wants another JavaScript framework?
— Common programmer idiom
In this chapter we will write a small example client in vanilla HTML and JavaScript (i.e. without using any frameworks). We will realize why using vanilla HTML is (usually) not a great idea and why we might want to consider using a library to help us out. Spoiler alert: That library is going to be React.
If this sounds like a pointless exercise — it's not. You need to know the basics of HTML anyway (even if you end up using React for your application). Additionally, web development shouldn't consist of stapling a bunch of magic together and praying that it works. In order to accomplish this, you will need a solid foundation to build on.
This chapter presents that solid foundation.
Hypertext Markup Language
— Seconds before disaster
A Minimal HTML File
Let's create a webpage using HTML, a markup language designed for defining documents to be displayed in a browser. We briefly touched on HTML in the first section of the JavaScript chapter, but now we will dive deeper.
Markup languages provide rules for defining the type of information contained in a document. Markup languages differ from programming languages—while markup languages enable the creation of displayable documents, programming languages offer much more powerful capabilities. Therefore, HTML is a markup language and JavaScript is a programming language.
First, create a project directory. From here on, all work will be done within that directory.
Now, create a file named index.html in the project directory and write some minimal useful HTML to display two hardcoded tasks:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
</head>
<body>
<div id="app">
<div>
<h1>My tasks</h1>
<div id="taskList">
<p>Read the Next.js book</p>
<p>Write a website</p>
</div>
</div>
</div>
</body>
</html>
When you open the HTML file in your browser you should see a heading and two tasks.
That's it, you've created a simple HTML document! Now, you can close this book and go procrastinate.
What's that? You're not budging? Hm, that's weird. Oh, we see, you've unfortunately been forced to read this book (blink once for help).
Well, since we have to be here anyway, might as well continue and dissect the masterpiece you've just created!
HTML Elements
HTML documents are comprised of HTML elements used to specify the type of content that should be rendered.
For example, the p element represents a paragraph:
<p>Read the Next.js book</p>
An HTML element usually has some content between an opening tag and a closing tag.
The opening tag is the name of the element wrapped in angle brackets (like <p>).
The closing tag is the name of the element wrapped in angle brackets with a forward slash before the element name (like </p>).
There are various HTML elements with different purposes, such as p for paragraphs and div for generic containers.
We will discuss a few important HTML elements in the following sections.
HTML's power lies in the fact that most elements can be nested. For example, you could nest paragraphs within a generic container:
<div>
<p>Read the Next.js book</p>
<p>Create a website</p>
<p>???</p>
<p>Profit!</p>
</div>
The nesting can go as deep as you want.
For example, we could use the <em> element to emphasize some of the words in the previous example:
<div>
<p>Read the <em>Next.js</em> book</p>
<p>Create a <em>website</em></p>
<p>???</p>
<p>Profit!</p>
</div>
Note that the tags of the element being nested must be inside the tags of the element it's being nested in.
For example, the tags of the element <em>Next.js</em> are inside the element <p>Read the <em>Next.js</em> book</p>.
Some elements are so-called void elements, meaning that they can't have any nested child elements. Void elements only have a start tag. End tags must not be specified for such void elements.
For example, the line break <br> is a void element because it wouldn't make sense to put additional elements inside a line break.
It's common to write void elements by appending a trailing slash character to the element <br />.
Note that technically self-closing tags do not exist in HTML. If a trailing slash is present, HTML parsers simply ignore that character. However, adding a trailing slash makes void elements more readable and is therefore common practice.
HTML Attributes
Elements can also have HTML attributes.
Attributes contain further information about the element.
Two particularly important attributes are id and class.
The id attribute is used to specify a unique identity for an HTML element.
You can use that attribute to—well—uniquely identify an element.
This allows us to reference that element from places like JavaScript code or CSS stylesheets.
Here is how we can create an element with an id attribute:
<p id="read-book">Read the Next.js book</p>
Generally speaking, you can specify attributes by writing the attribute name, followed by an equals sign =, followed by the attribute value wrapped inside double quotes.
The class attribute is used to specify a class for an HTML element.
Unlike unique identifiers, multiple HTML elements can share the same class, which is useful for applying consistent logic to multiple elements.
For example, you could give all HTML elements of class blue-text a blue text color.
Here is how we can create an element with a class attribute:
<p class="blue-text">Read the Next.js book</p>
A common naming convention for IDs and classes is dash-case where each word is in lower case, and separated by dashes.
There are many more attributes and different HTML elements often have different attributes you can apply to them. We will cover some of the most important elements together with their attributes in the next sections.
Structure of an HTML Document
Let's have a look at index.html again and examine its structure in more detail:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
</head>
<body>
<div id="app">
<div>
<h1>My tasks</h1>
<div id="taskList">
<p>Read the Next.js book</p>
<p>Write a website</p>
</div>
</div>
</div>
</body>
</html>
The document begins with <!doctype html> which is a document type declaration.
It is there mainly for historical reasons—in the olden days of HTML the doctype specified which rules the HTML page followed.
However, the olden days are no longer with us and we just use the shortest valid doctype which happens to be <!doctype html>.
The doctype is followed by an <html> element which contains all the content of the document.
This element is usually called the root element.
The <html> element contains a <head> and <body> elements (there is that nesting again).
The <head> element includes important information about the page that doesn't appear on the page itself.
Here is where we could specify how our page would appear in search results, which character encoding our website uses and more.
In this example, the <head> element includes a <meta> element with a charset attribute and a <title> element.
This particular <meta> element describes the character encoding for the HTML document and the <title> element sets the title of the page.
This title is displayed in the browser tab and is also used when you save the page in your bookmarks.
Finally, the <body> element contains all the content that will actually be rendered on the page.
In our example, the heading and the task list are within the <body> element.
Marking Up Text
— Seconds before disaster
The Paragraph Element
The most basic element for marking up text is the paragraph element <p>:
<p>This is the first paragraph of many, many paragraphs.</p>
<p>This is the second paragraph of many, many paragraphs.</p>
<p>This is the third paragraph of many, many paragraphs.</p>
Visually speaking, paragraphs are represented as text blocks separated from surrounding content by blank lines. Paragraphs are commonly used to group related text.
Breaking Up Text
You can break up text with the line break element <br>:
There is a line break here. <br />
This is some text after the line break.
Additionally, you can use the <hr> element for a thematic break of some text.
It will usually be visually presented as a horizontal line.
Here is some text. <hr /> Here is some text about something totally different.
The <hr> element is often used to introduce thematic breaks between paragraphs.
Heading Elements
There are six heading elements, <h1> to <h6>.
The different heading elements represent different "heading levels", e.g. <h1> is the main heading, <h2> a subheading and so on:
<h1>Main heading</h1>
<h2>Subheading 1</h2>
<h3>Subsubheading 1.1</h3>
<p>Some content related to subheading 1.1</p>
<h3>Subsubheading 1.2</h3>
<p>Some content related to subheading 1.2</p>
<h2>Subheading 2</h2>
<h3>Subsubheading 2.1</h3>
<p>Some content related to subheading 2.1</p>
<h3>Subsubheading 2.2</h3>
<p>Some content related to subheading 2.2</p>
You will rarely need <h4> to <h6>—very few documents require such deeply nested heading levels.
Additionally, you should only use a single <h1> heading in a page since this is the top-level heading.
Emphasis and Importance
If we want to emphasize a part of a text (like an important word) we can use the <em> and <strong> elements.
The <em> element marks that a text should be emphasized:
The weather today is <em>very</em> hot.
The <strong> element marks that a text has strong importance:
The weather today is not just hot, it's <strong>scorching</strong>.
As you probably guessed, deciding which of these two elements is appropriate is largely on you.
If you want to emphasize some part of a text, but it doesn't have strong urgency, you should use <em>.
If a text is very important, you should use <strong> instead.
There are also the
<i>and<b>elements. However, we will rarely use them, since<em>and<strong>have a semantic meaning (see below for what this means).
Other Text Elements
We've only scratched the surface of the kind of text markup you can perform with HTML.
There are many, many other elements you can use.
For example, you can mark up subscripts and superscripts with <sub> and <sup> respectively:
<p>The chemical formula for water is H<sub>2</sub>O.</p>
<p>The equation for energy is E = mc<sup>2</sup>.</p>
You can add quotes—both blockquotes (with <blockquote>) and inline quotes (with <q>):
<p>As the famous physicist once said:</p>
<blockquote cite="https://some-random-quotes.com/">
"Stop believing quotes you found on the internet"
</blockquote>
<p>
As Einstein once said,
<q>people who build their lifes around random internet quotes are stupid.</q>
</p>
Trying to learn every single HTML element for marking up text would be a pointless endeavour (you can look them up with a simple Google search anyway). Just be aware that when it comes to marking up text there might be an HTML element for your use case.
Semantic HTML
In a few chapters, we will introduce you to CSS, which will allow you to style your HTML elements however you see fit.
At this point most people forget that there are any elements besides the generic <div> container since they can now just style the <div> to look however they want.
This is a really bad idea.
The problem is that looking at a page is not the only way to browse the web.
First of all, there are a lot of visually impaired people in the world who use screen readers to navigate the internet. Screen readers tend to focus on the HTML elements and not the styles (which makes sense, since reading out styles is not really something you want to do).
If you write a heading as a styled <div> instead of an <h1> you are not only doing more (unnecessary) work, you also give visually impaired people a worse experience.
Screen readers often interpret headings in a special way.
For example, you can ask most screen readers to read all headings on a page out loud and then jump to some heading you care about.
This is of course not possible with <div>s.
Second, your page will also be consumed by programs responsible for indexing and ranking. If your website contains generic containers only, it will usually be downgraded resulting in the much dreaded bad Search Engine Optimization.
Therefore, you should absolutely not forget about the semantically correct HTML elements we've presented in this section.
Also, if you don't use semantically correct HTML, your fellow developers will let you know about this in the smuggest way possible.
Hyperlinks and Images
— Seconds before disaster
Hyperlinks
One of the most important HTML elements is the hyperlink. You're probably already familiar with hyperlinks—they allow you to link web pages, documents or other resources from your page. If the link is clicked, the linked page is typically opened in your browser for you to see.
Here is how you can create a hyperlink:
<a href="https://example.com">Example</a>
This creates a link with the text "Example" that links the resource mentioned in the href attribute (which in this case is "https://example.com").
By default, the text becomes blue and underlined.
If you click the text, the web browser opens the page located at https://example.com.
Note that HTML elements can also be made into links by simply nesting them inside an <a> element.
For example:
<a href="https://example.com">
<h1>Example</h1>
</a>
Images
To show an image, you can use the <img> element:
<img src="cat.jpg" alt="A cute cat" />
Note that the
imgelement is a void element.
The src attribute contains the path to the image you want to show.
The alt attribute holds a textual replacement for the image and is necessary in case the image can't be shown.
Try misspelling the filename on purpose and you will see the textual replacement.
In practice the textual replacement is useful if, for example:
- there is a network error and the image can't be fetched
- the user is using a screen reader (in this case the textual replacement may be read out loud to him)
- the browser doesn't support the image type
- the user has turned off images to reduce data transfer
Additionally, search engines will usually look at the alt attributes of images when processing your web page.
You should therefore always include the alt attribute for every image you serve.
The
altattribute is a typical example of semantically correct HTML. Sure, your page will usually look right even if you don't use it, but the user experience for some users (including search engines) will be much worse.
Image Links
You can use the fact that HTML elements can be made into links to create image links:
<a href="https://example.com">
<img src="example.png" alt="An example image" />
</a>
This will show a clickable image—if the image is clicked, the browser will open https://example.com.
The Document Object Model
— Seconds before disaster
HTML and DOM
When you open an HTML document in a browser, it's represented by the Document Object Model (DOM for short). Essentially, the DOM is a model for documents which represent editable logical trees.
This sounds way scarier than it really is, so let's consider an example:
<div id="task-list">
<p> Read the Next.js book </p>
<p> Write a website </p>
</div>
Here, we have a <div> element (the generic container) and two <p> (paragraph) elements inside it.
The <div> element is the parent of the <p> elements and the <p> elements are the children of the <div> element.
The elements form a (very small) tree:
Let's take a look at a bigger document:
<div id="app">
<h1>My tasks</h1>
<div id="task-list">
<p> Read the Next.js book </p>
<p> Write a website </p>
</div>
</div>
You can visualize this document in the following way:
It's crucial to distinguish between HTML and the DOM, as they are absolutely not the same thing. The DOM is a language-agnostic model that represents the structure of a document. On the other hand, HTML is a specific language that encodes a particular kind of DOM into text usable by web browsers.
To simplify, you write an HTML document, the browser parses that document into a DOM tree and then the browser displays a DOM tree.
Manipulating the DOM using JavaScript
Whenever you write applications which have a lot of logic in the client, you will need to manipulate the DOM (i.e. add, remove, change or retrieve elements).
This can be done by using JavaScript functions that exist on the document object, which is a global variable that refers to the currently rendered DOM tree.
For the rest of this section, we will consider the following document:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
</head>
<body>
<div id="app">
<h1>My tasks</h1>
<div id="task-list">
<p id="first-paragraph" class="task"> Read the Next.js book </p>
<p id="second-paragraph" class="task"> Write a website </p>
</div>
</div>
</body>
</html>
If you want to follow along, you can open this document in a browser, open the JavaScript console and then write the code in the console.
First, let's talk about how to retrieve elements.
The document.getElementById(id) function allows you to select an element by its unique ID:
const paragraph = document.getElementById('first-paragraph');
console.log(paragraph); // <p id="first-paragraph" class="task">
Note that paragraph is just a regular JavaScript object.
For example, you could access various properties like the element ID and class or the HTML markup contained within the element:
console.log(paragraph.id); // first-paragraph
console.log(paragraph.className); // task
console.log(paragraph.innerHTML); // Read the Next.js book
We can also get all the elements that have a certain class using document.getElementsByClassName(className):
const tasks = document.getElementsByClassName('task');
console.log(tasks); // HTMLCollection { 0: p#first-paragraph.task, 1: p#second-paragraph.task, length: 2, … }
Note that tasks is an HTMLCollection which is an array-like object.
This means that it behaves similar to an array (for example you can index it), but doesn't have most of the array methods we learned in the first chapter:
console.log(tasks.length); // 2
console.log(tasks[0]); // <p id="first-paragraph" class="task">
// This will throw a TypeError: tasks.map is not a function
const ids = tasks.map((task) => task.id);
You can also retrieve all elements with a certain tag by using document.getElementsByTagName(tagName).
Consider this example:
const paragraphs = document.getElementsByTagName('p');
console.log(paragraphs); // HTMLCollection { 0: p#first-paragraph.task, 1: p#second-paragraph.task, length: 2, … }
Note how this is again an HTMLCollection.
The two most important and modern JavaScript methods for element retrieval are document.querySelector(selector) and document.querySelectorAll(selector) which return the first and all elements that match a certain CSS selector respectively.
Here is how we could use these methods to accomplish our tasks from before:
// The hash (#) indicates an ID selector
const paragraph = document.querySelector('#first-paragraph');
// The period (.) indicates a class selector
const tasks = document.querySelectorAll('.task');
const paragraphs = document.querySelectorAll('p');
Note that this time tasks will be a NodeList (instead of an HTMLCollection).
However, a NodeList is still an array-like object that you can index with [].
JavaScript also allows us to create elements and append them to other elements.
You can create elements using document.createElement(tagName).
This is how you could create a paragraph with an ID, a class and some text:
const element = document.createElement('p');
element.id = 'thirdParagraph';
element.classList.add('task');
element.innerHTML = 'New task';
You can append an element as a last child of a parent element using parentElement.appendChild(childElement).
For example, to append the newly created element to another element taskList you would write this:
// Retrieve the taskList element
const taskList = document.querySelector('#task-list');
// Append element to taskList
taskList.appendChild(element);
Let's put all of this together and add a new task using these methods:
const paragraph = document.createElement('p');
paragraph.id = 'third-paragraph';
paragraph.classList.add('task');
paragraph.innerHTML = 'New task';
const taskList = document.querySelector('#task-list');
taskList.appendChild(paragraph);
Events
— Seconds before disaster
The Basics
Events can be used to react to "interesting changes" like user input. For example, you might want to do something if the user clicks a button, presses a key or resizes the window.
Consider the following simple HTML example:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Example</title>
</head>
<body>
<a id="example-link" href="http://example.com/">Go to example page</a>
<button id="example-button">Click me!</button>
<div id="parent">
<button id="child">Click the child!</button>
</div>
<script>
/* Our JavaScript code will go here. Note that the script tag must be at the end of the body. */
</script>
</body>
</html>
We can use the addEventListener to register an event listener on the button to set up a function that should be called if the button is clicked.
The addEventListener function takes two arguments.
The first argument is the event to listen to (which in this case will be 'click').
The second argument is a function that takes the specific event and handles it.
document.querySelector('#example-button').addEventListener('click', () => {
console.log('Button was clicked!');
});
If you click the button, the text Button was clicked! will appear in the console.
The
addEventListeneris a typical example of a higher-order function since it takes a function as one of its arguments.
You can remove an event listener using the removeEventListener function:
const clickFunction = () => {
console.log('Button was clicked!');
};
document.querySelector('#example-button').addEventListener('click', clickFunction);
document.querySelector('#example-button').removeEventListener('click', clickFunction);
The registered function can take the event object as an argument which is useful if you need to gather more information about the event:
document.querySelector('#example-button').addEventListener('click', (e) => {
console.log(e);
});
Preventing Default Actions
Many events have default actions. For example, clicking a link will navigate you to a new page.
You can prevent the default action using event.preventDefault():
document.querySelector('#example-link').addEventListener('click', (e) => {
e.preventDefault();
console.log("You can't click this link, harharhar.");
});
While you should definitely not break links in this manner, event.preventDefault() is useful with other elements as we will see in the next sections.
Event Targets
An event object has two important properties that are a common source of confusion for beginners—target and currentTarget.
The target is the element that triggered the event.
However, the currentTarget is a reference to the element to
which the event handler was attached in the first place.
Put simply, currentTarget is the element that listens to the event.
The target and currentTarget can be the same element if the element that triggers the event is also the element that listens to the event.
However, that doesn't have to be the case.
Consider our setup with a <div> element containing a <button>:
<div id="parent">
<button id="child">Click the child!</button>
</div>
Let's put a click event listener on the parent <div>:
document.querySelector('#parent').addEventListener('click', (e) => {
console.log('event.target:', e.target);
console.log('event.currentTarget:', e.currentTarget);
});
Here, the target would be the child <button> because that was the element that actually triggered the event.
After all, you click the child <button> and not the parent <div>.
However, the currentTarget would be the parent <div> because that was the element to which we attached the event handler.
You can verify this yourself.
If you click the child button, you will see that event.target refers to the child <button> while event.currentTarget refers to the parent <div>.
It's also important to note that the value of event.currentTarget is only available while the event is being handled.
This means that if you console.log() the event, store in a variable and then look at event.currentTarget in the console, you will get null.
This can be extremely confusing if you're trying to debug events.
A Simple Example
Here is how we could create a button that dynamically adds a new task every time we click it:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Example</title>
</head>
<body>
<div id="task-list">
<button id="addTask">Add a task</button>
</div>
<script>
function addTask() {
const paragraph = document.createElement('p');
paragraph.classList.add('task');
paragraph.innerHTML = 'New task';
const taskList = document.querySelector('#task-list');
taskList.appendChild(paragraph);
}
document.querySelector('#task-list').addEventListener('click', () => {
addTask();
});
</script>
</body>
</html>
Note that all the new tasks will be lost if you refresh the page or close your browser. That's because they are currently only stored in the client (and not on the server).
Web Forms
— Seconds before disaster
Why Web Forms?
Web forms (or just forms for short) provide a tool for accepting user input. They're one of the key components that make your pages interactive. A web form contains one or more form controls which are usually paired with text labels that describe the purpose of the control. For example, a textual form control for providing a message might be paired with a label explaining that the textual form control represents a message.
Consider a very common example—the contact form.
Such a contact form should probably have:
- a text input for the name of the user submitting the form
- a text input for the email of the user submitting the form
- a multiline text input for the message to submit
- a submit button
Creating a Form
Forms can be created using the <form> element:
<form> ... </form>
Note that usually
<form>elements contain anactionattribute which defines the URL where the form's data should be submitted. However, in this book we will handle form submissions manually, so we won't go into detail on theactionattribute.
Let's now add the form control for the username along with a label (note that the elements should go in between the <form></form> tags):
<!-- The label -->
<label for="name">Name:</label>
<!-- The form control-->
<input type="text" id="name" name="name" />
There are two HTML elements at play here—<input> and <label>.
The form control is represented by the <input> element.
It has a lot of possible attributes, but the two most important ones (apart from the id attribute) are the type and name attribute.
The type attribute represents the type of the form control.
For example, a plaintext input field would have the type text while a checkbox would have the type checkbox (surprise).
The name attribute specifies a name for the form control.
This attribute is important when submitting the form (usually by clicking the submit button) as it will identify the submitted value.
The label is represented by the <label> element.
The for attribute of the label must be an ID of a form control.
In this case the ID of the <input> element is name and therefore the for attribute of the <label> element has name as its value.
Now let's add the form control for the email.
We could theoretically use the text type again, however HTML provides us a custom email type called email.
This field looks like a regular text input, but has a few additional nice properties—for example the email is validated on submission:
<!-- The label -->
<label for="email">Email:</label>
<!-- The form control-->
<input type="email" id="email" name="email" />
Finally, for the multiline text, we will use the <textarea> element:
<!-- The label -->
<label for="message">Message:</label>
<!-- The form control-->
<textarea id="message" name="message"></textarea>
The last element we need is the submit button:
<button type="submit">Send</button>
Here is how the final form will look like:
<form id="contact">
<label for="name">Name:</label>
<input type="text" id="name" name="name" />
<label for="email">Email:</label>
<input type="email" id="email" name="email" />
<label for="message">Message:</label>
<textarea id="message" name="message"></textarea>
<button type="submit">Send</button>
</form>
Structuring Forms with <fieldset> and <legend>
We can use the <fieldset> and <legend> attributes to further improve our form:
<form id="contact">
<fieldset>
<legend>Message Form</legend>
<label for="name">Name:</label>
<input type="text" id="name" name="name" />
<label for="email">Email:</label>
<input type="email" id="email" name="email" />
<label for="message">Message:</label>
<textarea id="message" name="message"></textarea>
<button type="submit">Send</button>
</fieldset>
</form>
Handling a Form Submission
If you click the button right now, the page will refresh, the URL will change and your inputs will be cleared. This is the default behaviour of a form submission, however we often want to intercept and modify this.
To achieve this, let's add an event listener to the form that will listen for submit events:
const contactForm = document.getElementById('contact');
contactForm.addEventListener('submit', function (event) {
// Prevent default form submission behaviour
event.preventDefault();
console.log({ currentTarget: event.currentTarget });
});
Note how the event.currentTarget object contains our inputs (among other properties).
A Simple Client
— Seconds before disaster
The Requirements
One day you sit around and dream about going outside as suddenly the dreaded Project Manager approaches you and asks you to build a small task application. The application should consist of a list showing the current tasks. Additionally, a web form should allow the user to create a new task (which should then be displayed in the list of current tasks).
The Initial HTML
You get to work and quickly come up with the initial document:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Task List App</title>
</head>
<body>
<h1>Task List</h1>
<!-- Task List -->
<ul id="task-list"> </ul>
<!-- Form to Add Tasks -->
<h2>Add a Task</h2>
<form id="task-form">
<label for="task-input">Task:</label>
<input type="text" id="task-input" placeholder="Enter your task" />
<button type="submit">Add Task</button>
</form>
<!-- JavaScript will go here -->
<script></script>
</body>
</html>
You now have a heading, a list and a form. However, if you click the submit button, not much happens. After all, we haven't added any submit logic to the form yet.
Grabbing the Items
Let's first grab the relevant items.
This can be done using the querySelector method.
In this case we want to select by ID, so we use the # selector:
const taskList = document.querySelector('#task-list');
const taskForm = document.querySelector('#task-form');
Remember, the code goes between the <script></script> tags.
Adding an Event Listener
Next, we need to add an event listener to the task form that will simply log the task input for now. Note that we want to
taskForm.addEventListener('submit', function (event) {
// Prevent default form submission
event.preventDefault();
console.log({ inputValue: event.currentTarget.elements['task-input'].value });
});
Let's now store the task input in a variable and use trim to remove whitespace from both ends:
taskForm.addEventListener('submit', function (event) {
// Prevent default form submission
event.preventDefault();
const task = event.currentTarget.elements['task-input'].value.trim();
});
Finally, we will use the createElement method to create a new li element and the appendChild method to add the newly created element to our task list:
taskForm.addEventListener('submit', function (event) {
// Prevent default form submission
event.preventDefault();
// Get the task input
const task = event.currentTarget['task-input'].value.trim();
// Create a new task element and append it to the task list
const li = document.createElement('li');
li.textContent = task;
taskList.appendChild(li);
// Clear the input field
event.currentTarget['task-input'].value = '';
});
If you click the button now, you will see that a new task will be added to the task list.
Adding a Delete Button
As you complete the project, the Project Manager once again walks up to you and remembers that it might be a good idea to allow the user to delete tasks.
Therefore, whenever you create a new element, that element should have a delete button.
To accomplish this, we first need to add a delete button to every task we create:
const li = document.createElement('li');
li.textContent = task;
// New code starts here
const deleteButton = document.createElement('button');
deleteButton.textContent = 'Delete';
Next, we need to attach an event listener to the delete button:
deleteButton.addEventListener('click', function () {
taskList.removeChild(li);
});
Finally, we need to add the delete button to the task item:
li.appendChild(deleteButton);
It's easy to see that our code is now all over the place and not really reusable. Additionally, it's getting much harder to understand by the minute and we've only started writing our application. This doesn't seem like it will scale to a larger project.
To simplify our lives, we will use a library called React. The idea behind React is to create declarative UIs with nicely separated components.
Basically, we only declare how the application should look like and React takes care of the rest, including determining the necessary DOM manipulations. As you will see soon, this will save us a lot of time.
Chapter 7: Adding Style with CSS
So far, our pages are functional, but they're not pretty to look at.
CSS (short for Cascading Style Sheets) is a special language that is used for specifying the styling of an HTML document.
Using CSS
Internal Style Sheets
CSS is the language that describes the styling of an HTML document.
The simplest way to add CSS to an HTML document is by using the <style> tag inside the <head> section of the HTML document.
This is called an internal style sheet.
Consider the HTML document from the HTML chapter:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
</head>
<body>
<div id="app">
<div>
<h1>My tasks</h1>
<div id="taskList">
<p>Read the Next.js book</p>
<p>Write a website</p>
</div>
</div>
</div>
</body>
</html>
Let's make the h1 element red and the p elements blue.
To do this, we can add the following CSS to the <head> section of the HTML document:
<style>
h1 {
color: red;
}
p {
color: blue;
}
</style>
Here is how the full HTML document looks like:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
<style>
h1 {
color: red;
}
p {
color: blue;
}
</style>
</head>
<body>
<div id="app">
<div>
<h1>My tasks</h1>
<div id="taskList">
<p>Read the Next.js book</p>
<p>Write a website</p>
</div>
</div>
</div>
</body>
</html>
External Style Sheets
Internal style sheets are fine for small projects, but as the project grows, it can become cumbersome to have all the CSS in the <head> section of the HTML document.
To solve this problem, we can use external style sheets.
An external style sheet is a separate CSS file that can be linked to an HTML document.
Create a CSS file styles.css in your project directory:
h1 {
color: red;
}
p {
color: blue;
}
Now, you can link the CSS file to the HTML document by adding the following line to the <head> section of the HTML document:
<link rel="stylesheet" href="styles.css" />
The <link> element is used to link an external resource to the HTML document.
We use the rel attribute to specify the relationship between the HTML document and the linked resource.
In this case, we use the stylesheet value to indicate that the linked resource is a CSS stylesheet.
Finally, we use the href attribute to specify the path to the CSS file.
Here is how the full HTML document looks like:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
<link rel="stylesheet" href="styles.css" />
</head>
<body>
<div id="app">
<div>
<h1>My tasks</h1>
<div id="taskList">
<p>Read the Next.js book</p>
<p>Write a website</p>
</div>
</div>
</div>
</body>
</html>
Inline Styles
You can also use inline styles to style an element.
Inline styles are defined inside the style attribute of the element.
For example, the following CSS will style the h1 element red:
<h1 style="color: red">My tasks</h1>
Here is how the full HTML document looks like:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
</head>
<body>
<div id="app">
<div>
<h1 style="color: red">My tasks</h1>
<div id="taskList">
<p>Read the Next.js book</p>
<p>Write a website</p>
</div>
</div>
</div>
</body>
</html>
Throughout this chapter, we will use either inline styles or internal style sheets for simplicity. However, in the real world, you will most likely use external style sheets.
CSS Selectors
The Document
We will use the following HTML document for our examples:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Easy Opus</title>
<style>
/* styles go here */
</style>
</head>
<body>
<div id="app">
<div>
<h1 id="title">My tasks</h1>
<p>Here is a list of my tasks:</p>
<div id="taskList">
<p id="task1" class="task">Read the Next.js book</p>
<p id="task2" class="task">Write a website</p>
</div>
</div>
</div>
</body>
</html>
Type Selectors
CSS selectors are used to target the elements we want to style.
You can use type selectors (also called tag name selectors or element selectors) to target all elements of a certain type.
For example, the following CSS will style all <p> elements:
p {
color: red;
}
ID Selectors
You can use ID selectors to target a specific element by its id attribute.
ID selectors begin with a # symbol.
For example, the following CSS will style the element with the id attribute set to task1:
#task1 {
color: blue;
}
If you would like to style the first task blue and the second task green, you can use the following CSS:
#task1 {
color: blue;
}
#task2 {
color: green;
}
Class Selectors
You can use class selectors to target all elements with a specific class.
Class selectors begin with a . symbol.
For example, the following CSS will style all elements with the task class:
.task {
color: blue;
}
Selector Lists
You can target multiple selectors by separating them with a comma.
For example, the following CSS will style all <p> and <h1> elements:
p,
h1 {
color: red;
}
Selector lists don't need to consist of selectors of the same type. For example, you can write a selector list that targets eleemnt by tag and ID:
p,
#title {
color: red;
}
Basic Styles
Typography
You can change the typeface of your text using the font-family CSS property.
For example, the following CSS will change the typeface of the text to sans-serif:
font-family: sans-serif;
Here is how you could use this CSS in your HTML document:
<p style="font-family: sans-serif;">This uses a sans-serif font</p>
<p style="font-family: serif;">This uses a serif font</p>
<p style="font-family: monospace;">This uses a monospace font</p>
You can change the size of your text using the font-size CSS property.
You can set sizes either in absolute units (pixels) or in relative units (em, rem).
Pixels are absolute units, meaning that the styling of the element will be independent of other elements on the page. For example, the following CSS will change the size of the text to 16px:
font-size: 16px;
Here is how you could use this CSS in your HTML document:
<p style="font-size: 16px;">This uses a 16px font</p>
Unlike the absolute pixel unit, relative units are relative to something.
The em unit is relative to the font size of the element and the rem unit is relative to the font size of the root element.
For example, the following CSS will change the size of the text to 1em:
font-size: 1em;
Here is how you could use this CSS in your HTML document:
<p style="font-size: 1em;">This uses a 1em font</p>
Similarly, the following CSS will change the size of the text to 1rem:
font-size: 1rem;
Here is how you could use this CSS in your HTML document:
<p style="font-size: 1rem;">This uses a 1rem font</p>
You can change the weight of your text using the font-weight CSS property.
For example, the following CSS will change the weight of the text to bold:
font-weight: bold;
Here is how you could use this CSS in your HTML document:
<p style="font-weight: bold;">This uses a bold font</p>
You can change the height of the line of text using the line-height CSS property.
For example, the following CSS will change the height of the line of text to 1.5:
line-height: 1.5;
Here is how you could use this CSS in your HTML document:
<p style="line-height: 1.5;">This uses a 1.5 line height</p>
You can change the alignment of your text using the text-align CSS property.
For example, the following CSS will change the alignment of the text to center:
text-align: center;
Here is how you could use this CSS in your HTML document:
<p style="text-align: left;">This text is left-aligned</p>
<p style="text-align: center;">This text is centered</p>
<p style="text-align: right;">This text is right-aligned</p>
<p style="text-align: justify;">This text is justified</p>
You can change the color of your text using the color CSS property.
For example, the following CSS will change the color of the text to red:
color: red;
Here is how you could use this CSS in your HTML document:
<p style="color: red;">This text is red</p>
<p style="color: blue;">This text is blue</p>
<p style="color: green;">This text is green</p>
You can change the decoration of your text using the text-decoration CSS property.
For example, the following CSS will change the decoration of the text to underline:
text-decoration: underline;
Here is how you could use this CSS in your HTML document:
<p style="text-decoration: underline;">This text is underlined</p>
<p style="text-decoration: none;">This text is not underlined</p>
Background
You can change the background of an element using the background CSS property.
For example, the following CSS will change the background of the element to red:
background: red;
Here is how you could use this CSS in your HTML document:
<div style="background: red; color: white;">This is a red background</div>
The Box Model
The Basics of the Box Model
Every element in HTML is a rectangular "box" made up of four nested areas:
 Credit: MDN
Credit: MDN
The content area (bounded by the content edge) contains the actual content of the element, such as text, images, or other media. The content area has a width (the content width) and a height (the content height).
The content area can be controlled using the width and height CSS properties.
The padding area extends the content area by a certain distance.
The padding area can be controlled using the padding CSS property as well as the padding-top, padding-right, padding-bottom, and padding-left CSS properties.
The border area extends the padding area by a certain distance.
The border area can be controlled using the border and border-width CSS properties.
The margin area (bounded by the margin edge) extends the border area by a certain distance.
This is useful if you want to separate an element from its neighbors.
The margin area can be controlled using the margin CSS property as well as the margin-top, margin-right, margin-bottom, and margin-left CSS properties.
The Content Area
To control the content area, you can use the width and height CSS properties.
For example, the following CSS will set the width of the content area to 100 pixels and the height to 50 pixels:
width: 100px;
height: 50px;
Here is how you could use this CSS in your HTML document:
<div style="width: 100px; height: 50px; background: red; color: white;">This is a content area</div>
The Padding Area
To control the padding area, you can use the padding CSS property.
For example, the following CSS will set the padding of the element to 10 pixels:
padding: 10px;
You can also use the padding-top, padding-right, padding-bottom, and padding-left CSS properties to control the padding of the element.
For example, the following CSS will set the padding of the element to 10 pixels on the top, right, bottom, and left:
padding-top: 10px;
padding-right: 20px;
padding-bottom: 30px;
padding-left: 40px;
Alternatively, you can use the padding CSS property to set the padding of the element to 10 pixels on the top, right, bottom, and left:
padding: 10px 20px 30px 40px;
Here is how you could use this CSS in your HTML document:
<div style="padding: 10px 20px 30px 40px; background: red; color: white;"
>This is a padding area</div
>
The Border Area
To control the border area, you can use the border CSS property.
For example, the following CSS will set the border of the element to 10 pixels wide and red:
border: 10px solid red;
You can also use the border-width CSS property to control the width of the border.
For example, the following CSS will set the width of the border to 10 pixels:
border-width: 10px;
You can also use the border-style CSS property to control the style of the border.
For example, the following CSS will set the style of the border to solid:
border-style: solid;
Here is how you could use this CSS in your HTML document:
<div style="border-width: 10px; border-style: solid; border-color: red;">This is a border area</div>
The Margin Area
To control the margin area, you can use the margin CSS property.
For example, the following CSS will set the margin of the element to 10 pixels:
margin: 10px;
You can also use the margin-top, margin-right, margin-bottom, and margin-left CSS properties to control the margin of the element.
For example, the following CSS will set the margin of the element to 10 pixels on the top, right, bottom, and left:
margin-top: 10px;
margin-right: 20px;
margin-bottom: 30px;
margin-left: 40px;
Here is how you could use this CSS in your HTML document:
<div style="margin: 10px 20px 30px 40px; background: red; color: white;">This is a margin area</div>
The Flexbox
Basics
A flexbox is a one-dimensional layout for arranging items in rows or columns. Items expand to fill additional space or shrink to fit into smaller spaces.
To create a flexbox, you need to set the display property of the parent of the elements you want to include in the flexbox to flex:
<div class="parent">
<div class="child">1</div>
<div class="child">2</div>
<div class="child">3</div>
</div>
This causes the parent element to become a flex container and the direct children to become flex items.
.parent {
display: flex;
}
You should also give the elements a border and the children a background color to make it easier to see the layout:
.parent {
border: 1px solid red;
}
.child {
border: 1px solid black;
}
#child-one {
background-color: lightblue;
}
#child-two {
background-color: lightgreen;
}
#child-three {
background-color: lightcoral;
}
The Flex Model
You can influence the direction of the flex items by setting the flex-direction property.
By default, this is set to row, which means the items are laid out horizontally in a row.
You can also set it to column which lays out the items vertically in a column.
Additionally, there are the
row-reverseandcolumn-reversevalues which reverse the order of the items.
To understand what this does, let's first look at the flex model:
The flex model has two axes.
The main axis is the axis running in the direction the flex items are laid out in.
In our current example, the items are laid out horizontally and so the main axis is horizontal. The start and end of the main axis are called the main start and main end. The length from the main-start edge of each item to the main-end edge of each item is the main size.
The cross axis is the axis running perpendicular to the main axis. In our example, the cross axis is vertical. The start and end of the cross axis are called the cross start and cross end. The length from the cross-start edge of each item to the cross-end edge of each item is the cross size.
If we set the flex-direction property to column instead of row, then the main axis will be the vertical axis and the cross axis will be the horizontal axis.
This means that all of the concepts that we will discuss in this section will apply to a column layout as well except with the axes swapped.
Wrapping
If your children are overflowing the container, then you can use the flex-wrap property to wrap the children.
Consider our running example:
<div class="parent">
<div class="child">1</div>
<div class="child">2</div>
<div class="child">3</div>
</div>
.parent {
display: flex;
border: 1px solid red;
}
.child {
border: 1px solid black;
}
#child-one {
background-color: lightblue;
}
#child-two {
background-color: lightgreen;
}
#child-three {
background-color: lightcoral;
}
Let's add a width to the parent and the children:
.parent {
width: 200px;
flex-grow: 0;
flex-shrink: 0;
}
.child {
background-color: gray;
width: 100px;
}
We need to set flex-grow and flex-shrink to 0 to prevent the flexbox from trying to intelligently fit the children into the container (more on this later).
Since we have three children with a width of 100px and the container has a width of 200px, the children are overflowing the container.
You can fix this using the flex-wrap property which basically tells the flexbox to wrap the children to the next line if they don't fit in the current line.
.parent {
flex-wrap: wrap;
}
The wrapping behaviour means that even though the flexbox is technically a one-dimensional layout, you can actually use it to implement two-dimensional layouts as well.
Aligning Items
You can use the justify-content property to control how the positive free space is distributed around your flex items.
.parent {
justify-content: flex-start;
}
This is one of:
flex-start: Items are packed toward the start of the flex containerflex-end: Items are packed toward the end of the flex containercenter: Items are centered in the flex containerspace-between: Items are spread out evenly in the flex container with equal gaps between each pairspace-around: Items are spread out with equal space around each item (i.e. gaps between items are twice the gaps at the ends)space-evenly: Items are spread out with equal space between items and at the ends
You can use the align-items property to control how the items are aligned along the cross axis.
To see what this does, let's add a height to the parent:
.parent {
height: 200px;
}
Now, you can set the align-items property to one of the following values:
stretch: Items are stretched to fill the flex containerflex-start: Items are packed toward the start of the flex containerflex-end: Items are packed toward the end of the flex containercenter: Items are centered in the flex containerbaseline: Items are aligned based on their baselines
If you only want to align a single item, you can use the align-self property, e.g.:
#child-one {
align-self: flex-start;
}
You can also distribute the items along the cross axis using the align-content property.
This will only have an effect if you have flex-wrap: wrap (or wrap-reverse) in your flex container and enough items so that they wrap.
The align-content property takes similar values as the justify-content property.
Gaps
You can set gaps between rows and columns using the gap, column-gap, and row-gap properties:
.parent {
column-gap: 20px;
row-gap: 30px;
}
This allows more granular control over the gaps between rows and columns than the other alignment properties.
Chapter 8: Adding Even More Style with Tailwind CSS
— Ryan Florence
We have already seen how to add some style to our pages using CSS.
However, we won't use CSS directly, but rather Tailwind CSS—a utility-first CSS framework that greatly simplifies the styling process.
Setup
— Kent C. Dodds
Tailwind CSS and PostCSS
Once you've created an app with pnpm create next-app, you're already using Tailwind CSS by default.
If you look at the package.json file, you will notice these dependencies:
tailwindcsspostcssautoprefixer
PostCSS is a special tool for transforming CSS with JavaScript. Autoprefixer is a PostCSS plugin for parsing CSS and adding vendor prefixes to CSS rules.
Both Tailwind CSS and PostCSS require some configuration.
Luckily, pnpm create next-app has already supplied this configuration for us.
You'll find the Tailwind CSS configuration in the tailwind.config.ts file:
import type { Config } from 'tailwindcss';
const config: Config = {
content: [
'./src/pages/**/*.{js,ts,jsx,tsx,mdx}',
'./src/components/**/*.{js,ts,jsx,tsx,mdx}',
'./src/app/**/*.{js,ts,jsx,tsx,mdx}',
],
theme: {
extend: {
backgroundImage: {
'gradient-radial': 'radial-gradient(var(--tw-gradient-stops))',
'gradient-conic': 'conic-gradient(from 180deg at 50% 50%, var(--tw-gradient-stops))',
},
},
},
plugins: [],
};
export default config;
You'll find the PostCSS configuration in the postcss.config.js file:
module.exports = {
plugins: {
tailwindcss: {},
autoprefixer: {},
},
};
Tailwind Directives
The final important file is globals.css.
If you've created your app with pnpm create next-app, this will contain a bunch of unneeded fluff, so let's replace the content of globals.css with these lines:
@tailwind base;
@tailwind components;
@tailwind utilities;
These lines are so-called Tailwind directives.
The @tailwind base directive injects Tailwind's base styles in your CSS.
The @tailwind components injects Tailwind's component classes in your CSS.
Finally, the @tailwind utilities injects Tailwind's utility classes in your CSS.
A Simple Example
Let's try and use Tailwind CSS now.
We'll add a component with a few Tailwind utility classes to page.tsx:
export default function Home() {
return <h1 className="text-3xl font-bold underline">Welcome</h1>;
}
Start the development server and open the homepage. You should see how the styles are applied to the text.
This component highlights the utility-first approach to styling that is behind Tailwind CSS. Instead of writing lots of custom CSS, you style elements by applying pre-existing classes directly in your HTML.
Next, we'll introduce some of the most important utility classes.
Typography Utilities
— Pieter Levels
Font Family
You can change the typeface of your text using the font-family utility classes which include font-sans, font-serif and font-mono.
Consider the following example:
export default function Home() {
return (
<>
<p className="font-sans">This uses a sans-serif font</p>
<p className="font-serif">This uses a serif font</p>
<p className="font-mono">This uses a monospace font</p>
</>
);
}
Font Size
You can change the font size using the text-* utility classes.
Consider the following example:
export default function Home() {
return (
<>
<p className="text-sm">This is a small sentence</p>
<p className="text-base">This is a normal sentence</p>
<p className="text-lg">This is a large sentence</p>
<p className="text-xl">This is an extra large sentence</p>
</>
);
}
You can make your sentences larger than text-xl by prefixing the xl with a number, e.g. text-2xl, text-3xl all the way up text-9xl.
Font Weight
You can change the font weight using the font-* utility classes.
Consider the following example:
export default function Home() {
return (
<>
<p className="font-light">This sentence is light</p>
<p className="font-normal">This sentence is normal</p>
<p className="font-medium">This sentence is medium</p>
<p className="font-semibold">This sentence is semibold</p>
<p className="font-bold">This sentence is bold</p>
</>
);
}
Line Height
You can also set the line height which can be used to control the distance between text lines.
This can be done using the leading-* utility classes.
Consider the following example:
export default function Home() {
return (
<>
<p className="leading-normal">
This is a really, really long sentence that spans multiple lines if you make the window of
your browser small enough. Just keep resizing the browser window until this text spans
multiple lines. Then you will be able to see the effect of line height.
</p>
<p className="leading-relaxed">
This is a really, really long sentence that spans multiple lines if you make the window of
your browser small enough. Just keep resizing the browser window until this text spans
multiple lines. Then you will be able to see the effect of line height.
</p>
<p className="leading-loose">
This is a really, really long sentence that spans multiple lines if you make the window of
your browser small enough. Just keep resizing the browser window until this text spans
multiple lines. Then you will be able to see the effect of line height.
</p>
</>
);
}
You can also control the line height via leading-{num} utility classes (from leading-3 to leading-10).
Alignment
You can also set the text alignment using the text-* utility classes, most notably text-left, text-center and text-right.
Consider the following example:
export default function Home() {
return (
<>
<p className="text-left">This text is left-aligned</p>
<p className="text-center">This text is centered</p>
<p className="text-right">This text is right-aligned</p>
</>
);
}
You can also justify text using the text-justify utility class.
Text Color
You can also set the text color using Tailwind CSS utility classes.
These utility classes usually have the form text-{color}-{number}.
Here, {color} is a string indicating the color of the text (e.g. blue or red).
Additionally, {number} indicates the darkness of the color.
The higher the number, the darker the color will be.
It can be one of the values 100, 200, 300 all the way up to 900.
Consider the following example:
export default function Home() {
return (
<>
<p className="text-blue-300">Light blue</p>
<p className="text-blue-800">Dark blue</p>
<p className="text-red-300">Light red</p>
<p className="text-red-800">Dark red</p>
<p className="text-green-300">Light green</p>
<p className="text-green-800">Dark green</p>
</>
);
}
Font Style and Decoration
There are a few additional interesting utility classes for typography.
For example, font style can be controlled with the italic utility:
export default function Home() {
return <p className="italic">This is an italic sentence</p>;
}
You can also control text decoration with utilities like underline:
export default function Home() {
return <p className="underline">This text is underlined</p>;
}
You can change the text decoration color by using the decoration-{color}-{number} utility classes:
export default function Home() {
return <p className="underline decoration-blue-500">This text has a blue underline</p>;
}
And you can even change the decoration style:
export default function Home() {
return (
<>
<p className="underline decoration-solid">This text has a solid underline</p>
<p className="underline decoration-double">This text has a double underline</p>
<p className="underline decoration-dotted">This text has a dotted underline</p>
<p className="underline decoration-dashed">This text has a dashed underline</p>
<p className="underline decoration-wavy">This text has a wavy underline</p>
</>
);
}
You can also change the decoration thickness using one of the decoration-1, decoration-2, decoration-4 or decoration-8 attributes.
Background Utilities
— Guillermo Rauch
Background Color
You can change the background color of an element using the bg-{color}-{number} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="bg-blue-500">Blue background</div>
<button className="bg-blue-500">Blue button</button>
<p className="bg-blue-500">Blue paragraph</p>
</>
);
}
Linear Gradients
You can give elements a linear gradient background using the bg-gradient-{direction} utilities.
First, you need to specify the direction of the gradient.
For example, you can specify bg-gradient-to-r for "right", bg-gradient-to-t for "top" and more.
Second, you need to specify the starting color via from-{color}-{number} and the end color via to-{color}-{number}.
You can additionally specify a middle color by using via-{color}-{number}.
Here are a few examples on how to use these utilities:
export default function Home() {
return (
<>
<div className="bg-gradient-to-r from-blue-500 to-green-500">
Right direction, blue to green
</div>
<div className="bg-gradient-to-r from-blue-500 via-yellow-500 to-green-500">
Right direction, blue to green, via yellow
</div>
<div className="bg-gradient-to-t from-blue-500 to-green-500">
Top direction, blue to green
</div>
<div className="bg-gradient-to-t from-blue-500 to-green-500 via-yellow-500">
Top direction, blue to green, via yellow
</div>
</>
);
}
Size Utilities
— Ryan Florence
Width
You can give an element a fixed width using the w-{number} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="bg-blue-500 w-24">Text</div>
<div className="bg-blue-500 w-64">Text</div>
<div className="bg-blue-500 w-96">Text</div>
</>
);
}
To actually see that the size utilities work the way we expect, we give all our elements that are present in this section backgrounds. Don't be distracted by this.
Of course, there are many more w-{number} utilities.
You can also give an element a percentage-based width using the w-{fraction} utilities:
export default function Home() {
return (
<div className="flex">
<div className="bg-blue-500 w-1/4">Text</div>
<div className="bg-yellow-500 w-1/4">Text</div>
<div className="bg-green-500 w-1/2">Text</div>
</div>
);
}
You can use w-screen if you want an element to span the entire viewport width.
You can also set the minimum and the maximum width of an element using the min-w-{number} and max-w-{number} attributes.
Height
You can give an element a fixed height using the h-{number} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="bg-blue-500 h-24">Text</div>
<div className="bg-yellow-500 h-64">Text</div>
<div className="bg-green-500 h-96">Text</div>
</>
);
}
Of course, there are many more h-{number} utilities.
You can use h-screen if you want an element to span the entire viewport height.
You can set the minimum and the maximum height of an element using the min-h-{number} and max-h-{number} attributes.
Size
You can set the width and height of an element at the same time using the size-{number} utility classes.
Consider the following example:
export default function Home() {
return (
<>
<div className="bg-blue-500 size-24">Text</div>
<div className="bg-yellow-500 size-64">Text</div>
<div className="bg-green-500 size-96">Text</div>
</>
);
}
Border Utilities
— Bret Hart (wait what?)
Border Color
You can use the border-{color}-{number} to control the border element.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500">Blue border</div>
<div className="border border-green-500">Green border</div>
</>
);
}
Border Width
You can set the border width using the border-{number} utilities:
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500">Text</div>
<div className="border-2 border-blue-500">Text</div>
<div className="border-4 border-blue-500">Text</div>
<div className="border-8 border-blue-500">Text</div>
</>
);
}
Border Style
You can use border-{style} utilities to control the border style of an element.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500 border-solid">Text</div>
<div className="border border-blue-500 border-dashed">Text</div>
<div className="border border-blue-500 border-dotted">Text</div>
<div className="border border-blue-500 border-double">Text</div>
</>
);
}
Border Radius
You can control the border radius by using utilities like rounded, rounded-md, rounded-lg and rounded-full.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500 bg-blue-500 size-32 border-solid rounded">Text</div>
<div className="border border-blue-500 bg-blue-500 size-32 border-solid rounded-md">Text</div>
<div className="border border-blue-500 bg-blue-500 size-32 border-solid rounded-lg">Text</div>
<div className="border border-blue-500 bg-blue-500 size-32 border-solid rounded-full">
Text
</div>
</>
);
}
Spacing Utilities
— Nuno Maduro
Padding
You can control the padding on all sides of an element using the p-{size} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500 size-32 p-2">Text</div>
<div className="border border-blue-500 size-32 p-4">Text</div>
<div className="border border-blue-500 size-32 p-8">Text</div>
</>
);
}
You can control the padding on one side of an element using the p{t | r | b | l}-{size} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500 size-32 pl-4">Left-padded text</div>
<div className="border border-blue-500 size-32 pt-4">Top-padded text</div>
</>
);
}
Margin
You can control the margin on all sides of an element using the m-{size} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500 size-32 m-2">Text</div>
<div className="border border-blue-500 size-32 m-4">Text</div>
<div className="border border-blue-500 size-32 m-8">Text</div>
</>
);
}
You can control the margin on one side of an element using the m{t | r | b | l}-{size} utilities.
Consider the following example:
export default function Home() {
return (
<>
<div className="border border-blue-500 size-32 ml-4">Left margin</div>
<div className="border border-blue-500 size-32 mt-4">Top margin</div>
</>
);
}
Flexbox
— Trey Piepmeier
The flex Utility Class
The "flex" feature enables you to control the layout of elements in a one-dimensional space. You can position the elements either as rows or columns.
Here is a simple example of a flex container with 3 elements that are placed horizontally:
export default function Home() {
return (
<div className="flex">
<div className="size-32 border border-blue-500">First element</div>
<div className="size-32 border border-blue-500">Second element</div>
<div className="size-32 border border-blue-500">Third element</div>
</div>
);
}
You can use the flex-col utility class if you want a vertical layout.
Consider the following example:
export default function Home() {
return (
<div className="flex flex-col">
<div className="size-32 border border-blue-500">First element</div>
<div className="size-32 border border-blue-500">Second element</div>
<div className="size-32 border border-blue-500">Third element</div>
</div>
);
}
Flex Basis
You can use the basis-{size} utilities to set the initial size of flex items.
Consider the following example:
export default function Home() {
return (
<div className="flex">
<div className="border border-blue-500 basis-32">First element</div>
<div className="border border-blue-500 basis-32">Second element</div>
<div className="border border-blue-500 basis-64">Third element</div>
</div>
);
}
You can also specify a fraction like in this example:
export default function Home() {
return (
<div className="flex size-64">
<div className="border border-blue-500 basis-1/4">First element</div>
<div className="border border-blue-500 basis-1/4">Second element</div>
<div className="border border-blue-500 basis-1/2">Third element</div>
</div>
);
}
Flex Wrap
The flex-wrap utility class can be used to control how flex items wrap.
Consider this example:
export default function Home() {
return (
<div className="flex w-64">
<div className="border border-blue-500 w-32">First element</div>
<div className="border border-blue-500 w-32">Second element</div>
<div className="border border-blue-500 w-32">Third element</div>
</div>
);
}
Note that the parent container is too large for the children.
If you want to allow flex items to wrap, you can use flex-wrap:
export default function Home() {
return (
<div className="flex flex-wrap w-64">
<div className="border border-blue-500 w-32">First element</div>
<div className="border border-blue-500 w-32">Second element</div>
<div className="border border-blue-500 w-32">Third element</div>
</div>
);
}
Now the third child element will be placed on the next line.
Grow
You can use the grow utility to tell a flex item to fill all of the available space:
export default function Home() {
return (
<div className="flex w-64">
<div className="border border-blue-500 w-16">First</div>
<div className="border border-blue-500 grow">Second</div>
<div className="border border-blue-500 w-16">Third</div>
</div>
);
}
Space Between
You can control horizontal space between elements using space-x-{amount} utilities.
Consider the following example:
export default function Home() {
return (
<div className="flex space-x-8">
<div className="size-32 bg-blue-500">First element</div>
<div className="size-32 bg-blue-500">Second element</div>
<div className="size-32 bg-blue-500">Third element</div>
</div>
);
}
You can control vertical space between elements using space-y-{amount} utilities.
Consider the following example:
export default function Home() {
return (
<div className="flex flex-col space-y-8">
<div className="size-32 bg-blue-500">First element</div>
<div className="size-32 bg-blue-500">Second element</div>
<div className="size-32 bg-blue-500">Third element</div>
</div>
);
}
Chapter 9: Adding Spice with React
The State Park.
— From "1000 programming dad-jokes"
In this chapter we will create a simple (website) client using React. This client will allow us to add and delete tasks, where each task will have a title and a description.
Let's begin.
React Components
Because they keep getting props.
— From "1000 programming dad-jokes"
Why React Components?
The idea behind React is that you can think about a web page in terms of isolated components, where every component is an independent and reusable piece of the UI.
Consider a potential first version of our easy-opus app, which would need to display a bunch of tasks.
Every task could be its own component containing the task title, description and a button to delete the task. The title, description and the button could in turn be components themselves.
The tasks might then be grouped in a task list component, which in addition to the tasks, should have a button to add a new task.
Here is a simple mockup of the structure of our new web page:
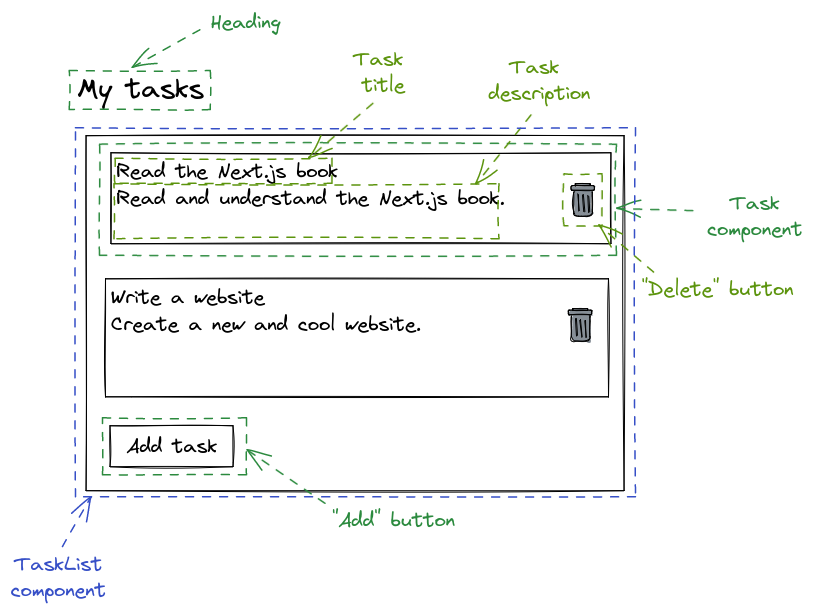
Now comes the interesting part about React. In terms of implementation, a component is just a regular JavaScript function that takes the data it should render as input and returns the UI representation of the data as output.
Here is an example of how the Task component could look like:
function Task({ title, description }: { title: string, description: string }) {
return (
<div>
<p>{title}</p>
<p>{description}</p>
<button>Delete</button>
</div>
);
}
Currently, our components have no styling. We'll fix this in another chapter, for now we just focus on the logic.
Let's have a look at this function.
Looking at its inputs, we see that it takes an object containing the data it should render.
Here the data to be rendered are the title and the description.
Looking at its outputs, we see that it returns the UI representation of the data.
Here the UI representation is a div containing the title, description and a button.
Note that the button currently doesn't do much. We will change this later.
To see components in action, let's actually create a simple React project.
Create a React Project
To create a React project, we will use a tool called Vite, which provides various frontend tooling (including a development server and optimized builds).
First, let's create a new vite project:
pnpm create vite
You will be asked to select various options.
Select React for the framework and TypeScript + SWC for the variant.
After you've created the new project, the tool will even output the commands you should execute afterwards (which is quite helpful).
Now navigate to the newly created directory, where your project resides:
cd example
You will see a couple of familiar files, including a package.json which—among other things—includes the dependencies of the project.
Let's install those dependencies:
pnpm install
Finally, you can run a development server:
pnpm dev
If you go to http://localhost:5173 and look at the result, you will see a web page with some demo content.
Let's replace this demo content with our own components!
First, you can remove App.tsx, App.css, index.css and the assets/ folder.
We will not need these right now.
Replace the code in main.tsx with the following very simple task list:
import ReactDOM from 'react-dom/client';
function App() {
return (
<div>
<h1>Tasks</h1>
<ul>
<li>Read the Next.js book</li>
<li>Write a website</li>
</ul>
</div>
);
}
ReactDOM.createRoot(document.getElementById('root')!).render(<App />);
Save the file and navigate to http://localhost:5173 once more.
You will now see our component.
This is one of the greatest features of the development server—it will automatically recreate the page when you edit your code.
If you've paid attention so far, there should be a giant question mark in your head now: Why are we allowed to write HTML in our JavaScript?
The answer is simple: The syntax is not actually HTML (cue ominous music here).
Introducing JSX
Consider our App function:
function App() {
return (
<div>
<h1>Tasks</h1>
<ul>
<li>Read the Next.js book</li>
<li>Write a website</li>
</ul>
</div>
);
}
While this might look like HTML, it is important to emphasize that this is absolutely not HTML. Instead this syntax is something called JSX, which is a syntax extension to JavaScript that can be transpiled to normal JavaScript.
To be precise, the JSX will be transpiled to calls to the React.createElement function which will return regular JavaScript objects.
The root object will be dynamically added to the DOM using this line of code:
ReactDOM.createRoot(document.getElementById('root')!).render(<App />);
The difference between JSX and HTML is not just a nitpick. For example, in JSX we can (and will) use and nest our own components exactly like we would use and nest HTML elements.
Here is an example of a TaskList component rendered inside the App component:
import ReactDOM from 'react-dom/client';
function App() {
return <TaskList />;
}
function TaskList() {
return (
<div>
<h1>Tasks</h1>
<ul>
<li>Read the Next.js book</li>
<li>Write a website</li>
</ul>
</div>
);
}
ReactDOM.createRoot(document.getElementById('root')!).render(<App />);
While possible, it's much more complicated (and relatively rare) to add your own custom tags in HTML.
Additionally, you can include JavaScript expressions in JSX by wrapping them in curly braces {}.
For example, this is a totally valid React component:
function Example() {
const x = 2;
const y = 2;
return <p>{x + y}</p>;
}
You can't do this in regular HTML.
Add Props to a React Component
JSX is great, but our current TaskList component is not.
The main problem is that the data it represents is hardcoded into the component.
We fix that by passing properties (props) to the component.
This is simply a JavaScript object containing the data the component should render.
In the case of the TaskList we simply want to pass an array of strings named tasks containing our—well—tasks.
We can then use the map function to create a list item li for each element of that array:
type TaskListProps = {
tasks: string[],
};
function TaskList(props: TaskListProps) {
return (
<ul>
{props.tasks.map((task) => (
<li>{task}</li>
))}
</ul>
);
}
This is already not too bad, but of course we want to take advantage of the latest and greatest JavaScript syntax there is.
Writing props.tasks is annoying and will become even more annoying when we have a lot of props.
We can use object destructuring to alleviate this:
function TaskList({ tasks }: TaskListProps) {
return (
<ul>
{tasks.map((item) => (
<li>{item}</li>
))}
</ul>
);
}
You can see how all the concepts from the JavaScript and TypeScript chapters are coming together quite nicely.
Excellent! We can use the new component like this:
function App() {
return (
<div>
<h1>Tasks</h1>
<TaskList tasks={['Read the Next.js book', 'Write a website']} />
</div>
);
}
Note that there is a problem with the current implementation of our component. If you open your browser console, you will see an error:
Warning: Each child in a list should have a unique 'key' prop.
The reason for that is that React needs a way to identify which items in a list have changed or have been added or removed. It does that by looking at the keys of the items. These basically give the elements a stable identity.
Let's add IDs to the tasks and use the task IDs as keys for the component:
function App() {
const tasks = [
{
id: 'TSK-1',
title: 'Read the Next.js book',
},
{
id: 'TSK-2',
title: 'Write a website',
},
];
return (
<div>
<h1>Tasks</h1>
<TaskList tasks={tasks} />
</div>
);
}
function TaskList({ tasks }: TaskListProps) {
return (
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
);
}
There is one final improvement we can make:
The div element in App is pretty useless, since it only serves the purpose of wrapping the h1 and TaskList (since a component can only return a single JSX element).
Luckily, there is a special component called a React fragment which allows us to wrap multiple JSX elements without showing up in the DOM later.
You can create a fragment using the <></> syntax:
function App() {
const tasks = [
{
id: 'TSK-1',
title: 'Read the Next.js book',
},
{
id: 'TSK-2',
title: 'Write a website',
},
];
return (
<>
<h1>Tasks</h1>
<TaskList tasks={tasks} />
</>
);
}
Improving our Project Structure
We should note that it's common practice to put components into separate files (unless two components are heavily related to each other).
In this example, we might put the TaskList component into a file task-list.tsx:
type Task = {
id: string,
title: string,
};
type TaskListProps = {
tasks: Task[],
};
export function TaskList({ tasks }: TaskListProps) {
return (
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
);
}
Note that we have to export the TaskList component so that we can import it in our index.tsx file:
import { TaskList } from 'task-list';
function App() {
const tasks = [
{
id: 'TSK-1',
title: 'Read the Next.js book',
},
{
id: 'TSK-2',
title: 'Write a website',
},
];
return (
<div>
<h1>Tasks</h1>
<TaskList tasks={tasks} />
</div>
);
}
ReactDOM.createRoot(document.getElementById('root')!).render(<App />);
Now, we have two separate files.
The index.tsx file contains our main App component and the task-list.tsx file contains our TaskList component.
Additional components will go into additional files, allowing us to keep our codebase well structured and maintainable.
React State
Because every time it was called, it brought back memories!
— From "1000 programming dad-jokes"
Why State?
In the previous section we've learned how to render components.
However, these components were completely "static". But, in reality, you often need to have "dynamic" components that can change based on some action.
For example, clicking a button might update a counter and typing into a form might update the input field. This means that components need to be able to "remember" things (like the current count or the current input field value).
To "remember" something, you can use state, which serves as a sort of memory for your component.
A Simple Example
Let's create a simple counter component. This component will have a button that increments a value:
import * as React from 'react';
export default function Counter() {
const [count, setCount] = React.useState(0);
return (
<>
<p>{count}</p>
<button
onClick={() => {
setCount(count + 1);
}}
>
Increment
</button>
</>
);
}
Try clicking the "Increment" button—it will increment the count by 1 each time you click it.
This example is simple, but it still shows exactly how to use state in React.
State is provided by the useState hook (a hook is basically just a special function).
This hook returns an array with two elements—a state variable and a state setter function.
The state variable (count in this case) will be the value that you want to remember.
The state setter function (setCount in this case) can be used to update the state variable.
The useState hook takes a single argument—the initial value of the state variable (which is 0 in this case).
Note that we make use of array destructuring here (which you should remember from the JavaScript chapter):
const [count, setCount] = React.useState(0);
Alternatively we could have written:
const countState = React.useState(0);
const count = countState[0];
const setCount = countState[1];
Please don't do that though—it will result in confusion since it's very unconventional to manually destructure the value returned from a hook.
State vs Regular Variables
Why do we need to go through all that pain instead of just using a regular variable?
After all, this is how we've always remembered values before. We simply assigned them to variables.
Let's have a look at why this doesn't work with React:
export default function Counter() {
let count = 0;
return (
<>
<p>{count}</p>
<button
onClick={() => {
count += 1;
}}
>
Increment
</button>
</>
);
}
Try clicking the button now—nothing happens. But why?
The problem lies in the fact that, while we do update the local variable, React doesn't actually rerender the component to show the change.
You can verify this by adding a few console.logs:
export default function Counter() {
let count = 0;
console.log('Rendered counter component');
return (
<>
<p>{count}</p>
<button
onClick={() => {
count += 1;
console.log(`New value of count is ${count}`);
}}
>
Increment
</button>
</>
);
}
If you open the component and click the button a few times, you will see the following logs:
Rendered counter component
New value of count is 1
New value of count is 2
New value of count is 3
So the local variable is indeed updated—but this doesn't rerender the component.
We begin to see the purpose of the useState hook—to define a state whose updates will trigger a rerender.
This explanation should have immediately raised another question. What happens if we skip the state setter function and just set the state variable directly?
export default function Counter() {
let [count, setCount] = React.useState(0);
console.log('Rendered counter component');
return (
<>
<p>{count}</p>
<button
onClick={() => {
count += 1;
console.log(`New value of count is ${count}`);
}}
>
Increment
</button>
</>
);
}
If you click the button a few times, you will see the exact same behaviour as with the previous example:
Rendered counter component
New value of count is 1
New value of count is 2
New value of count is 3
Therefore, if you need to update the UI of your component, you can't use local variables and you can't update the state variables directly. You need to use the state setter function to not only update the state variable, but also to rerender the component.
Let's verify that using the state setter function does what we expect:
export default function Counter() {
let [count, setCount] = React.useState(0);
console.log(`Rendered counter component with count=${count}`);
return (
<>
<p>{count}</p>
<button
onClick={() => {
setCount(count + 1);
console.log(`New value of count is ${count}`);
}}
>
Increment
</button>
</>
);
}
We will now see that the component rerenders if we click the "Increment" button:
Rendered counter component with count=0
New value of count is 0
Rendered counter component with count=1
Note that the value of count only changes on the next render.
Here is what happens:
The component renders for the first time.
Because the initial value of count is set to 0, it will render with count being equal to 0.
You click the button and setCount is called with count + 1 (which will be 0 + 1, i.e. 1).
React rerenders the component while remembering that the new count should be 1.
The component renders for the second time.
Because React remembered that count was set to 1, the component will render with count set to 1.
Using State with a Form
Let's return to our example application and add the form for creating a new task.
Enter the task-list.tsx file and import React at the top:
import * as React from 'react';
Next, we add the form containing inputs for the ID and the title, as well as an "Add task" button below the task list:
export function TaskList({ tasks }: TaskListProps) {
return (
<>
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
<form>
<label htmlFor="taskId">Task ID:</label>
<input type="text" id="taskId" />
<label htmlFor="title">Title:</label>
<input type="text" id="title" />
<br />
<button type="submit">Add task</button>
</form>
</>
);
}
Now, we need to create a handleSubmit function, which will just log something to the console for now.
Remember from the HTML chapter that we need to call the preventDefault function to prevent the default behaviour of a form submission (which includes a page refresh):
function handleSubmit(event) {
event.preventDefault();
const taskId = event.currentTarget.taskId.value.trim();
const title = event.currentTarget.title.value.trim();
console.log(`Submitted ${taskId}, ${title}`);
}
Next, we need to make sure that the handleSubmit function is called when the button is clicked.
To accomplish that, we set the onSubmit property of the form to the handleSubmit function:
<form onSubmit={handleSubmit}>{/*Additional JSX here*/}</form>
If you click the button, you should now see the title logged to the console.
Again, we use the useState hook:
const [tasks, setTasks] = React.useState<Task[]>([]);
We now want to add the task to the end when the form is submitted:
function handleSubmit(event) {
event.preventDefault();
const taskId = event.currentTarget.taskId.value.trim();
const title = event.currentTarget.title.value.trim();
setTasks([
...previousTasks,
{
id: taskId,
title,
},
]);
}
This is how the full code looks like:
import * as React from "react";
type Task = {
id: string;
title: string;
};
export default function TaskList() {
const [tasks, setTasks] = React.useState<Task[]>([]);
function handleSubmit(event) {
event.preventDefault();
const taskId = event.currentTarget.taskId.value.trim();
const title = event.currentTarget.title.value.trim();
setTasks([
...tasks,
{
id: taskId,
title,
},
]);
}
return (
<>
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
<form onSubmit={handleSubmit}>
<label htmlFor="taskId">Task ID:</label>
<input type="text" id="taskId" />
<label htmlFor="title">Title:</label>
<input type="text" id="title" />
<br />
<button type="submit">Add task</button>
</form>
</>
);
}
Try clicking the button—a new task should appear.
Just like with the HTML client the changes will go away if you refresh the page or close the browser. We will talk about how to persist data later.
When to Use State
There is a common theme regarding state in React—a lot of beginners heavily overuse it. This is usually because they misunderstand the purpose of state and what it actually does.
Before we give specific examples of when to and when not to use state, we want to reiterate two things we already discussed:
First, state should only be used if your component needs to remember something.
Second, state updates are expensive, because a state update will rerender your component.
The corollary to these two things is that you should only use state when you absolutely need it, i.e. you should keep state to a minimum.
First, you should never ever store static data in state. For example, this is completely unnecessary:
export default function BadTaskList() {
const tasks = React.useState([
{
id: 'TSK-1',
title: 'Read the Next.js book',
},
{
id: 'TSK-2',
title: 'Write a website',
},
]);
return (
<ul>
{tasks.map((task) => (
<li key={task.id}>{task.summary}</li>
))}
</ul>
);
}
Just use a local variable instead:
export default function GoodTaskList() {
const tasks = [
{
id: 'TSK-1',
title: 'Read the Next.js book',
},
{
id: 'TSK-2',
title: 'Write a website',
},
];
return (
<ul>
{tasks.map((task) => (
<li key={task.id}>{task.summary}</li>
))}
</ul>
);
}
Of course, in this particular example, the
tasksvariable should really be passed as a prop to the component. We just want to show you when to and when not to use state here.
Second, you should never store data in state that you can derive from other state (or props). For example, this is a bad idea:
import * as React from 'react';
type Task = {
id: string;
title: string;
};
export default function TaskList() {
const [tasks, setTasks] = React.useState<Task[]>([]);
const [numTasks, setNumTasks] = React.useState(0);
function handleSubmit(event) {
event.preventDefault();
const taskId = event.currentTarget.taskId.value.trim();
const title = event.currentTarget.title.value.trim();
setTasks([
...tasks,
{
id: taskId,
title,
},
]);
setNumTasks(numTasks + 1);
}
return (
<>
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
<p>You have {numTasks} tasks</p>
<form onSubmit={handleSubmit}>
<label htmlFor="taskId">Task ID:</label>
<input type="text" id="taskId" />
<label htmlFor="title">Title:</label>
<input type="text" id="title" />
<br />
<button type="submit">Add task</button>
</form>
</>
);
}
In this example, you really do need the tasks state (since you need to remember the tasks that have been added so far).
However, you really don't need the numTasks state, because you can derive it from the value of the tasks state.
After all, numTasks is simply equal to tasks.length.
Here is how we can fix the component:
import * as React from "react";
type Task = {
id: string;
title: string;
};
export default function TaskList() {
const [tasks, setTasks] = React.useState<Task[]>([]);
function handleSubmit(event) {
event.preventDefault();
const taskId = event.currentTarget.taskId.value.trim();
const title = event.currentTarget.title.value.trim();
setTasks([
...tasks,
{
id: taskId,
title,
},
]);
}
return (
<>
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
<p>You have {tasks.length} tasks</p>
<form onSubmit={handleSubmit}>
<label htmlFor="taskId">Task ID:</label>
<input type="text" id="taskId" />
<label htmlFor="title">Title:</label>
<input type="text" id="title" />
<br />
<button type="submit">Add task</button>
</form>
</>
);
}
React Effects
Because as soon as something changes, they just have to run and tell everyone!
— From "1000 programming dad-jokes"
Why Effects?
Effects are useful if you want to synchronize React with some external system (like a server).
Consider a component which, upon rendering, needs to fetch a task title and display it to the user. While your first instinct might be to use an event handler together with state, this is not possible. After all, there is no real user event here. Instead, we need to execute something because the component is rendering.
This is where effects come in handy.
The useEffect Hook
Here is the simplest possible example for a useEffect hook.
This hook takes a function which is executed when the component is first rendered or rerendered:
import * as React from 'react';
export default function ExampleComponent() {
React.useEffect(() => {
console.log('Effect runs');
});
return <div>Hello, World!</div>;
}
If you display this component on a page, here is what you will see in the console:
Effect runs
Let's add some state to the component so that we can see what happens when the component rerenders:
import * as React from 'react';
export default function ExampleCounter() {
const [count, setCount] = React.useState(0);
React.useEffect(() => {
console.log(`Effect runs (currently count=${count})`);
});
return (
<>
<p>{count}</p>
<button
onClick={() => {
setCount(count + 1);
}}
>
Increment
</button>
</>
);
}
Open the page containing the component again and you will see the following log:
Effect runs (currently count=0)
Now click the button a few times—you will see that on each rerender the effect is executed:
Effect runs (currently count=1)
Effect runs (currently count=2)
Effect runs (currently count=3)
Effect runs (currently count=4)
Additionally, we can return a cleanup function, which will run when the component is destroyed (unmounted), and before every rerun of the useEffect. We will examine when exactly an effect reruns in the next section.
Consider this example:
import * as React from 'react';
export default function ExampleComponent() {
React.useEffect(() => {
console.log('Effect runs');
return () => {
console.log('Component destroyed');
};
});
return <div>Hello, World!</div>;
}
If the component is destroyed (for example, because you refresh the page or navigate away from the current page), you will see the following log:
Component destroyed
Usually, you would use the cleanup function to do some cleanup (no way). For example, if you've connected to an external system, here is where you would disconnect.
The Dependency Array
The useEffect hook also takes a second argument—a dependency array.
This allows you to specify that the effect should run only if a particular value changes.
Consider this (slightly constructed) example:
import * as React from 'react';
export default function Counter() {
const [firstCount, setFirstCount] = React.useState(0);
const [secondCount, setSecondCount] = React.useState(0);
React.useEffect(() => {
console.log(`Current counts: firstCount=${firstCount}, secondCount=${secondCount}`);
}, [firstCount]);
return (
<div>
<p>{`Current counts: firstCount=${firstCount}, secondCount=${secondCount}`}</p>
<button onClick={() => setFirstCount(firstCount + 1)}>Increment first count</button>
<button onClick={() => setSecondCount(secondCount + 1)}>Increment second count</button>
</div>
);
}
As usual, the effect runs on the initial render:
Current counts: firstCount=0, secondCount=0
If you click the "Increment first count" button, you will see that the effect runs again:
Current counts: firstCount=1, secondCount=0
Current counts: firstCount=2, secondCount=0
Current counts: firstCount=3, secondCount=0
Current counts: firstCount=4, secondCount=0
However, if you click the "Increment second count" button, you will see that the effect doesn't run (and nothing is logged to the console).
This is because firstCount is in the dependency array, but secondCount isn't.
Therefore, an update to firstCount (via the setFirstCount setter function) will trigger the effect.
However, an update to secondCount (via the setSecondCount setter function) will not trigger the effect.
If you want to trigger the effect when secondCount is updated, you will need to add secondCount to the dependency array:
React.useEffect(() => {
console.log(`Current counts: firstCount=${firstCount}, secondCount=${secondCount}`);
}, [firstCount, secondCount]);
Note that if the dependency array is empty, the effect will run only once—when the component is first rendered. This directly follows from the explanation above—an empty dependency array contains no values that would trigger the effect again.
Consider this example:
import * as React from 'react';
export default function Counter() {
const [firstCount, setFirstCount] = React.useState(0);
const [secondCount, setSecondCount] = React.useState(0);
React.useEffect(() => {
console.log(`Current counts: firstCount=${firstCount}, secondCount=${secondCount}`);
}, []);
return (
<div>
<p>{`Current counts: firstCount=${firstCount}, secondCount=${secondCount}`}</p>
<button onClick={() => setFirstCount(firstCount + 1)}>Increment first count</button>
<button onClick={() => setSecondCount(secondCount + 1)}>Increment second count</button>
</div>
);
}
The effect will run on the initial render:
Current counts: firstCount=0, secondCount=0
But it won't run again, no matter how often you click the buttons.
Here is a bonus tip regarding effects: You should always explicitly specify the dependency array.
Remember, if you don't specify the dependency array, the effect will rerun on every render, which is rarely the desired behaviour. In fact this can result in catastrophic behaviour, like in the following example:
export default function ExampleComponent() {
const [count, setCount] = React.useState(0);
React.useEffect(() => {
setCount(count + 1);
});
return (
<div>
<h1>Example Component</h1>
<p>Count: {count}</p>
</div>
);
}
If you run this, you will see that the counter just keeps incrementing in an infinite loop.
This is because the effect calls setCount, which will trigger a rerender, which will trigger the effect again, which will call setCount etc.
React is actually smart enough to realize the problem and will log the following warning to the console:
Maximum update depth exceeded.
This can happen when a component calls setState inside useEffect,
but useEffect either doesn't have a dependency array,
or one of the dependencies changes on every render.
Using fetch and useEffect Together
One of the most common usages of useEffect is to synchronize your component with an external API.
Let's return to our motivation for this section, where we wanted to fetch a task title and display it to the user. Since the task title is held by the API (i.e. an external system), this seems like a perfect use case for an effect:
import * as React from 'react';
export default function ExampleTask() {
const [title, setTitle] = React.useState('');
React.useEffect(() => {
fetch('https://jsonplaceholder.typicode.com/todos/1')
.then((response) => {
if (!response.ok) {
throw new Error(`Response status was ${response.status}`);
}
return response.json();
})
.then((json) => setTitle(json.title))
.catch((error) => console.log(error));
}, []);
return <p>{title}</p>;
}
This code should be pretty clear if you understand the fetch function and the useEffect hook.
Our effect fetches a the task from the API and then sets a state called title after the fetch is completed.
Because we only want this to happen on the initial component render, we specify an empty dependency array.
Note that we don't have a cleanup function in our effect—normally we would abort the request here. However this is out of scope for this introductory book.
You Rarely Need an Effect
Just like with state, beginners tend to heavily overuse effects.
Remember: Effects are only needed if you need to synchronize with an external system. You should not need an effect in any other scenario.
Effects are definitely not needed if you need update some state based on props and other state. Something like this is completely unnecessary:
import * as React from 'react';
type Task = {
id: string;
title: string;
};
export default function TaskList() {
const [tasks, setTasks] = React.useState<Task[]>([]);
const [numTasks, setNumTasks] = React.useState(0);
// This is a really bad idea
React.useEffect(() => {
setNumTasks(tasks.length + 1);
}, [tasks])
function handleSubmit(event) {
event.preventDefault();
const taskId = event.currentTarget.taskId.value.trim();
const title = event.currentTarget.title.value.trim();
setTasks([
...tasks,
{
id: taskId,
title,
},
]);
}
return (
<>
<ul>
{tasks.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
<p>You have {numTasks} tasks</p>
<form onSubmit={handleSubmit}>
<label htmlFor="taskId">Task ID:</label>
<input type="text" id="taskId" />
<label htmlFor="title">Title:</label>
<input type="text" id="title" />
<br />
<button type="submit">Add task</button>
</form>
</>
);
}
Instead, you should simply calculate the depending value during rendering (like we've discussed in the previous section).
Similarly, you don't need effects when you want to reset or adjust some state based on a prop change.
In fact, these days some guidelines recommend to not use an effect even for fetching data. This is because if you fetch data inside an effect in more complex scenarios, you need to think about cleanup functions, race conditions etc. This why most frameworks that build on top of React (like Next.js) usually provide better data fetching mechanisms than fetching data in effects.
Chapter 10: The Project (CSR)
Finally, the first version of the project is upon us.
In this chapter we will create our long awaited easy-opus task management application as a CSR (client-side rendered) application.
TODO: This chapter is work in progress.
Chapter 11: Moving to the Server with Next.js
Because he wanted a full-steak experience.
— From "1000 programming dad-jokes"
Now that you have a rough overview of React, we want to move to the server. Next.js is a React-based framework for building full-stack applications.
We will use Next.js 15, which includes the App Router and React Server Components.
Setup
Installing dependencies. It's like Christmas, every package is a surprise!
— From "1000 programming dad-jokes"
Creating a Next.js Project
In this section, we will setup a clean Next.js project for the following sections.
Let's run the following command to create a new Next.js project:
pnpm create next-app
Give your project a name and select the following options:
- we want to use TypeScript
- we want to use ESLint
- we want to use Tailwind CSS
- we want to use the
src/directory - we want to use the App Router
- we want to use Turbopack for
next dev - we don't want to customize the default import alias
pnpm dev
Note that
pnpm create next-appautomatically runspnpm install, so you don't need to worry about that.
If you go to http://localhost:3000, you will see the default home page.
But where is this home page coming from?
Looking at our new Next.js project, we will see the following layout:
├── package.json
├── pnpm-lock.yaml
├── postcss.config.mjs
├── public
├── README.md
├── src
│ └── app
│ ├── ...
│ ├── layout.tsx
│ └── page.tsx
├── tailwind.config.ts
└── tsconfig.json
Crucially, our code is contained in src/app and our home page is located at src/app/page.tsx.
Let's clean it up a bit.
Simplifying the Default Project
Enter the src/app directory.
First, remove the globals.css file (styles will be the topic of the next chapter).
Next, replace the code in page.tsx with this:
export default function Home() {
return <h1>Welcome</h1>;
}
Finally, replace the code in layout.tsx with this:
export default function RootLayout({ children }: { children: React.ReactNode }) {
return (
<html lang="en">
<body>{children}</body>
</html>
);
}
Go to http://localhost:3000 again and observe the simplified home page.
Pages and Layouts
Because they keep exporting everything.
— From "1000 programming dad-jokes"
Pages
Next.js uses file-based routing. This means that folders are used to define routes and each folder represents a route segment (which maps to a URL segment).
You can define nested routes by nesting folders inside each other.
For example, the folder about would represent the route /about (which would be mapped to the URL /about).
On the other hand, a folder about inside a folder company would represent the route /company/about (which would be mapped to the URL /company/about).
Note that all of this is relative to our root directory (which in our application is src/app).
This means that the route /about would actually be located at src/app/about and the route /company/about would actually be located at src/app/company/about.
Routes can have special files, which are used to actually define the route.
For example, the special page file (which can be e.g. page.js, page.jsx or page.tsx) is used to display the UI for the given route.
For this to work, the page file needs to default export a React component.
We already have a route with a special page file—namely src/app/page.tsx which defines the UI to be displayed for the (root) route /:
export default function Home() {
return <h1>Welcome</h1>;
}
If you go to http://localhost:3000/, you will see the text Welcome, because that's the UI that is defined in the default exported React component.
Let's create another page.
Add a new directory about in src/app and create the following file src/app/about/page.tsx:
export default function About() {
return <h1>About</h1>;
}
Go to http://localhost:3000/about and you will see the text About.
From now on we will stop prefixing everything with
src/appand simply assume that you are always insrc/app. For example, if we tell you to create a filetask/route.tsyou should actually create the file atsrc/app/task/route.ts.
Layouts
A page defines the UI that is unique to a route. You can also define UI that is shared between multiple pages. This is called a layout in Next.js.
You define a layout by default exporting a React component from a layout file (e.g. layout.tsx).
The component should accept a children prop that will be populated with a child layout or a child page.
Let's go to the layout.tsx file in the root directory, which currently looks like this:
export default function RootLayout({ children }: { children: React.ReactNode }) {
return (
<html lang="en">
<body>{children}</body>
</html>
);
}
Let's change it to:
export default function RootLayout({ children }: { children: React.ReactNode }) {
return (
<html lang="en">
<body>
<header>My header</header>
{children}
</body>
</html>
);
}
Now the header "My header" will appear on every page (i.e. both on / and /about).
After you've verified this, you can remove the header again.
Note that the top-most layout (which must always be present) is called the root layout and will be shared across all pages.
The root layout must contain html and body tags.
The root layout is also where you define metadata.
This can be done by exporting a metadata object in the root layout file:
export const metadata: Metadata = {
title: 'Example Application',
description: 'My example application',
};
Navigating with the <Link> Component
You can add navigation between routes by using the <Link> component.
This is a component built on top of the HTML <a> tag that you already know.
However, this component does some additional things, like prefetching (i.e. preloading routes in the background).
It also changes the way navigation works (we will talk more about this in the next sections).
For example, you could add a link to the /about page from the / page by changing the content in page.tsx to this:
import Link from 'next/link';
export default function Home() {
return (
<>
<h1>Welcome</h1>
Go to the <Link href="/about">About</Link> page
</>
);
}
More on Routes
Because they keep exposing endpoints.
— From "1000 programming dad-jokes"
Dynamic Routes
You can use dynamic routes when you don't know segment names ahead of time.
Let's say you want to add a route that displays a task with a certain ID at /task/$ID.
For example, you might wish to display a task with the ID 1 at /task/1 and a task with the ID 2 at /task/2.
Of course, since tasks are added and deleted by the user, you can't know all of the IDs beforehand. This is where dynamic routes come in.
Create a new file task/[id]/page.tsx with the following content:
export default function Task({ params }: { params: { id: string } }) {
return <p>This is a task with ID {params.id}</p>;
}
Here, you pass a params object that contains the id property.
This id property will contain the ID passed in the URL.
For example, if you go to http://localhost:3000/task/1, you should see the following text:
This is a task with ID 1
However, if you go to http://localhost:3000/task/56789, you will see:
This is a task with ID 56789
Note that the [id] notation will only match a single segment.
This means that e.g. http://localhost:3000/task/1/status will not be matched by task/[id] and you will see a 404.
If you want to change this, you can use catch-all segments with [...id] and optional catch-all segments with [[...id]].
Route Handlers
Route handlers basically allow you to create API routes (similar to what we did in the networking chapter).
Route handlers are defined by route files.
Let's create a new file api/task/route.ts and add a simple example route handler:
import { NextResponse } from 'next/server';
export async function GET() {
return NextResponse.json({
taskId: 1,
});
}
You can try accessing the route by using curl:
curl localhost:3000/api/task
This will output the following JSON:
{ "taskId": 1 }
You can access the request by passing a request argument to the function (similar to express):
import { NextRequest, NextResponse } from 'next/server';
export async function GET(request: NextRequest) {
console.log({ request });
return NextResponse.json({
taskId: 1,
});
}
If you look at your console, you will see that the request object is logged.
You can use the request object to access the various request properties.
For example, you could retrieve the cookies of the current request using request.cookies.
This is a special RequestCookies object that exposes methods that you can use to retrieve cookies:
import { NextRequest, NextResponse } from 'next/server';
export async function GET(request: NextRequest) {
const cookies = request.cookies;
const allCookies = cookies.getAll();
const languageCookie = cookies.get('language');
return NextResponse.json({
allCookies,
languageCookie,
});
}
Try accessing the route while passing it a cookie:
curl --cookie "language=de" localhost:3000/api/task
The result will be:
{
"allCookies": [{ "name": "language", "value": "de" }],
"languageCookie": { "name": "language", "value": "de" }
}
Similarly you can access the headers of a request:
import { NextRequest, NextResponse } from 'next/server';
export async function GET(request: NextRequest) {
const headers = request.headers;
const userAgent = headers.get('user-agent');
return NextResponse.json({
headers: Array.from(headers),
userAgent,
});
}
Try accessing the route again:
curl localhost:3000/api/task
This will print the headers that are automatically set by curl:
{
"headers": [
["accept", "*/*"],
["host", "localhost:3000"],
["user-agent", "curl/7.81.0"],
["x-forwarded-for", "::ffff:127.0.0.1"],
["x-forwarded-host", "localhost:3000"],
["x-forwarded-port", "3000"],
["x-forwarded-proto", "http"]
],
"userAgent": "curl/7.81.0"
}
You can have dynamic segments in your route handlers.
Let's create a new file api/task/[id]/route.ts:
import { NextResponse } from 'next/server';
export async function GET(request: Request, { params }: { params: { id: string } }) {
const id = params.id;
return NextResponse.json({
taskId: id,
});
}
Try accessing the dynamic route:
curl localhost:3000/api/task/42
This will return:
{ "taskId": "42" }
You can read query params from the nextUrl.searchParams object:
import { NextResponse, type NextRequest } from 'next/server';
export function GET(request: NextRequest) {
const searchParams = request.nextUrl.searchParams;
const title = searchParams.get('title');
return NextResponse.json({
title,
});
}
Try accessing the route:
curl "localhost:3000/api/task?title=Title&description=Description"
This should return:
{ "title": "Title" }
Server and Client Components
Because it was afraid of hydration errors.
— From "1000 programming dad-jokes"
Rendering
Next.js renders as much as it can on the server. By default, the React components you write are rendered on the server side and the resulting HTML is sent to the browser.
Unfortunately, not all components can be fully rendered on the server. For example, components that require interactivity must be partially rendered on the client.
Therefore, the rendering is split into multiple stages:
First, Next.js renders as much as it can on the server.
Once the initial HTML is rendered, the client-side JavaScript takes over. It reconciles the server-rendered HTML with the client-side React tree.
After the reconciliation, the server-rendered HTML is "hydrated". This stage involves attaching event handlers and setting up necessary state to make the components interactive.
There are several benefits to this approach.
Because the HTML is rendered on the server, you don't get an "empty" HTML page on first load. Instead, you see some HTML content immediately (albeit not interactive), which improves the user experience and helps with SEO.
Server components can also be cached, which means that repeated requests for the same component are served very fast. This can significantly improve performance (especially for content that doesn't change a lot).
Data fetching can be moved from the client to the server which can simplify the code and reduce the amount of data that needs to be sent to the client. This is especially beneficial for clients with slow network speeds.
Additionally, dependencies are now on the server and don't need to be served to the client. This helps greatly with reducing how much the server needs to send to the client.
Server Components
Server components are the components that are completely rendered on the server.
For example, this component is a server component:
import * as React from 'react';
export default function Task() {
return <p>My task</p>;
}
There is no interactivity here, so this component can and will be rendered completely on the server.
Client Components
Client components are components that are rendered both on the server and on the client. You use client components when you need interactivity or you need to use certain browser APIs.
You can opt into client components with "use client".
Consider the following component:
import * as React from 'react';
export default function Counter() {
const [count, setCount] = React.useState(0);
return (
<div>
<p>{count}</p>
<button onClick={() => setCount(count + 1)}>+</button>
</div>
);
}
If you try to go to the corresponding page, you will see an error:
Error: useState only works in Client Components. Add the "use client" directive at the top of the file to use it. Read more: https://nextjs.org/docs/messages/react-client-hook-in-server-component
This is because you can't use useState on the server since you can't store client state there.
To fix the error, we need to add the "use client" directive:
'use client';
import * as React from 'react';
export default function Counter() {
const [count, setCount] = React.useState(0);
return (
<div>
<p>{count}</p>
<button onClick={() => setCount(count + 1)}>+</button>
</div>
);
}
You can verify that this component is rendered both on the server and the client by adding a console.log:
'use client';
import * as React from 'react';
export default function Counter() {
const [count, setCount] = React.useState(0);
console.log('Rendered counter');
return (
<div>
<p>{count}</p>
<button onClick={() => setCount(count + 1)}>+</button>
</div>
);
}
If you go to http://localhost:3000/counter, you will see that the Rendered counter message is output both on the server console as well as on the client console.
That's because the component renders both on the server and on the client.
However, all further interactivity happens only on the client.
For example, if you click the button, you will see that the Rendered counter message is output only on the client console.
However, if you refresh the page, you will observe that the Rendered counter message is again logged both to the server as well as the client.
When to use what?
Use server components if:
- you need to fetch data
- you need to access a database
- you need to keep sensitive information on the server
- you want to keep large dependencies on the server
Use client components only if:
- you need to use event listeners (like
onClick) - you need to use certain React hooks like
useStateoruseEffect - you need to use certain browser functionality (like resizing the browser window)
Chapter 12: The Project (SSR)
Now that we have learned how to use Next.js, we will recreate the easy-opus task management application as a SSR (server-side rendered) application.
Setup
Creating a Next.js Project
First, we need to create a new Next.js Project. Here, we simply follow the steps from the Next.js chapter.
Run the following command to create a new Next.js project:
pnpm create next-app
Give your project the name easy-opus and select the following options:
- we want to use TypeScript
- we want to use ESLint
- we want to use Tailwind CSS
- we want to use the
src/directory - we want to use the App Router
- we want to use Turbopack for
next dev - we don't want to customize the default import alias
Note that from now on we specify all paths relative to the src/app directory.
For example if we refer to a file thingy/example.ts that file will actually be in src/app/thingy/example.ts.
If you're unsure about the location of a file, you can also look at the end of this section, which contains the file tree you should have after the setup is completed.
Removing Unnecessary Code
Let's remove all the unnecessary code from the generated files.
Change the file layout.tsx to look like this:
import type { Metadata } from 'next';
import './globals.css';
import Link from 'next/link';
export const metadata: Metadata = {
title: 'Easy Opus',
description: 'A simple task management application',
};
export default function RootLayout({ children }: { children: React.ReactNode }) {
return (
<html lang="en">
<body>
<nav className="bg-blue-600 bg-opacity-70 text-white p-4 shadow-md flex items-center justify-between">
<div className="flex justify-center w-full">
<Link href="/" className="text-lg font-bold">
easy-opus
</Link>
</div>
</nav>
<>{children}</>
</body>
</html>
);
}
Change the file page.tsx to look like this:
export default function Home() {
return <h1 className="underline">Welcome to easy-opus</h1>;
}
Change the file app/globals.css to look like this:
@tailwind base;
@tailwind components;
@tailwind utilities;
Additionally, feel free to delete the SVG files in the public directory and to change the favicon.ico.
Run pnpm dev and check out the page at http://localhost:3000.
You should see the underlined text Welcome to easy-opus.
Setup a Database
Next we need to setup our database. To accomplish this, we will simply follow the steps from the SQL chapter.
Create a new Supabase project, copy the database URL and create the following .env file:
DATABASE_URL=$YOUR_DATABASE_URL_HERE
Of course, you need to specify the actual database URL you copied from Supabase instead of $YOUR_DATABASE_URL_HERE.
Remember that if your password has special characters like : or /, you will need to replace them with their respective percent-encodings.
Setup Drizzle
Next, we need to set up Drizzle. Here we will simply follow the steps from the Drizzle chapter.
Install drizzle-orm and pg:
pnpm add drizzle-orm pg
pnpm add --save-dev tsx drizzle-kit
Also, install the @types/pg package to get the type definitions for pg:
pnpm add @types/pg --save-dev
Finally, install the drizzle-kit package as a dev dependency:
pnpm add drizzle-kit --save-dev
Create a new directory called db.
This is where our database-related files will go.
You should also create a directory db/migrations where we will store the migrations.
Remember that we specify all paths relative to
src/app, i.e. you need to create thedbdirectory insrc/app.
Create a file db/drizzle.config.ts:
import { defineConfig } from 'drizzle-kit';
export default defineConfig({
out: './src/app/db/migrations',
schema: './src/app/db/schema.ts',
dialect: 'postgresql',
dbCredentials: {
url: process.env.DATABASE_URL!,
},
});
Finally, let's create the initial schema at db/schema.ts:
import { pgTable, serial, text, timestamp } from 'drizzle-orm/pg-core';
export const projectTable = pgTable('project', {
id: serial('id').primaryKey(),
name: text('name').notNull(),
createdAt: timestamp('created_at').defaultNow().notNull(),
});
To simplify migrations, we will add the generate and migrate scripts to package.json:
{
"scripts": {
// other scripts
"db:generate": "pnpm drizzle-kit generate --config=./src/app/db/drizzle.config.ts",
"db:migrate": "pnpm drizzle-kit migrate"
}
}
Now, run pnpm db:generate to generate the migration.
Inspect the migration (which would be something like db/migrations/0000_curious_vanisher.sql) and make sure that it contains the right content:
CREATE TABLE IF NOT EXISTS "project" (
"id" serial PRIMARY KEY NOT NULL,
"name" text NOT NULL,
"created_at" timestamp DEFAULT now() NOT NULL
);
Run pnpm db:migrate to apply the migration to the database.
Verify that your database contains a project table with the right columns.
Finally, we create the db/index.ts file which exports the db object to allow other files to call database functions:
import { drizzle } from 'drizzle-orm/postgres-js';
export const db = drizzle(process.env.DATABASE_URL!);
Yes, this subsection was essentially a repeat of things you've already learned in the Drizzle chapter.
Linting
If you look through the scripts in package.json, you will see a curious little script called lint that executes next lint.
This script provides an integrated ESLint experience. ESLint is an awesome tool that statically analyzes your code to quickly find problems.
Note that ESLint is not for finding syntax or type errors (your TypeScript compiler already takes care of that). Instead it has a lot of rules that help you avoid sketchy code.
Let's run it:
pnpm lint
Unless you messed something up, this should output:
✔ No ESLint warnings or errors
Great! Currently, ESLint has nothing to tell us.
File Structure
This is the file structure you should have right now:
├── .env
├── .eslintrc.json
├── next.config.mjs
├── next-env.d.ts
├── package.json
├── pnpm-lock.yaml
├── postcss.config.js
├── README.md
├── src
│ ├── app
│ │ ├── globals.css
│ │ ├── layout.tsx
│ │ └── page.tsx
│ └── db
│ ├── drizzle.config.ts
│ ├── index.ts
│ ├── migrations
│ │ ├── 0000_curious_vanisher.sql
│ │ └── meta
│ │ ├── 0000_snapshot.json
│ │ └── _journal.json
│ └── schema.ts
├── tailwind.config.ts
└── tsconfig.json
You should absolutely understand each and every one of these files if you've read the book carefully.
Just to recap:
The README.md file contains basic information about the project.
The package.json file marks the directory as a JavaScript project and contains vital project information such as the name, the dependencies and the scripts of this project.
The pnpm-lock.yaml file is automatically generated by the pnpm package manager and contains a complete list of all dependencies (including nested dependencies).
The node_modules contain the actual dependencies.
The tsconfig.json file marks the directory as a TypeScript project and primarily contains important compiler options for the TypeScript compiler.
The next.config.mjs file contains the configuration that is relevant for Next.js.
The next-env.d.ts file ensures that Next.js types are picked up by the TypeScript compiler.
The tailwind.config.ts file contains the configuration that is relevant for Tailwind CSS.
The postcss.config.js file contains the configuration relevant for PostCSS (which is used by Tailwind CSS).
The file src/app/page.tsx specifies the root page and src/app/layout.tsx specifies the root layout.
The globals.css file specifies global styles—right we only really need it for the Tailwind directives.
The src/db directory contains everything that is related to the database (including the migrations).
The .eslintrc.json contain the eslint configuration.
The .env file contains our environment variables.
The Projects Page
Project List
Let's create a component ProjectList in project-list.tsx that will show a nicely styled list of projects:
export function ProjectList({ projects }: { projects: { id: number, name: string }[] }) {
return (
<div className="my-8 mx-auto max-w-2xl">
{projects.map((project) => (
<div className="flex items-center justify-between bg-white p-4 rounded shadow mb-4 hover:shadow transition">
<span className="text-lg font-semibold text-gray-800 hover:text-blue-500 transition">
{project.name}
</span>
</div>
))}
</div>
);
}
Next, we will update the page.tsx file to show the project list.
import { db } from './db';
import { projectTable } from './db/schema';
import { ProjectList } from './project-list';
export default async function Home() {
const projects = await db.select().from(projectTable);
return <ProjectList projects={projects} />;
}
Add a few projects to the database and go to http://localhost:3000.
You should see a project list containing the added projects.
Fixing a Lint
While our project has no syntax errors, no type errors and generally works correctly, there is one issue.
If you read this book carefully so far, you should theoretically be able to figure it out, but it might take a while. Let's use our awesome ESLint tool instead:
pnpm lint
You should see:
./src/app/project-list.tsx
9:9 Error: Missing "key" prop for element in iterator react/jsx-key
Remember that if you want to render a list in React, you should give the individual elements a key prop.
In this case, a good key prop would be the primary key from the database, so let's use that.
Add the key property to the project div in project-list.tsx like this:
<div
key={project.id}
className="flex items-center justify-between bg-white p-4 rounded shadow mb-4 hover:shadow transition"
>
<span className="text-lg font-semibold text-gray-800 hover:text-blue-500 transition">
{project.name}
</span>
</div>
If you rerun pnpm lint, you should see no more errors.
New Project Modal
Let's create a modal that will allow us to add new projects at project-modal.tsx:
"use client";
import * as React from "react";
interface FormElements extends HTMLFormControlsCollection {
name: HTMLInputElement;
}
interface ProjectFormElement extends HTMLFormElement {
readonly elements: FormElements;
}
export function NewProjectModal({
onClose,
onSubmit,
}: {
onClose: () => void;
onSubmit: (name: string) => Promise<void>;
}) {
async function handleSubmit(event: React.FormEvent<ProjectFormElement>) {
event.preventDefault();
const name = event.currentTarget.elements.name.value.trim();
await onSubmit(name);
}
return (
<div className="fixed inset-0 bg-black bg-opacity-50 flex justify-center items-center p-4">
<div className="relative w-full max-w-md bg-white p-6 rounded shadow">
<button
onClick={onClose}
className="absolute top-2 right-2 text-gray-500 hover:text-gray-700"
>
×
</button>
<form onSubmit={handleSubmit} className="space-y-4">
<h2 className="text-lg font-semibold text-gray-800">Add Project</h2>
<div>
<label htmlFor="name" className="text-sm font-medium text-gray-600">
Project Name
</label>
<input
type="text"
id="name"
name="name"
className="mt-1 block w-full px-3 py-2 border rounded focus:border-blue-500 focus:ring focus:ring-blue-200"
/>
</div>
<button
type="submit"
className="w-full py-2 px-4 text-sm font-medium text-white bg-blue-500 rounded hover:bg-blue-600 focus:ring-2 focus:ring-blue-400"
>
Add Project
</button>
</form>
</div>
</div>
);
}
Let's create a file api/project/route.ts with a POST endpoint that allows us to add a new project:
import { db } from '@/app/db';
import { projectTable } from '@/app/db/schema';
import { NextRequest, NextResponse } from 'next/server';
export async function POST(request: NextRequest) {
const { name } = await request.json();
if (!name) {
return NextResponse.json({ error: 'Project name is required' }, { status: 400 });
}
await db.insert(projectTable).values({ name });
return NextResponse.json({ message: 'Project inserted successfully' }, { status: 200 });
}
We need to show the modal in the project list by modifying the project-list.tsx file:
'use client';
import { NewProjectModal } from './project-modal';
import * as React from 'react';
import { useRouter } from 'next/navigation';
export function ProjectList({ projects }: { projects: { id: number, name: string }[] }) {
const router = useRouter();
const [showModal, setShowModal] = React.useState(false);
async function handleNewProject(name: string) {
const response = await fetch('/api/project', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ name }),
});
if (!response.ok) {
throw new Error('Failed to create project');
}
setShowModal(false);
router.refresh();
}
return (
<div className="my-8 mx-auto w-full max-w-2xl">
<button
onClick={() => setShowModal(true)}
className="mb-6 bg-blue-500 text-white font-bold py-2 px-4 rounded hover:bg-blue-600 shadow transition"
>
Add New Project
</button>
{/* Project list here */}
{showModal && (
<NewProjectModal onSubmit={handleNewProject} onClose={() => setShowModal(false)} />
)}
</div>
);
}
Go to http://localhost:3000 and try adding a few projects.
Task Page
Schema Update
We now have a page where we can show the created projects. However, this is not terribly useful as long as we can't add tasks to the projects.
First, we need a place to store the tasks in our database.
Create a new task table in db/schema.ts:
import { sql } from 'drizzle-orm';
import { check, integer, pgEnum /*...*/ } from 'drizzle-orm/pg-core';
// ...
export const statusEnum = pgEnum('status', ['todo', 'inprogress', 'done']);
// Declare the task table
export const taskTable = pgTable(
'task',
{
id: serial('id').primaryKey(),
title: text('title').notNull(),
description: text('description').notNull(),
status: statusEnum().notNull(),
duration: integer('duration'),
createdAt: timestamp('created_at').defaultNow().notNull(),
projectId: integer('project_id')
.notNull()
.references(() => projectTable.id),
},
(table) => [
{
durationCheckConstraint: check('duration_check', sql`${table.duration} > 0`),
},
],
);
Generate the migration:
pnpm db:generate
Review the migration (which might be something like db/migrations/0001_loose_wonder_man.sql):
CREATE TYPE "public"."status" AS ENUM('todo', 'inprogress', 'done');
CREATE TABLE "task" (
"id" serial PRIMARY KEY NOT NULL,
"title" text NOT NULL,
"description" text NOT NULL,
"status" "status" NOT NULL,
"duration" integer,
"created_at" timestamp DEFAULT now() NOT NULL,
"project_id" integer NOT NULL
);
ALTER TABLE "task" ADD CONSTRAINT "task_project_id_project_id_fk" FOREIGN KEY ("project_id") REFERENCES "public"."project"("id") ON DELETE no action ON UPDATE no action;
Execute the migration:
pnpm db:migrate
Check that the task table is present in the database together with the right columns.
Task Page
Now let's create a page containing the tasks of a given project at app/project/[id]/page.tsx:
import { db } from '@/app/db';
import { projectTable, taskTable } from '@/app/db/schema';
import { eq } from 'drizzle-orm';
export default async function Project({ params: { id } }: { params: { id: number } }) {
const tasks = await db.select().from(taskTable).where(eq(taskTable.projectId, id));
return (
<div>
{tasks.map((task) => (
<p key={task.id}>{task.title}</p>
))}
</div>
);
}
Add a few tasks to the project with the ID 1 and go to http://localhost:3000/project/1 - you should see these tasks.
Next, we need to give the user a way to add tasks by themselves.
Task List
Create a TaskList component at app/project/[id]/task-list.tsx:
export function TaskList({
tasks,
}: {
tasks: { id: number, title: string, description: string, status: string }[],
}) {
return (
<div className="my-8 mx-auto max-w-2xl">
{tasks.map((task) => (
<div key={task.id} className="bg-white p-4 rounded shadow mb-4 hover:shadow transition">
<h3 className="text-lg font-semibold text-gray-800 mb-2">{task.title}</h3>
<p className="text-gray-600 mb-2">{task.description}</p>
<p className="text-sm text-blue-500">{task.status}</p>
</div>
))}
</div>
);
}
Use the TaskList in app/project/[id]/page.tsx:
// ...
import { TaskList } from './task-list';
export default async function Project({ params: { id } }: { params: { id: number } }) {
// ...
return <TaskList tasks={tasks} />;
}
New Task Modal
Finally, let's create a modal that will allow us to add new tasks.
Create a file app/project/[id]/task-modal.tsx:
"use client";
interface FormElements extends HTMLFormControlsCollection {
title: HTMLInputElement;
description: HTMLInputElement;
}
interface TaskFormElement extends HTMLFormElement {
readonly elements: FormElements;
}
export function NewTaskModal({
onClose,
onSubmit,
}: {
onClose: () => void;
onSubmit: (title: string, description: string) => Promise<void>;
}) {
async function handleSubmit(event: React.FormEvent<TaskFormElement>) {
event.preventDefault();
const title = event.currentTarget.elements.title.value.trim();
const description = event.currentTarget.elements.description.value.trim();
await onSubmit(title, description);
}
return (
<div className="fixed inset-0 bg-black bg-opacity-50 flex justify-center items-center p-4">
<div className="relative w-full max-w-md bg-white p-6 rounded shadow">
<button
onClick={onClose}
className="absolute top-2 right-2 text-gray-500 hover:text-gray-700"
>
×
</button>
<form onSubmit={handleSubmit} className="space-y-4">
<h2 className="text-lg font-semibold text-gray-800">Add Task</h2>
<div>
<label
htmlFor="title"
className="text-sm font-medium text-gray-600"
>
Title
</label>
<input
type="text"
id="title"
name="title"
className="mt-1 block w-full px-3 py-2 bg-gray-50 rounded border focus:border-blue-500 focus:ring-blue-200"
/>
</div>
<div>
<label
htmlFor="description"
className="text-sm font-medium text-gray-600"
>
Description
</label>
<input
type="text"
id="description"
name="description"
className="mt-1 block w-full px-3 py-2 bg-gray-50 rounded border focus:border-blue-500 focus:ring-blue-200"
/>
</div>
<button
type="submit"
className="w-full py-2 px-4 text-sm font-medium text-white bg-blue-500 rounded hover:bg-blue-600 focus:ring-2 focus:ring-blue-400"
>
Add Task
</button>
</form>
</div>
</div>
);
}
Let's add a new route in task/route.ts:
import { db } from '@/app/db';
import { taskTable } from '@/app/db/schema';
import { NextRequest, NextResponse } from 'next/server';
export async function POST(request: NextRequest) {
const { title, description, status, projectId } = await request.json();
if (!title || !description || !projectId) {
return NextResponse.json(
{ error: 'Task title, description and project ID are required' },
{ status: 400 },
);
}
await db.insert(taskTable).values({ title, description, status: 'inprogress', projectId });
return NextResponse.json({ message: 'Task inserted successfully' }, { status: 200 });
}
Use the new task modal in the app/project/[id]/task-list.tsx file:
'use client';
import { NewTaskModal } from './task-modal';
import * as React from 'react';
import { useRouter } from 'next/navigation';
export function TaskList({
projectId,
tasks,
}: {
projectId: number,
tasks: { id: number, title: string, description: string, status: string }[],
}) {
const [showNewTaskModal, setShowNewTaskModal] = React.useState(false);
const router = useRouter();
async function handleNewTask(title: string, description: string) {
const response = await fetch('/api/task', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ title, description, projectId }),
});
if (!response.ok) {
throw new Error('Failed to create task');
}
setShowNewTaskModal(false);
router.refresh();
}
return (
<div className="my-8 mx-auto w-full max-w-2xl">
<button
onClick={() => setShowNewTaskModal(true)}
className="mb-6 bg-blue-500 text-white font-bold py-2 px-4 rounded hover:bg-blue-600 shadow"
>
Add New Task
</button>
{/* Task list */}
{showNewTaskModal && (
<NewTaskModal onSubmit={handleNewTask} onClose={() => setShowNewTaskModal(false)} />
)}
</div>
);
}
Since the TaskList component takes a projectId prop, we need to update app/project/[id]/page.tsx:
export default async function Project(/* ...*/) {
// ...
return <TaskList projectId={id} tasks={tasks} />;
}
You should now be able to use the "Add new task" button and the modal to add new tasks to the project.
Finally, let's make all the projects on the homepage into links that take you to the respective project pages:
<Link href={`/project/${project.id}`}>
<span className="text-lg font-semibold text-gray-800 hover:text-blue-500 transition">
{project.name}
</span>
</Link>
Don't forget to import the
<Link>component here.
Deployment
Now that we're done writing the first version, let's get our application out into the world. We will use GitHub and Vercel to deploy our application.
Creating a Git Repository
GitHub is a platform that allows developers to upload, store, manage and share their code.
If you look at easy-opus you will see a directory .git and a file .gitignore.
This is because pnpm create next-app has initialized a git repository for you.
Let's update the index with our current content:
git add .
If you run git status you will see the changes to be committed.
To actually commit them, run:
git commit -m "feat: initial commit"
Next, create a new repository on GitHub and push your changes there:
git remote add origin $YOUR_REPOSITORY_URL
git push --set-upstream origin main
Deploying on Vercel
Finally, we will deploy this project on Vercel.
Simply go to vercel.com, create a new project and import the git repository that we've just created.
Next, you need to add the environment variables in the "environment variables" section.
Finally, Vercel will deploy your application and automatically set up a domain for it.
Congratulations, you can now access easy-opus from anywhere in the world!
Note that normally we would also protect our webpage with authentication precisely in order to prevent everyone in the world from making changes to your tasks. However, authentication is out of scope for this book.
More Features
Congratulations, you now have a working minimal task application.
You should try adding more features, most importantly:
- make the status field in the tasks a dropdown that allows you to change the status
- add a button that allows you to delete the tasks
- arrange the tasks in columns by their status
- show the creation date of the tasks in the UI
And more!